一、用Hive对爬虫大作业产生的文本文件(或者英文词频统计下载的英文长篇小说)进行词频统计。
1、文本操作
由于我爬的是贴吧的回复,所以爬取出来的内容都是中文的
所以我下要在windows平台先把爬取到的文本进行分词,然后再在虚拟机里进行词频统计
以下是我爬取的文本内容:
分词前:

分词后:

分词所用的python代码:
import string import jieba import jieba.analyse import re f1=open(‘content.txt‘, ‘r‘,encoding=‘utf-8‘).read() f2=open(‘content1.txt‘,‘w+‘,encoding=‘utf-8‘) a=f1.strip().strip("[]‘") line2 = re.sub("[\s+\!\/_,$%^*(+\"\‘]+|[+——!,。??、~@#¥%……&*()]+“”", "",a) tags = jieba.cut(line2) tagsw = " ".join(tags) f2.write(tagsw) f2.close
2、虚拟机操作
先启动mysql服务和hadoop服务:
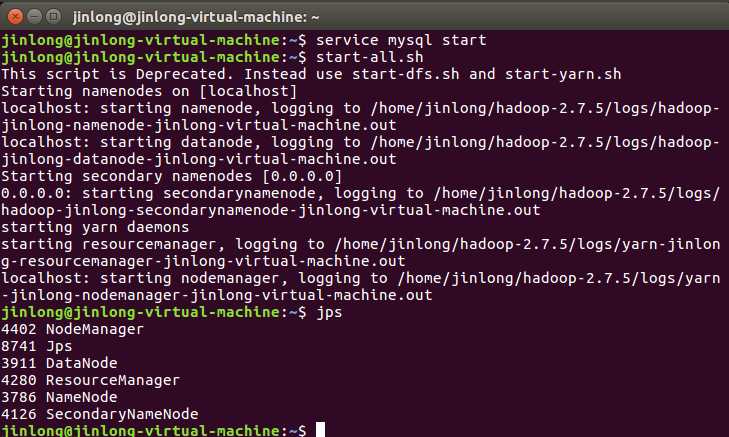
因为我用的虚拟机是VM,所以我可以直接把文本文件content1.txt拖曳进虚拟机
此次我将其拖入到home目录下
将其复制到HDFS的/user/jinlong/input目录下

