1.用Hive对爬虫大作业产生的文本文件(或者英文词频统计下载的英文长篇小说)词频统计。
启动hadoop
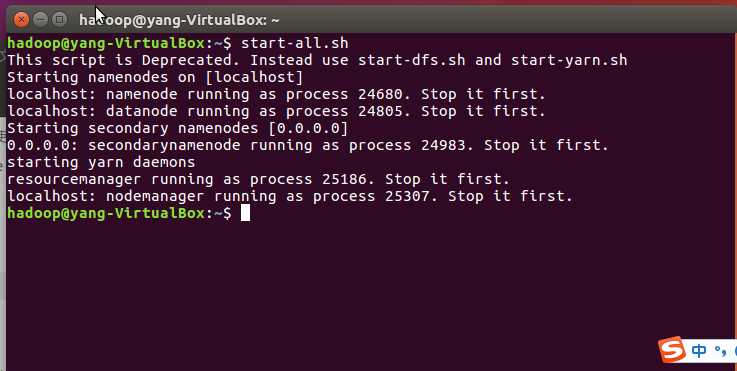
Hdfs上创建文件夹并查看
上传nover.txt文件至hdfs

启动Hive
hive
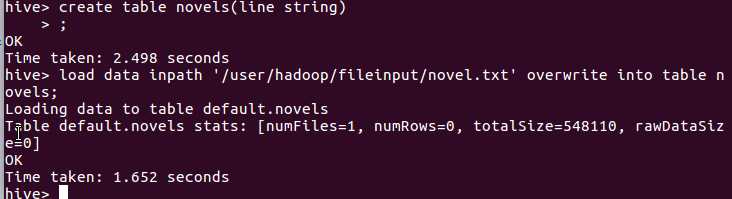
创建原始文档表
create table novels(line string);
导入文件内容到表novels并查看
load data inpath ‘/user/hadoop/fileinput/novel.txt‘ overwrite into table novels; select * from novels;
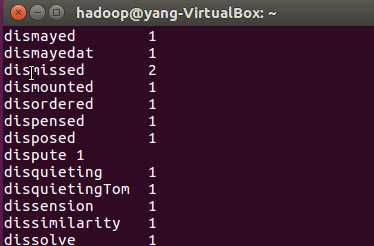
用HQL进行词频统计,结果放在表word_count里
create table word_count as select word,count(1) as count from (se
lect explode(split(line,‘ ‘)) as word from novels) word group by word order by word;
查看统计结果
show tables; select * from word_count;
2.用Hive对爬虫大作业产生的csv文件进行数据分析,写一篇博客描述你的分析过程和分析结果。

# 爬取环球科技网新闻信息 import requests from bs4 import BeautifulSoup from datetime import datetime import jieba import pandas newsurl = ‘http://tech.huanqiu.com/internet/‘ def sort(text): str = ‘‘‘一!“”,。?;’"‘,.、:\n‘‘‘ for s in str: text = text.replace(s, ‘ ‘) wordlist = list(jieba.cut(text)) exclude = {‘这‘, ‘\u3000‘, ‘\r‘, ‘\xa0‘, ‘的‘, ‘_‘, ‘ ‘, ‘将‘, ‘在‘, ‘是‘, ‘了‘, ‘一‘, ‘还‘, ‘也‘, ‘《‘, ‘》‘, ‘(‘, ‘)‘} set2 = set(wordlist) - exclude dict = {} for key in set2: dict[key] = wordlist.count(key) dictlist = list(dict.items()) dictlist.sort(key=lambda x: x[1], reverse=True) print("top5关键词:") for i in range(5): print(dictlist[i]) def getContent(url): res = requests.get(url) res.encoding = ‘utf-8‘ soup2 = BeautifulSoup(res.text, ‘html.parser‘) for news in soup2.select(‘.l_a‘): if len(news.select(‘.author‘))>0: author=news.select(‘.author‘)[0].text