本讲通过几个实例来讲述一下爬取网页的基本操作,同时也复习一下上节课的内容,相信还记得通用的代码框架吧,本讲还需要用到它,哈哈哈,是不能忘记滴。
好了,开始!
第一个实例:
1 ‘‘‘小说爬取‘‘‘ 2 3 import requests 4 5 6 7 def getHTML_Text(url): 8 9 try: 10 11 r = requests.get(url,timeout = 20) 12 13 r.raise_for_status() #如果状态不是200,则产生异常 14 15 r.encoding = r.apparent_encoding 16 17 return r.text 18 19 except: 20 21 return ‘产生异常‘ 22 23 24 25 if __name__ == ‘__main__‘: 26 27 url = ‘http://wanmeishijiexiaoshuo.org/book/9.html‘ 28 29 #上面是某小说网站的其中一章小说内容 30 31 print(getHTML_Text(url)[:5000])
让我们来运行一下看看结果:
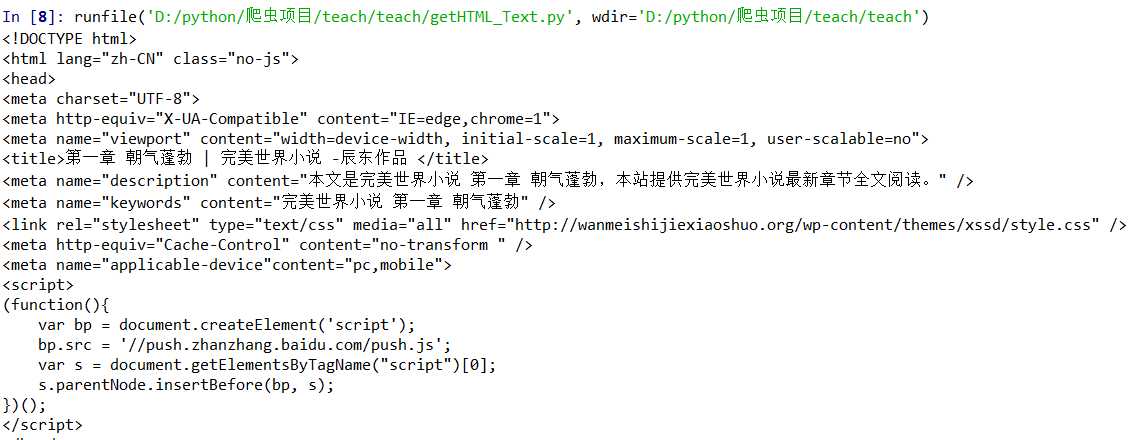

