1.用Hive对爬虫大作业产生的文本文件(或者英文词频统计下载的英文长篇小说)进行词频统计。
启动hadoop
Hdfs上创建文件夹
data 为名字

上传文件至hdfs
启动Hive
创建原始文档表

导入文件内容到表docs并查看
导入

查看

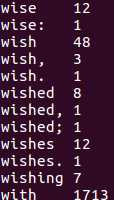
用HQL进行词频统计,结果放在表word_count里

查看统计结果

结果有3万多行

所以只截图其中几行来当例子
2.用Hive对爬虫大作业产生的csv文件进行数据分析,写一篇博客描述你的分析过程和分析结果。
这里我是按照小说名字和小说月票数排序保存的novel.csv
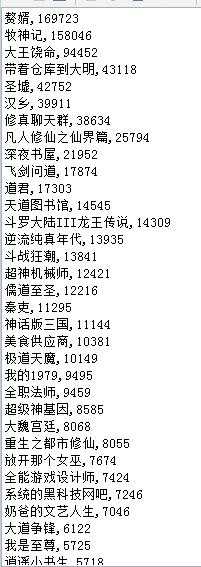
将novel.csv上传到dfs,这里我使用的是winscp上传到虚拟机的。
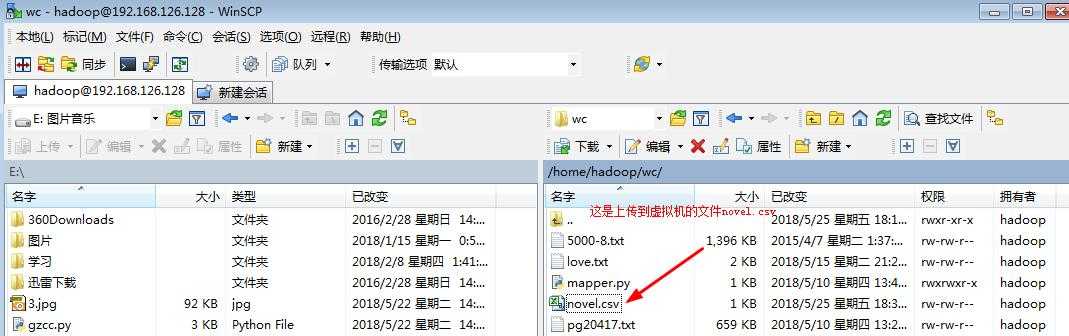
上传到dfs

启动hive

创建novellist表存储novel.csv的数据
创建表

存数据

查询novellist表的前10个数据
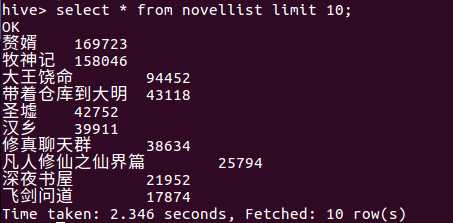
分析结果:
我选择了novellist的前10行显示,结果可以看到10部当月月票排名前10的小说,由此知道哪10本小说是当月赚钱最多的小说。
同时“赘婿”是当月月票数最多的小说。
原文:https://www.cnblogs.com/diansaonian/p/9090312.html