MobileNet (Efficient Convolutional Neural Networks for Mobile Vision Applications)——Google CVPR-2017
MobileNet引入了传统网络中原先采用的group思想,即限制滤波器的卷积计算只针对特定的group中的输入,从而大大降低了卷积计算量,提升了移动端前向计算的速度。
1.1 卷积分解
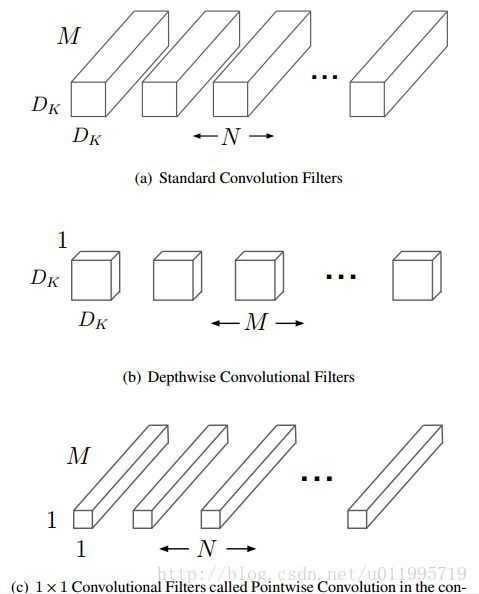
MobileNet借鉴factorized convolution的思想,将普通卷积操作分为两部分:
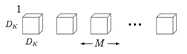
- Depthwise Convolution,即逐通道的卷积,一个卷积核负责一个通道,一个通道只被一个卷积核滤波;其中M是输入通道数,DK是卷积核尺寸,则这里有 M 个 DK*DK 的卷积核;
- Pointwise convolution,将 depth-wise convolution 得到的 feature map 再「串」起来,其实就是:输出的每一个 feature map 要包含输入层所有 feature map 的信息。然而仅采用 depth-wise convolution,是没办法做到这点,因此需要 pointwise convolution 的辅助。
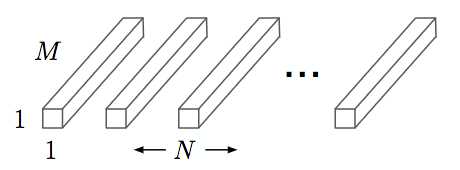
其中输入的 feature map 有 M 个,输出的 feature map 有 N 个。
+Depthwise convolution的计算复杂度为 DKDKMDFDF,其中DF是卷积层输出的特征图的大小。
+Pointwise Convolution的计算复杂度为 MNDFDF
+上面两步合称depthwise separable convolution
+标准卷积操作的计算复杂度为DKDKMNDFDF
因此,通过将标准卷积分解成两层卷积操作,可以计算出理论上的计算效率提升比例:
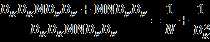
对于3x3尺寸的卷积核来说,depthwise separable convolution在理论上能带来约8~9倍的效率提升。
1.2 模型架构
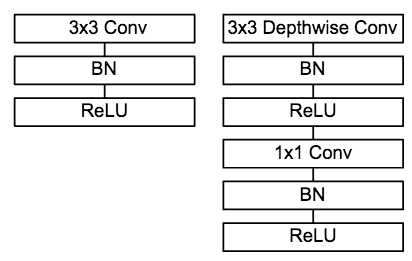
MobileNet的卷积单元如上图所示,每个卷积操作后都接着一个BN操作和ReLU操作。在MobileNet中,由于3x3卷积核只应用在depthwise convolution中,因此95%的计算量都集中在pointwise convolution 中的1x1卷积中。而对于caffe等采用矩阵运算GEMM实现卷积的深度学习框架,1x1卷积无需进行im2col操作,因此可以直接利用矩阵运算加速库进行快速计算,从而提升了计算效率。
小结
- 核心思想是采用 depth-wise convolution 操作,在相同的权值参数数量的情况下,相较于 standard convolution 操作,可以减少数倍的计算量,从而达到提升网络运算速度的目的。
- depth-wise convolution 的思想非首创,借鉴于 2014 年一篇博士论文:《L. Sifre. Rigid-motion scattering for image classification. hD thesis, Ph. D. thesis, 2014》
- 采用 depth-wise convolution 会有一个问题,就是导致信息流通不畅,即输出的 feature map 仅包含输入的 feature map 的一部分,在这里,MobileNet 采用了 point-wise convolution 解决这个问题。在后来,ShuffleNet 采用同样的思想对网络进行改进,只不过把 point-wise convolution 换成了 channel shuffle,然后给网络美其名曰 ShuffleNet,欲知后事如何,请看 2.3 ShuffleNet
MobileNet
原文:https://www.cnblogs.com/CodingML-1122/p/9043078.html