进入HIVE:
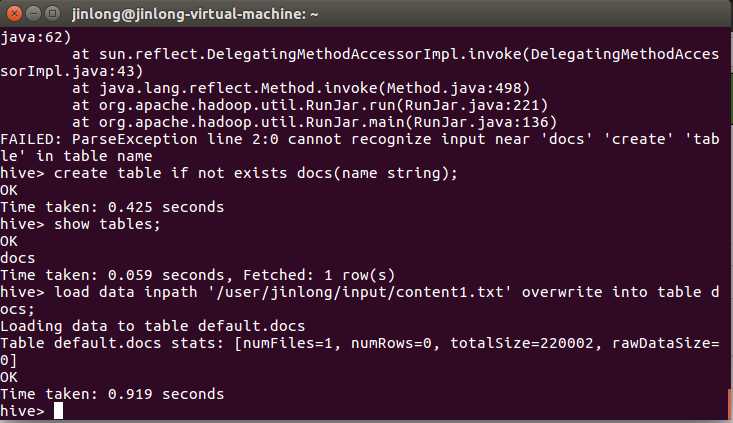
创建select_table表,并将content1.txt的数据存入:
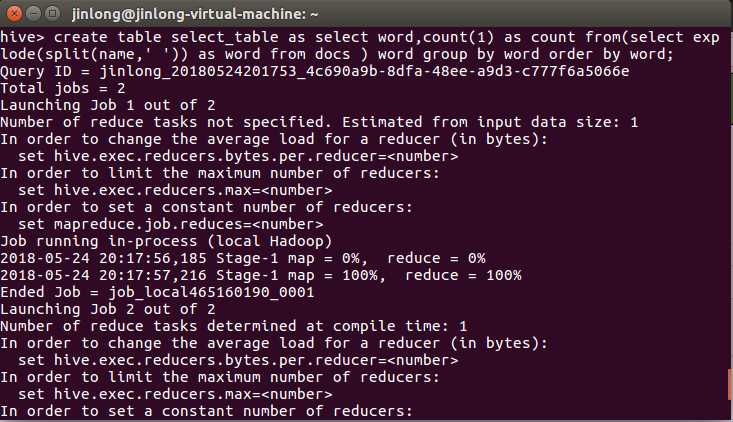
看一下表:
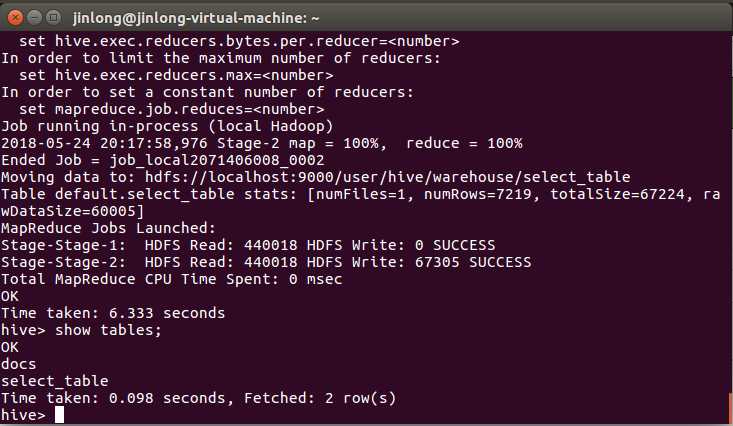
结果:
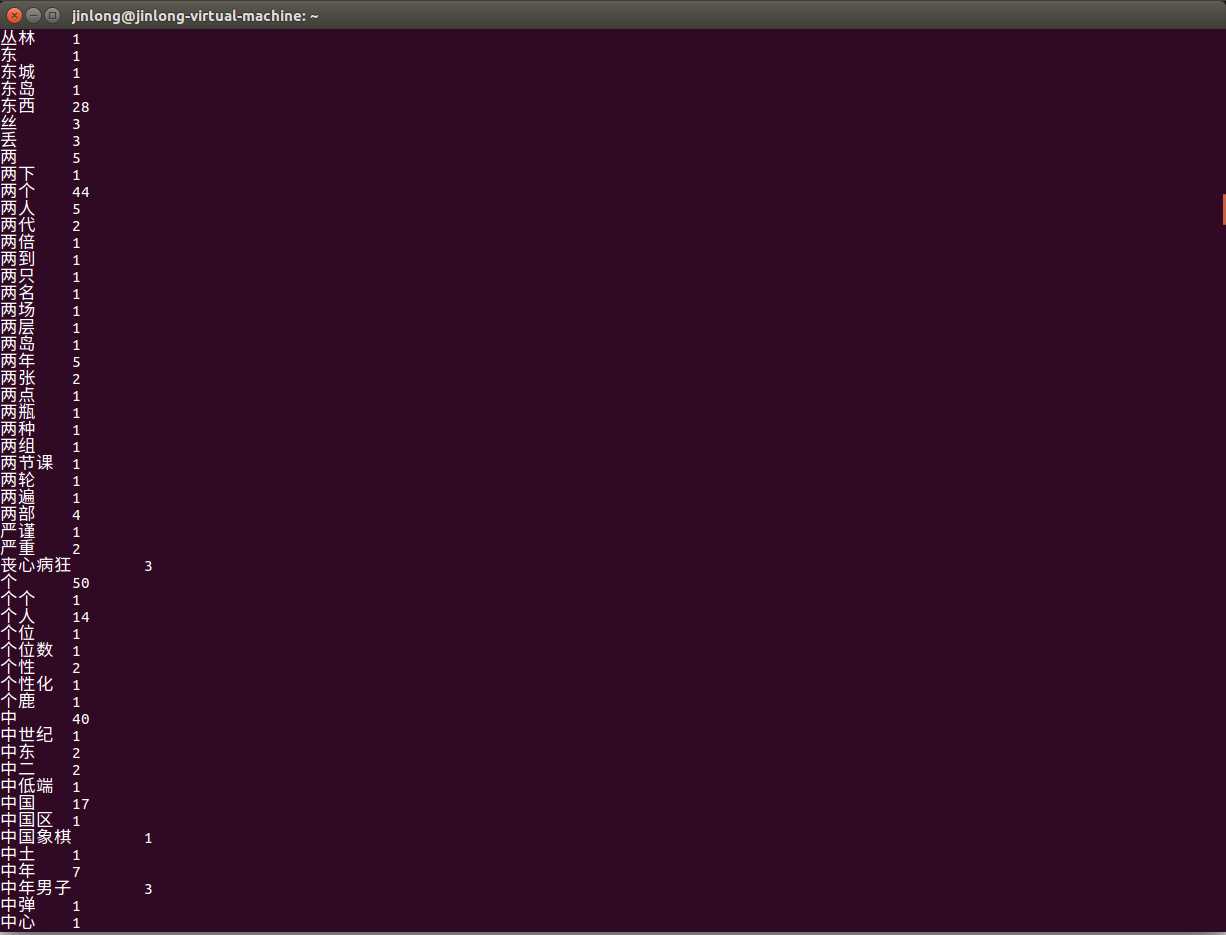
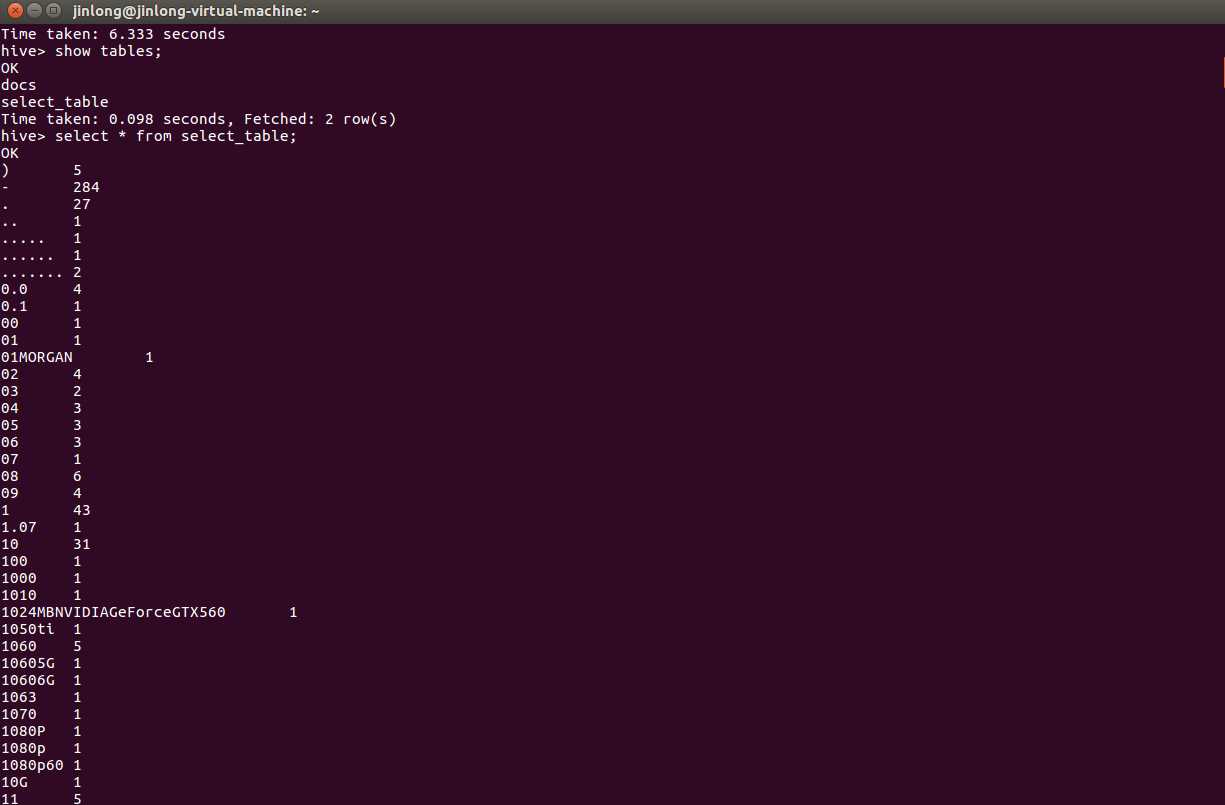
说明:由于我爬的是贴吧的回复,所以尽管我已经删掉了一些不必要的标点符号,但是由于有一些标点符号、数字和英文是出现在硬件版本号、软件版本号等名称中,必须保留的,所以content1.txt中还存在大量标点符号、数字、和英文,因此前几十行都被标点符号、数字、和英文所霸占。。。。
二、用Hive对爬虫大作业产生的csv文件进行数据分析,写一篇博客描述你的分析过程和分析结果。
1、文本处理:
在爬取上文content1.txt的同时,我还将回复人的ID,回复时间一起爬取了下来,并将这3类数据都存放进表单文件AllPagingDetail.csv中。
如下图:

