能否构建健壮和可靠的测试是UI自动化测试能否成功的关键因素之一。但实际情况是当一个测试接着一个测试执行的时候,常会遇到各种不同的状况。比如脚本去定位元素或去验证程序的运行状态时,有时会发现找不到元素,这可能是由于突然的资源受限或网络延迟等引起响应速度太慢所导致,这时会返回测试失败的结果。so我们需要在测试脚本中引入延时机制,来使脚本的运行速度与程序的响应速度相匹配。即使脚本和程序的响应能够同步。WebDriver为我们提供了隐式等待和显式等待两种机制。下面一一说明下:
隐式等待
隐式等待为WebDriver中的完整一个测试用例或者一组测试的同步,提供了通用的方法。对于解决由于网络延迟或利用Ajax动态加载所导致的程序响应时间不一致是非常有效的。
当设置了隐式等待时间后,WebDriver会在一定时间内持续检测和搜寻DOM,以便于查找一个或多个不立即加载成功可用的元素。一般情况下,隐式等待的默认超时间设置为0。但一旦设置会作用于这个WebDriver实例的整个生命周期或者说一次完整测试的执行期间,并且WebDriver会使其对所有测试步骤中包含的整个页面的元素查找时都有效。
WebDriver提供了implicity_wait()方法来配置超时时间。基于unittest写的测试脚本,常在setUp()方法中加入隐式等待时间并设置为30秒。当测试执行时,WebDriver在找不到一个元素时,将会等待30秒。当达到30秒超时时间后,将抛出一个NoSuchElementException的异常。下面是一个用到隐式等待机制的简单百度搜索测试脚本,代码如下:
import unittest
from selenium import webdriver
class BaiduSearchTest(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(30) #set implicit wait time 30s
self.driver.maximize_window()
#open the baidu page
self.driver.get(‘https://www.baidu.com‘)
def test_search_python(self):
#get the search textbox
search_textbox = self.driver.find_element_by_id(‘kw‘)
search_textbox.clear()
#enter search keyword
search_textbox.send_keys("python")
#get the and seacrh button and click
search_button = self.driver.find_element_by_id(‘su‘)
search_button.click()
#add assert
tag = self.driver.find_element_by_link_text("PyPI").text
self.assertEqual(‘PyPI‘,tag)
def tearDown(self):
#close the browser window
self.driver.quit()
if __name__ == ‘__main__‘:
unittest.main(verbosity=2)
显式等待
显式等待是WebDriver中用于同步测试的另外一种等待机制。显式等待比隐式等待具备更好的操控性。与隐式等待不同,显示等待需要为脚本设置一些预置或者定制化的条件,等待条件满足后再进行下一步测试。
显式等待可以只作用于仅有同步需要的测试用例。WebDriver提供了WebDriverWait类和expected_conditions类来实现显式等待。expected_condition类提供了一些预置条件来作为测试脚本进行下一步测试的判断依据。下面是一个包含显式等待的简单测试脚本,代码如下:
import unittest
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions
class BaitduExplicitWaitTest(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Chrome()
self.driver.get(‘https://www.baidu.com‘)
def test_login_link(self):
WebDriverWait(self.driver, 10).until(lambda s: s.find_element_by_name("tj_login").get_attribute("class") == "lb")
login_link = WebDriverWait(self.driver, 10).until(expected_conditions.element_to_be_clickable((By.LINK_TEXT, "登录")))
login_link.click()
def tearDown(self):
self.driver.quit()
if __name__ == ‘__main__‘:
unittest.main(verbosity=2)
上面脚本先使用python的lambda表达式,并且基于WebDriverWait来实现自定义的预期条件判断。设置显式等待超时时间为10s,直到获取到登录元素并判定其class属性为1b。同时使用element_to_be_clickable方法来判断预期条件是否满足。该条件为等待通过定位器查找的元素可见并可用,这里为登录选项可以点击,直到最大等待时间10s。一旦根据指定的定位器找到了元素,预期条件判定方法会把元素返回给测试脚本以提供给下一步的单击操作。如果在设定的超时时间内,没有通过定位器找到可见可点击的元素,将出抛出TimeoutExpection异常。
下表是expected_conditions类支持的网页浏览器自动化操作时常用到的一些通用等待条件。
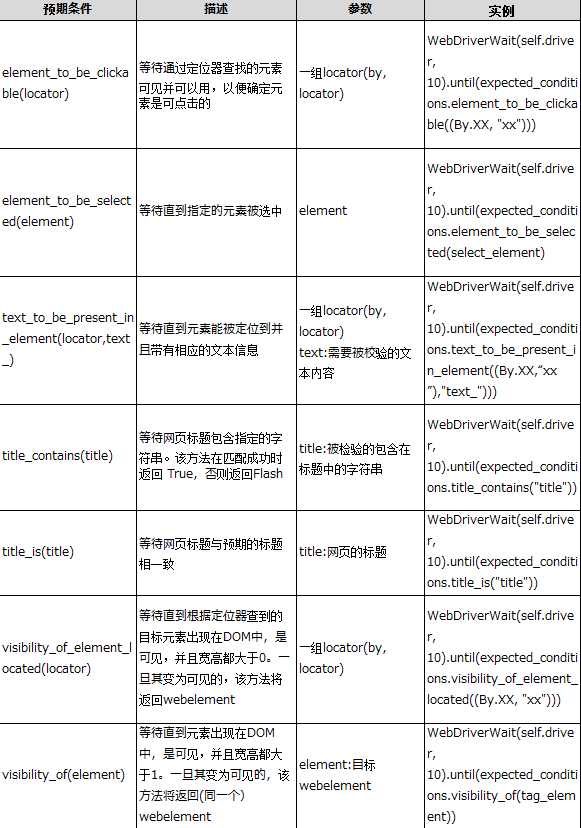
expected_conditions类已经提供了多种内置的预期等待判定条件,我们在实际工作中的可以直接调用。但如果超出了expected_conditions的范围,不用怕,WebDriverWait类也提供了强大的自定义预期等待判定功能。
注意:应尽量避免在测试中隐式等待与显式等待混合使用来处理同步问题。
原文:https://www.cnblogs.com/cnkemi/p/8981957.html