1. mapper任务一般执行 输入格式解析、投影(选择相关的字段)、过滤(过滤掉无关记录)。
reducer任务一般
2. 对于map任务和ruduce任务,tasktracker有固定数量的任务槽。
3. 分片(split)的大小一般就是文件块大小。map任务的数量取决于文件大小和块大小,不用刻意去设置。
4. 每个分区(partitioner)对应一个reduce任务,所以partition数目等于作业reducer的个数,输出文件由分区号命名,如:part-00000,part-00001等等。
5. 有些应用程序可能不希望文件被切分(即使文件分为很多块),希望用一个mapper完整处理。方法1:将最小分片大小设置为“大于最大处理文件大小”;方法二:使用FileInputFormat具体子类,并且重载isSplitable()方法,把返回值设置为false.
6. 将若干个小文件打包成顺序文件,要使用到WholeFileInputFormat类。
7. hadoop非常擅长处理非结构化文本数据。
8. hadoop文件是按照字节切分为分片(而不是行),所以每个分片的行数是不一样的。
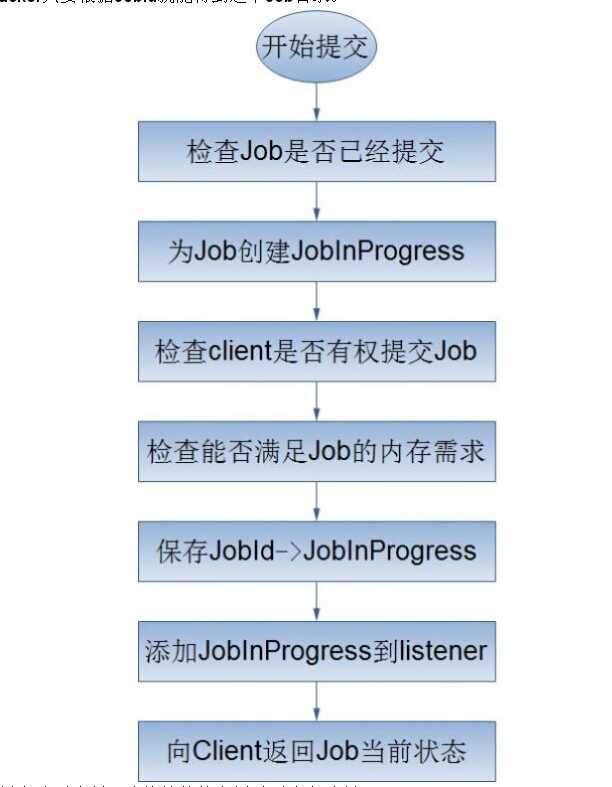
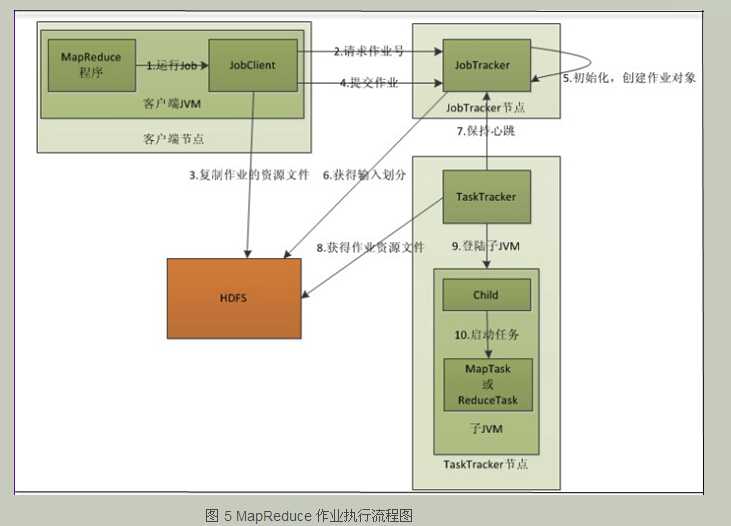
9.Job的提交处理流程:
mapreduce学习总结(一),布布扣,bubuko.com
原文:http://www.cnblogs.com/bigdatacluster/p/3824794.html