将AllPagingDetail.csv文件同样拖曳到虚拟机的home目录下:
查看一下该文件:
将该文件存放到HDFS的/user/jinlong/input下:

创建tableprocesse表:

直接将AllPagingDetail.csv导入到tableprocesse表中:

出事了。。。。
直接导入CSV文件会出现格式问题,只能将csv文件格式化一番,在导入到表中。。。。。
在我鼓捣了一番,又是直接在wps中将csv直接转成txt文件,又是通过脚本将csv文件转成txt文件,结果都出现格式问题
最后,我不得不怀疑起是不是爬取的时候将某些数据的不必要的格式也爬取了下来。
所以我对我的爬虫进行了一番DEBUG,结果发现:

果然是爬取的时候,爬取的用户名ID左右两边都有"\n"。
将“\n”去掉:
ReplyItems1a=i.select(".d_name")[0].text ReplyItems1["ID"]=ReplyItems1a.strip("\n")
重新将爬取的数据拿到LINUX中进行处理:
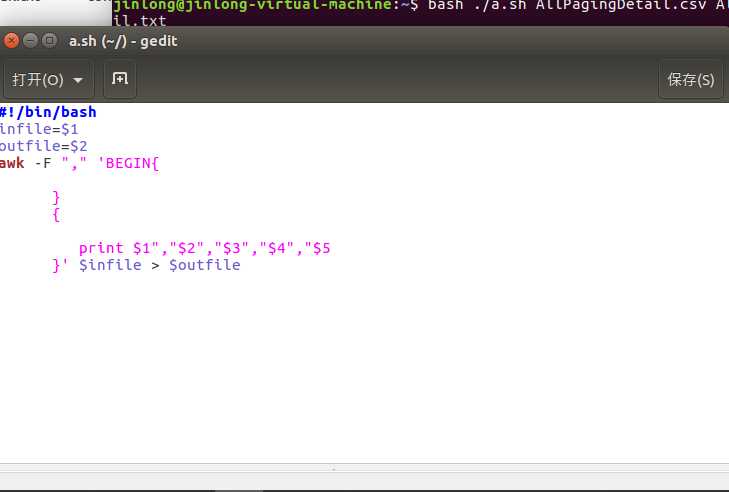
将csv文件用脚本转换成txt文件:

脚本文件如下:
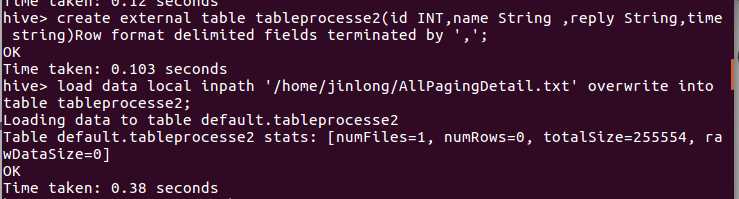
创建表tableprocesse2,并将生成的txt文件导入到该表:
看一下表中数据:

分析:
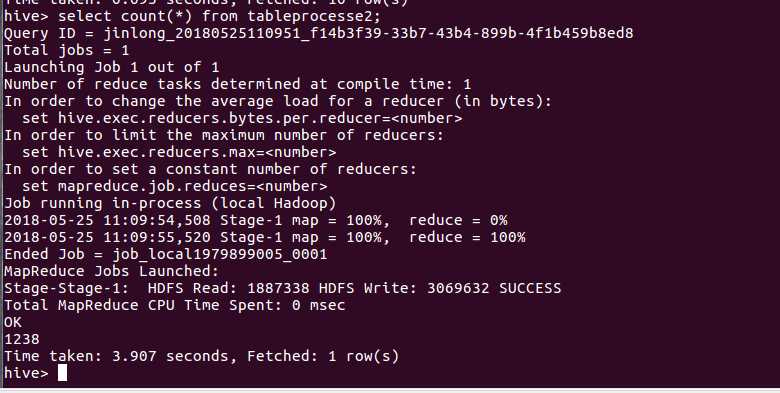
查询数据有多少条数:
不重复的id有多少条:
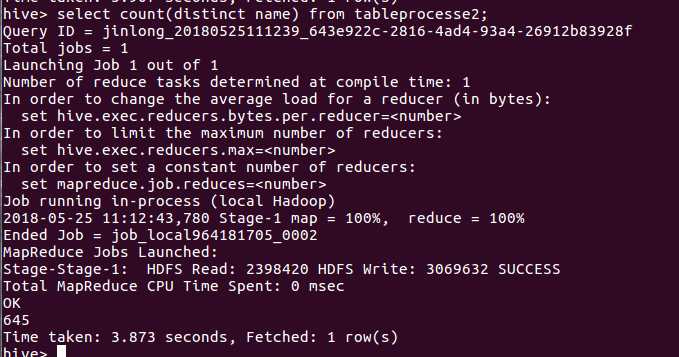
通过这次数据分析,我发现要将数据导入hive进行分析最重要的就是在导入前对数据进行格式化,不然导入后会出现数据排版错误等问题,会导致这些数据没有分析的价值
原文:https://www.cnblogs.com/wban48/p/9086003.html