来源:https://zhuanlan.zhihu.com/p/22888385
神经网络由层来构建。每一层的工作内容:


(动态图5种空间操作)
每层神经网络的数学理解:用线性变换跟随着非线性变化,将输入空间投向另一个空间。
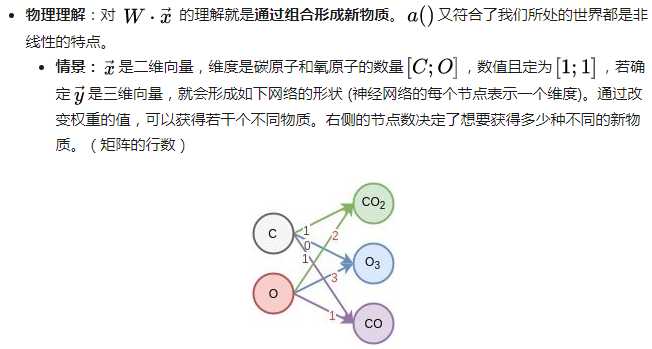

每层神经网络的物理理解:通过现有的不同物质的组合形成新物质。


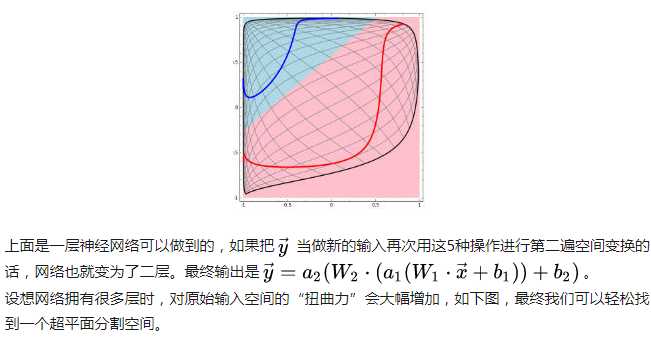

这里有非常棒的可视化空间变换demo,一定要打开尝试并感受这种扭曲过程。更多内容请看Neural Networks, Manifolds, and Topology。
线性可分视角:神经网络的学习就是学习如何利用矩阵的线性变换加激活函数的非线性变换,将原始输入空间投向线性可分/稀疏的空间去分类/回归。
增加节点数:增加维度(W权重矩阵的维度),即增加线性转换能力。
增加层数:增加激活函数的次数,即增加非线性转换次数。
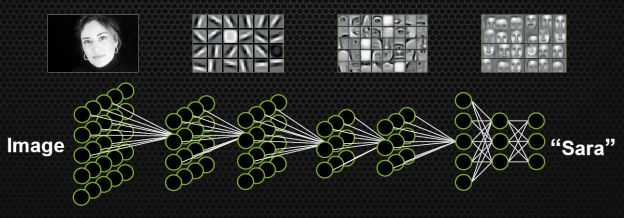
物质组成视角:神经网络的学习过程就是学习物质组成方式的过程。
增加节点数:增加同一层物质的种类,比如118个元素的原子层就有118个节点。
增加层数:增加更多层级,比如分子层,原子层,器官层,并通过判断更抽象的概念来识别物体。
神经网络的学习过程就是学习控制着空间变换方式(物质组成方式)的权重矩阵W。如何学习W?
既然我们希望网络的输出尽可能的接近真正想要预测的值。那么就可以通过比较当前网络的预测值和我们真正想要的目标值,再根据两者的差异情况来更新每一层的权重矩阵(比如,如果网络的预测值高了,就调整权重让它预测低一些,不断调整,直到能够预测出目标值)。因此就需要先定义“如何比较预测值和目标值的差异”,这便是损失函数或目标函数(loss function or objective function),用于衡量预测值和目标值的差异的方程。loss function的输出值(loss)越高表示差异性越大。那神经网络的训练就变成了尽可能的缩小loss的过程。 所用的方法是梯度下降(Gradient descent):通过使loss值向当前点对应梯度的反方向不断移动,来降低loss。一次移动多少是由学习速率(learning rate)来控制的。
使用梯度下降训练神经网络拥有两个主要难题。
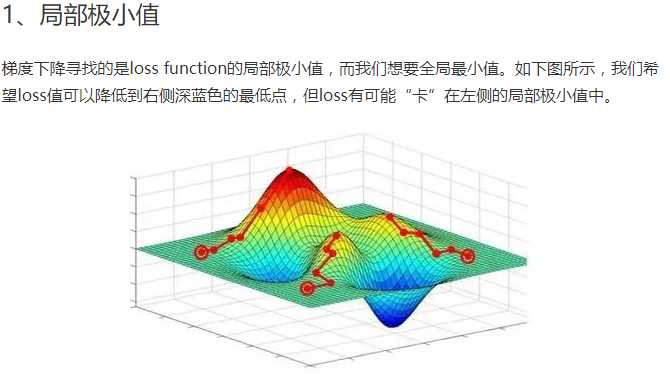
试图解决“卡在局部极小值”问题的方法分两大类:
机器学习所处理的数据都是高维数据,该如何快速计算梯度、而不是以年来计算。 其次如何更新隐藏层的权重? 解决方法是:计算图,反向传播算法。这里的解释留给非常棒的Computational Graphs: Backpropagation 需要知道的是,反向传播算法是求梯度的一种方法。如同快速傅里叶变换(FFT)的贡献。 而计算图的概念又使梯度的计算更加合理方便。
下面结合图简单浏览一下训练和识别过程,并描述各个部分的作用。要结合图解阅读以下内容。
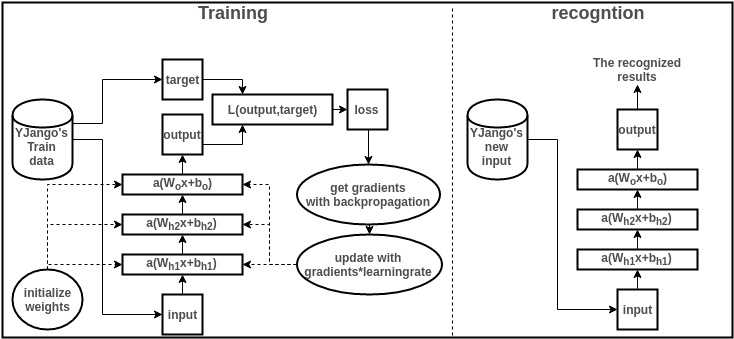