看吧,都是小说的内容,爬下来了吧,懂了操作了吧,简单来说就是输入小说网站的url,然后爬取的框架就能自动爬取下来了。
下面看第二个实例:
1 ‘‘‘亚马逊商场爬取‘‘ 2 3 import requests 4 5 6 7 def getHTML_Text(url): 8 9 try: 10 11 kv = {‘user-agent‘:‘Mozilla/5.0‘} #headers头信息 12 13 r = requests.get(url,timeout = 20,headers = kv) 14 15 r.raise_for_status() #如果状态不是200,则产生异常 16 17 r.encoding = r.apparent_encoding 18 19 return r.text 20 21 except: 22 23 return ‘产生异常‘ 24 25 26 27 if __name__ == ‘__main__‘: 28 29 url = ‘https://www.amazon.cn/‘ 30 31 print(getHTML_Text(url)[:5000])
看看运行结果:
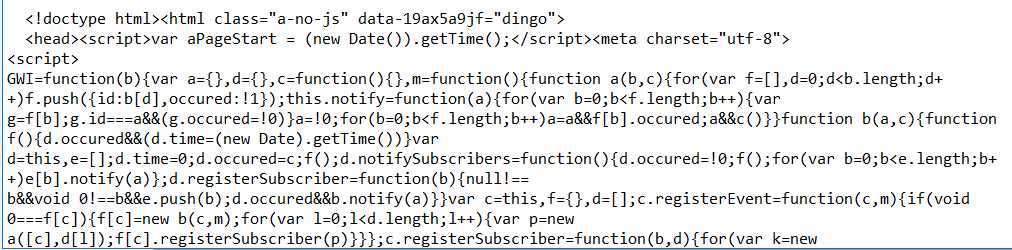
挺乱七八糟的,但是这不是重点,重点是我们获取了全部response的信息,到后面我们会涉及到提取有用的信息,现在先不要着急哈,慢慢来,饭要一口一口吃。
kv = {‘user-agent‘:‘Mozilla/5.0‘} #headers头信息
r = requests.get(url,timeout = 20,headers = kv)
还记得前面提到的get()方法里面的还有几个未提及的参数吗,这里的headers就是其中一个,添加了头信息之后,爬虫会伪装成Mozilla浏览器对目标url发送请求,如果对方服务器是能识别爬虫的,不伪装一下肯能分分钟被拒绝访问,这里我们添加了kv 字典作为头信息,在一定程度上提升了爬虫的能力,哈哈哈,下面看下一个例子。
实例三:
1 ‘‘‘百度搜索‘‘‘ 2 3 import requests 4 5 6 7 def getHTML_Text(url): 8 9 try: 10 11 kv = {‘user-agent‘:‘Mozilla/5.0‘} 12 13 wd = {‘wd‘:‘北京天气‘} 14 15 r = requests.get(url,timeout = 20,params = wd ,headers = kv) 16 17 r.raise_for_status() #如果状态不是200,则产生异常 18 19 r.encoding = r.apparent_encoding 20 21 return r.text 22 23 except: 24 25 return ‘产生异常‘ 26 27 28 29 if __name__ == ‘__main__‘: 30 31 url = "http://www.baidu.com/s?" 32 33 print(getHTML_Text(url)[:5000])
看看运行结果:

我#@¥!@%!@#
冷静一下,再改改:
1 ‘‘‘百度搜索‘‘‘ 2 3 import requests 4 5 6 7 def getHTML_Text(url): 8 9 try: 10 11 wd = {‘wd‘:‘北京天气‘} 12 13 r = requests.get(url,timeout = 20,params = wd) 14 15 r.raise_for_status() #如果状态不是200,则产生异常 16 17 r.encoding = r.apparent_encoding 18 19 return r.text 20 21 except: 22 23 return ‘产生异常‘ 24 25 26 27 if __name__ == ‘__main__‘: 28 29 url = "http://www.baidu.com/s?" 30 31 print(getHTML_Text(url)[:5000])
运行结果:

已经有结果了,原因是那个headers 的参数我们模拟的是Mozilla浏览器,百度的服务器直接拒绝访问了,没事,问题不大,我们注重的是过程,不用这些细节。
好了,经过上面3个实例,相信对requests.get()方法的使用有更深的理解了吧,最后总结一下get()方法的参数。
|
参数名 |
说明 |
|
data |
字典、字节序列或文件对象,作为Request的内容 |
|
json |
JSON格式的数据,作为Request的内容 |
|
headers |
字典,HTTP定制头 |
|
cookies |
字典或CookieJar,Request中的cookie |
|
auth |
元组,支持HTTP认证功能 |
|
timeout |
设定超时时间,秒为单位 |
|
files |
字典类型,传输文件 |
|
proxies |
字典类型,设定访问代理服务器,可以增加登陆认证 |
|
allow_redirects |
True/False,默认位True,重定向开关 |
|
stream |
True/False,默认位True,获取内容立即下载开关 |
|
verify |
True/False,默认位True,认证SSL证书开关 |
|
cert |
本地SSL证书路径 |
这些参数会随着以后的学习逐步深入,本期到此结束。
原文:https://www.cnblogs.com/shuaiqi-XCJ/p/8981975.html