print("作者",author) if len(soup2.select(‘.la_con‘))>0: content = soup2.select(‘.la_con‘)[0].text print("正文:", content) sort(content) def getNewDetails(newsurl): pagelist = [] res = requests.get(newsurl) res.encoding = ‘utf-8‘ soup = BeautifulSoup(res.text, ‘html.parser‘) for news in soup.select(‘.item‘): # print(news) newsDict = {} newsDict[‘title‘] = news.select(‘a‘)[0].attrs[‘title‘] href= news.select(‘a‘)[0].attrs[‘href‘] newsDict[‘brief‘] = news.select(‘h5‘)[0].text.rstrip(‘[详细]‘) newsDict[‘time‘] = news.select(‘h6‘)[0].text dt= datetime.strptime(newsDict[‘time‘], ‘%Y-%m-%d %H:%M‘) # print("新闻标题:", title) # print("链接:", a) # print("内容简介:", brief) # print("时间:", dt) pagelist.append(newsDict) getContent(href) print(‘\n‘) pan = pandas.DataFrame(pagelist) pan.to_csv(‘data.csv‘) # break res = requests.get(newsurl) res.encoding = ‘utf-8‘ soup = BeautifulSoup(res.text, ‘html.parser‘) getNewDetails(newsurl) # for total in soup.select(‘#pages‘): # all=int(total.select(‘a‘)[0].text.rstrip(‘条‘)) #获取总条数计算总页数 # #print(all) # if(all%60==0): # totalpages=all//60 # else: # totalpages=all//60+1 # print(totalpages) # for i in range(1,totalpages+1): #所有页面的新闻信息 # PageUrl = newsurl + ‘{}.html‘.format(i) # getNewDetails(PageUrl)
产生的csv文件
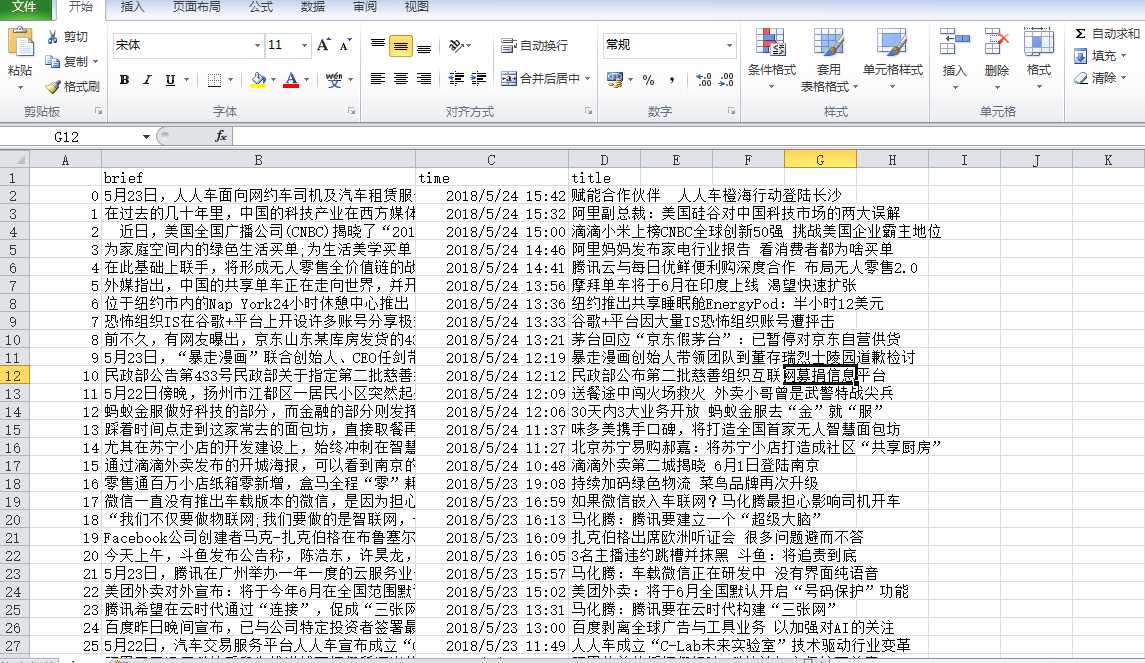
传到虚拟机并查看
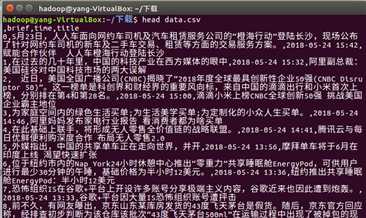
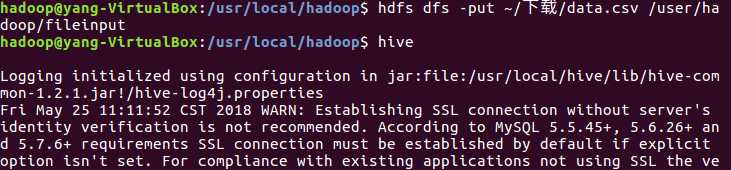
上传到hdfs,启动hive
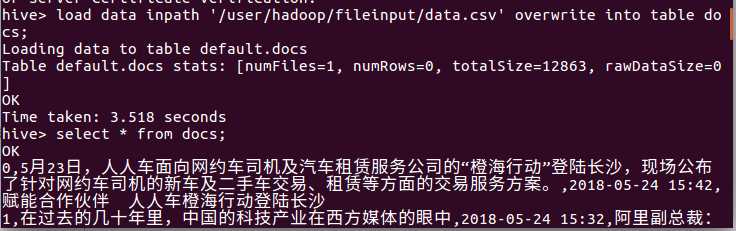
导入数据到docs表并查看
原文:https://www.cnblogs.com/1996-yxl/p/9082603.html