为了理解深层神经网络,需要明白最基本的训练过程。 若能理解训练过程是通过梯度下降尽可能缩小loss的过程即可。 若有理解障碍,可以用python实践一下从零开始训练一个神经网络,体会整个训练过程。若有时间则可以再体会一下计算图自动求梯度的方便利用TensorFlow。
https://zhuanlan.zhihu.com/p/22888385

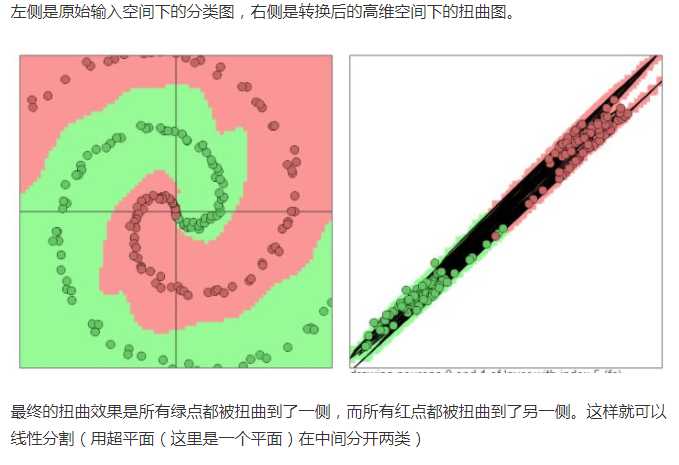
文章的最后稍微提一下深层神经网络。深层神经网络就是拥有更多层数的神经网络。
按照上文在理解视角中所述的观点,可以想出下面两条理由关于为什么更深的网络会更加容易识别,增加容纳变异体(variation)(红苹果、绿苹果)的能力、鲁棒性(robust)。
数学视角:变异体(variation),很多的分类的任务需要高度非线性的分割曲线。不断的利用那5种空间变换操作将原始输入空间像“捏橡皮泥一样”在高维空间下捏成更为线性可分/稀疏的形状。
物理视角:通过对“抽象概念”的判断来识别物体,而非细节。比如对“飞机”的判断,即便人类自己也无法用语言或者若干条规则来解释自己如何判断一个飞机。因为人脑中真正判断的不是是否“有机翼”、“能飞行”等细节现象,而是一个抽象概念。层数越深,这种概念就越抽象,所能涵盖的变异体就越多,就可以容纳战斗机,客机等很多种不同种类的飞机。
参考:https://zhuanlan.zhihu.com/p/24245040
参考:
https://zhuanlan.zhihu.com/p/24245040
https://zhuanlan.zhihu.com/p/22888385
https://www.zhihu.com/question/26006703/answer/126777449
原文:https://www.cnblogs.com/xianhan/p/8609573.html