直接上sql:方法一:
delete from Route where id in (select b.id from (select * from Route a where id<>(select min(id) from Route where payment_type=0 and point_start=a.point_start and point_end=a.point_end) )b);
问题:一张route表。现在需要删除,payment_type=0 ,并且point_start 和point_end相同的重复数据,示例如下:
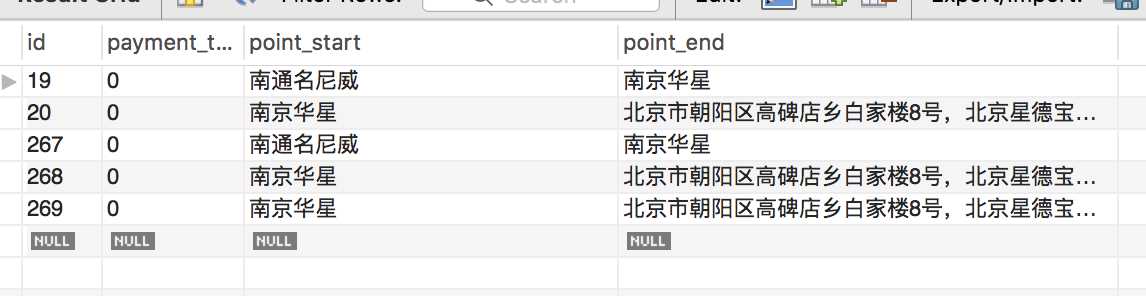
id为19,267的数据重复。20,268,269数据重复。需要保留id为19和20的。其他重复数据删除。
方法二:
delete from Route where id in (select b.id from (select * from Route where (point_start,point_end)in( select point_start,point_end from Route a where payment_type=0 group by point_start,point_end having count(*)>1) and id not in (select min(id) from Route t group by t.point_start,t.point_end having count(*)>1))b);
两种方法都能满足需求。至于性能方面。哪个好,没怎么测。欢迎有兴趣的测试一下,然后告诉我。
原文:https://www.cnblogs.com/clcliangcheng/p/9042710.html