1.用Hive对爬虫大作业产生的文本文件(或者英文词频统计下载的英文长篇小说)进行词频统计。
先启动Hadoop。

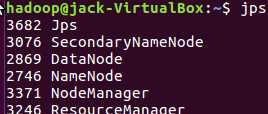
jps查看各个服务已启动
把本地文件上传到hdfs文件系统

建个表text

把hdfs文件系统中input文件夹里的文本文件load进去,写hiveQL命令统计

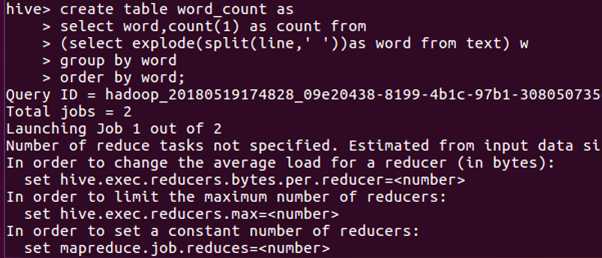
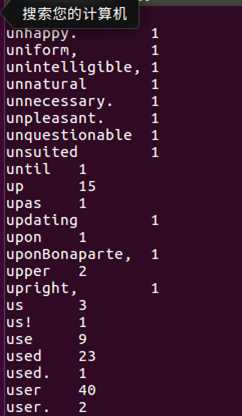
使用select命令查看结果
2.用Hive对爬虫大作业产生的csv文件进行数据分析,写一篇博客描述你的分析过程和分析结果。
我选择用之前校园网爬取的数据导出成csv格式
然后将这个csv复制黏贴到当地的local/bigdatacase/dataset下,然后新建一个pre_deal.sh然后再让它俩生成一个txt
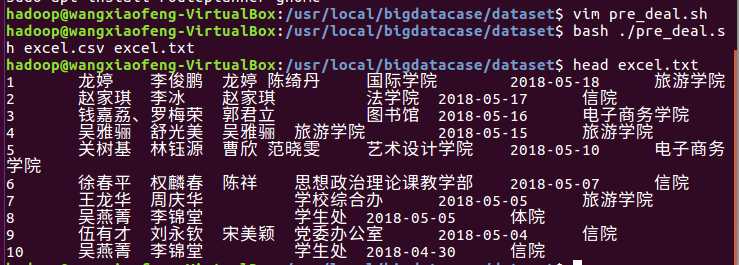
接着就是就是将它上传到hdfs 的hadoop/biddata/dataset中。然后在创建一个database,外键表将这个txt的数据填到表里面。
因为时间处理得不好,类型不是date,所以标示的是null。
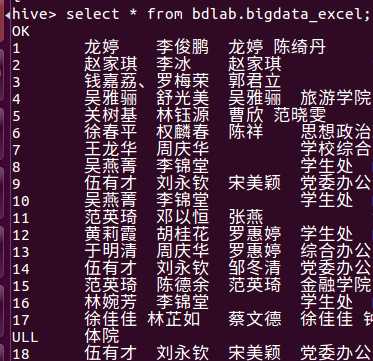
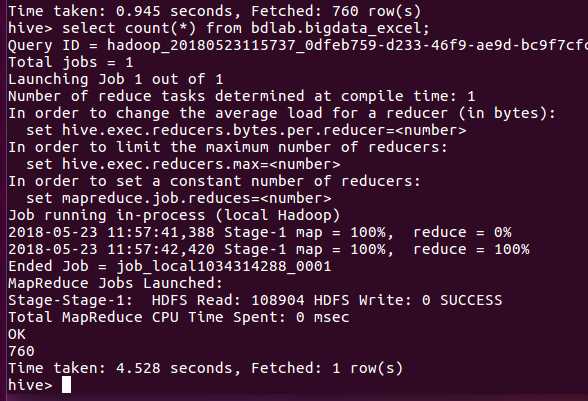
没有时间不能做出其他更好的数据分析,于是我分析了多少条数据。
结果是760条。
原文:https://www.cnblogs.com/whr7116365/p/9084804.html