map()函数接收两个参数,一个是函数,一个是Iterable,map将传入的函数依次作用到序列的每个元素,并把结果作为新的Iterator返回。
reduce把一个函数作用在一个序列[x1, x2, x3, ...]上,这个函数必须接收两个参数,reduce把结果继续和序列的下一个元素做累积计算。
和map()类似,filter()也接收一个函数和一个序列。和map()不同的是,filter()把传入的函数依次作用于每个元素,然后根据返回值是True还是False决定保留还是丢弃该元素。
def is_palindrome(n):
return n==int(str(n)[::-1])
output = filter(is_palindrome, range(1, 1000))
print(‘1~1000:‘, list(output))
if list(filter(is_palindrome, range(1, 200))) == [1, 2, 3, 4, 5, 6, 7, 8, 9, 11, 22, 33, 44, 55, 66, 77, 88, 99, 101, 111, 121, 131, 141, 151, 161, 171, 181, 191]:
print(‘测试成功!‘)
else:
print(‘测试失败!‘)sorted()函数也是一个高阶函数,它还可以接收一个key函数来实现自定义的排序,例如按绝对值大小排序:
>>> sorted([36, 5, -12, 9, -21], key=abs)
[5, 9, -12, -21, 36]要进行反向排序,不必改动key函数,可以传入第三个参数reverse=True:
***
def count():
fs = []
for i in range(1, 4):
def f():
return i*i
fs.append(f)
return fs
f1, f2, f3 = count()
***
>>> f1()
9
>>> f2()
9
>>> f3()
9原因就在于返回的函数引用了变量i,但它并非立刻执行。等到3个函数都返回时,它们所引用的变量i已经变成了3,因此最终结果为9。
def count():
def f(j):
def g():
return j*j
return g
fs = []
for i in range(1, 4):
fs.append(f(i)) # f(i)立刻被执行,因此i的当前值被传入f()
return fs
***
>>> f1, f2, f3 = count()
>>> f1()
1
>>> f2()
4
>>> f3()
9def createCounter():
i = 0
def counter():
print(i)
i += 1
return i
return counter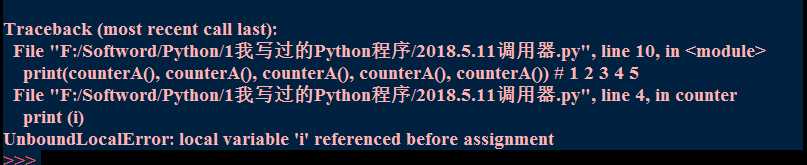
def createCounter():
i = [0]
def counter():
i[0] += 1
return i
return counter
也可以使用生成器
def createCounter():
def num():
n = 1
while 1:
yield n
n = n + 1
n = num()
def counter():
return next(n)
return counter
原文:https://www.cnblogs.com/ulrica/p/9017254.html