1、网页打开检查器,到达该路径,再刷新网页,点击第一个“Attractions”文件,出现headers(重要)、response、cookies等信息
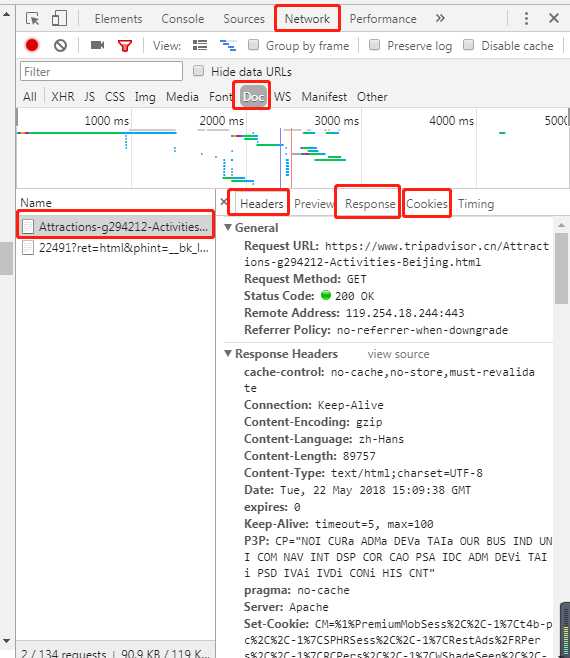
2、定位元素位置方法,找唯一特征:
- 用鼠标右键定位该元素的标签位置,找出这类信息的唯一性属性,最后用“标签+属性”的方式定位该字段信息。如定位图片宽为160大小的信息 imgs = soup.select( ‘img [width="160"]‘ );区分聚合标题与正常标题:titles = soup.select( ‘div.property_title > a[ target="_blank"]‘ )
- 或,在源码中ctrl+F,查看该信息是否唯一
3、某一字段下有多个信息,需要定位在其父级标签,方便进一步筛选信息
4、进一步筛选信息:
- 获取文本:title.get_text()
- 获取图片链接:img.get( ‘src‘ )
- 获取多个文本信息:list( cates.stripped_strings )
5、连续爬多页
- urls = [‘http://...{}...‘ .format(str(i)) for i in range(30,300,30) ]
6、反爬--延时
- import time, time.sleep(2) 延时2S
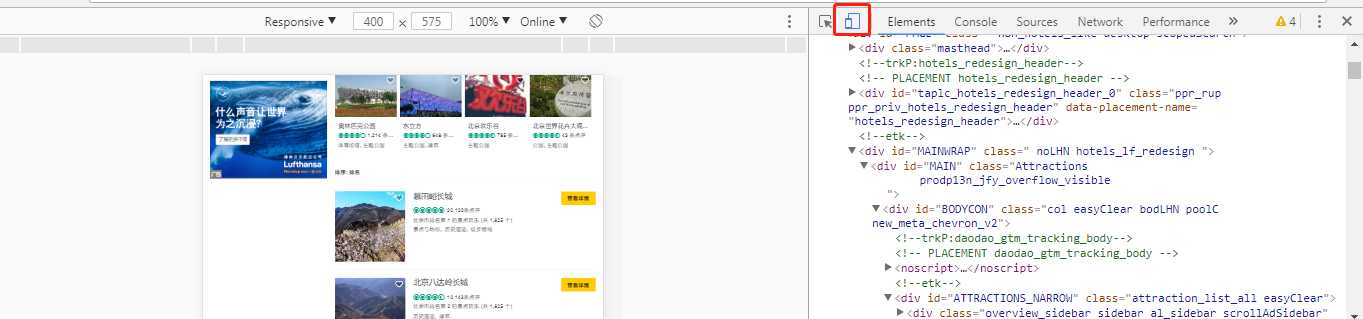
7、反爬--网页切换浏览设备
- 通过模拟手机页面获取信息
- 复制’user_agent‘信息,伪造headers。headers = {‘User-Agent‘ : ‘‘, ‘Cookie‘ : ‘‘ }
- 与上述步骤一致
(完)
网页解析_20180523
原文:https://www.cnblogs.com/szhao0823/p/9074912.html