在上一篇文章中,我介绍了《训练自己的haar-like特征分类器并识别物体》的前两个步骤:
1.准备训练样本图片,包括正例及反例样本
2.生成样本描述文件
3.训练样本
4.目标识别
=================
今天我们将着重学习第3步:基于haar特征的adaboost级联分类器的训练。若将本步骤看做一个系统,则输入为正样本的描述文件(.vec)以及负样本的说明文件(.dat);输出为分类器配置参数文件(.xml)。
老规矩,先介绍一下这篇文章需要的工具,分别是(1)训练用的opencv_haartraining.exe,该程序封装了haar特征提取以及adaboost分类器训练过程;(2)haarconv.exe(老版本命名法)或者convert_cascade.exe(新版本命名法),该程序用于合并各级分类器成为最终的xml文件。一般这两个程序都能在opencv的工程文件里找到,请善用ctrl+F。若没有,则请到http://en.pudn.com/downloads204/sourcecode/graph/texture_mapping/detail958471_en.html 中下载opencv_haartraining.exe以及相应dll库,到http://mail.pudn.com/downloads554/sourcecode/graph/detail2285048.html 中下载haarconv.exe以及相应dll库。必备的dll库如下图所示,为了方便你可以将exe以及dll都拷贝出来。目录结构见结尾附图
工具都准备好了,下面进入正题:
1.训练分类器
打开cmd,cd到当前目录,运行命令:
opencv_haartraining.exe -data ./cascade -vec ./pos/sample_pos.vec -bg ./neg/sample_neg.dat -npos 20 -nneg 60 -mem 200 -mode ALL -w 20 -h 20
参数说明,这个要好好看,出错了好调试
-data 指定生成的文件目录, -vec vec文件名, -bg 负样本描述文件名称,也就是负样本的说明文件(.dat) -nstage 20 指定训练层数,推荐15~20,层数越高,耗时越长。 -nsplits 分裂子节点数目,选取默认值 2 -minhitrate 最小命中率,即训练目标准确度。 -maxfalsealarm最大虚警(误检率),每一层训练到这个值小于0.5时训练结束,进入下一层训练, -npos 在每个阶段用来训练的正样本数目, -nneg在每个阶段用来训练的负样本数目 这个值可以设置大于真正的负样本图像数目,程序可以自动从负样本图像中切割出和正样本大小一致的,这个参数一半设置为正样本数目的1~3倍 -w -h样本尺寸,与前面对应 -mem 程序可使用的内存,这个设置为256即可,实际运行时根本就不怎么耗内存,以MB为单位 -mode ALL指定haar特征的种类,BASIC仅仅使用垂直特征,ALL表示使用垂直以及45度旋转特征
-sym或者-nonsym,后面不用跟其他参数,用于指定目标对象是否垂直对称,若你的对象是垂直对称的,比如脸,则垂直对称有利于提高训练速度
其中要注意,负样本使用的是.dat文件,而不是.vec文件。训练结束后会在cascade目录下生成0-N的子目录。训练过程如下图,我的正样本20,负样本60,小试牛刀,毕竟数据量有限。
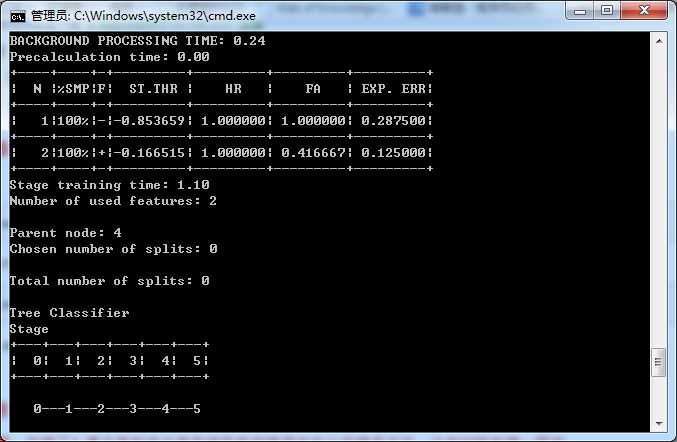
想让自己更强大,就应该知道这张图里面一些参数的意思。
BACKGROUNG PROCESSING TIME 是负样本切割时间,一般会占用很长的时间
N 为训练层数
%SMP 样本占总样本个数
ST.THR 阈值,
HR 击中率,
FA 虚警,只有当每一层训练的FA低于你的命令中声明的maxfalsealarm数值才会进入下一层训练
EXP.ERR 经验错误率
2.合并子分类器生成xml文件
输入命令:
haarconv.exe ./cascade haar_adaboost.xml 25 25
若你使用的是convert_cascade.exe则是另外一种格式:
convert_cascade.exe --size="20x20" ..\cascade haar_adaboost.xml
想知道用法可以输入xxx.exe usage,用法以及参数说明一目了然
3.总结以及注意事项
看起来很简单是不是,你错了!真正做起来会有各种各样的错误发生让你措手不及。以下是我总结的问题及分析:
1)训练时间非常久,少则秒钟,多则几天甚至一礼拜。具体的时间跟你样本的选取、样本数量、机器的性能有着直接联系。举个例子,有人正样本7097负样本2830,在8核3.2Ghz的机器上,开启了多核并行加速(MP)的情况下训练了一周时间,跑到19层。链接http://blog.csdn.net/liulina603/article/details/8197889 。这个真心有点久了,有点夸张。举这个例子是想跟你说明,这是一件耗时间的事情,所以请你耐心等待。
2)卡死在某一层,好像进入死循环。这种情况一般跟样本的选择有关,尤其是负样本。当剩下所有的negtive样本在临时的cascade Classifier中evaluate的结果都是0(也就是拒绝了),随机取样本的数目到几百万都是找不到误检测的neg样本了,因而没法跳出循环!
解决方法是,增大负样本数目,增大负样本之间的变化!
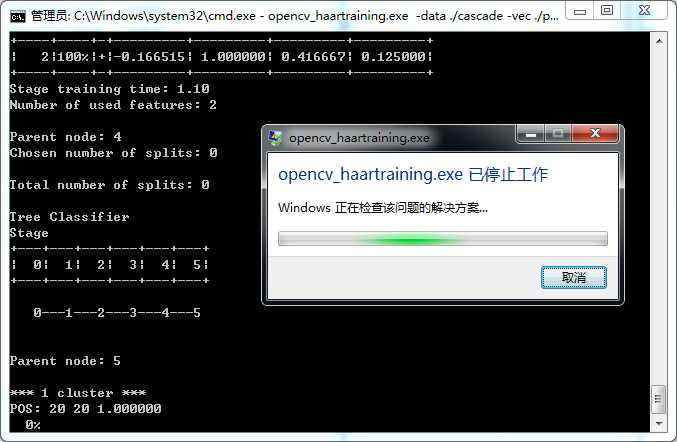
3)训练带某一层出错,报错提示下图。查看cascade目录下发现确实走到第5层。这种情况跟上一种情况其实有点类似,都是opencv_haartraining.exe无法正常terminate。而我们的关注点在于,所生成的这些子分类器能用吗?要依实际情况而定。拿下图来说,在第5层的时候FA已经很低了,0.125000,说明效果已经够用。2)中也是这个道理。
That`s all.
【原】训练自己haar-like特征分类器并识别物体(2),布布扣,bubuko.com
原文:http://www.cnblogs.com/wengzilin/p/3849118.html