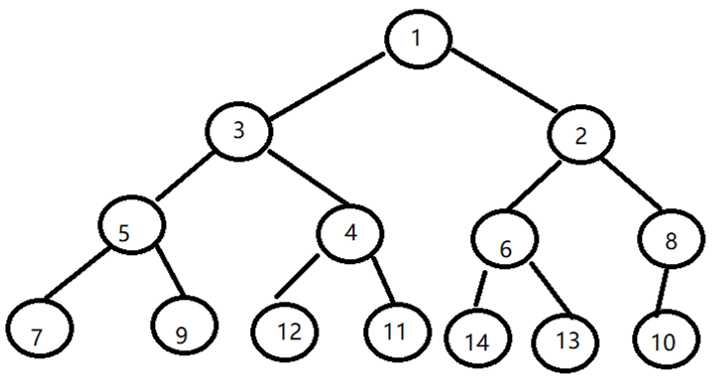
深度优先遍历的结果:[1, 3, 5, 7, 9, 4, 12, 11, 2, 6, 14, 13, 8, 10]
广度优先遍历的结果:[1, 3, 2, 5, 4, 6, 8, 7, 9, 12, 11, 14, 13, 10]
(1)一般来说,重要的网页距离入口站点的距离很近;
(2)广度/宽度优先有利于多爬虫并行进行合作;
(3)可以考虑将深度与广度/宽度相结合的方式来实现抓取的策略:优先考虑广度优先,对深度进行限制最大深度。
(1)设置种子站点、宽度及深度
(2)一个已下载的队列来记录所有已经完成下载的url
(3)实现一个函数,取得当前url的内容以及所有的外链接
(4)递归调用这个函数,来遍历网站
(5)错误日志处理
原文:https://www.cnblogs.com/gengyi/p/9038745.html