感知机:
就现在我理解的来看,感知机是最早被设计使用的人工神经网络的模型。感知机属于二分类的线性分类模型,输入为实例的特征向量,输出为实例的类别,取值为+1和-1.
感知机使用特征向量来表示的前馈式人工神经网络,它是一种二元分类器,把矩阵上的输入 (实数值向量)映射到输出值
(实数值向量)映射到输出值 上(一个二元的值)。
上(一个二元的值)。
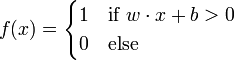
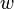 是实数的表式权重的向量,
是实数的表式权重的向量,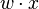 是点积。
是点积。 是偏置,一个不依赖于任何输入值的常数。偏置可以认为是激励函数的偏移量,或者给神经元一个基础活跃等级。
是偏置,一个不依赖于任何输入值的常数。偏置可以认为是激励函数的偏移量,或者给神经元一个基础活跃等级。
(0 或 1)用于对进行分类,看它是肯定的还是否定的,这属于二元分类问题。如果是负的,那么加权后的输入必须产生一个肯定的值并且大于 ,这样才能令分类神经元大于阈值0。从空间上看,偏置改变了决策边界的位置(虽然不是定向的)。
,这样才能令分类神经元大于阈值0。从空间上看,偏置改变了决策边界的位置(虽然不是定向的)。
由于输入直接经过权重关系转换为输出,所以感知机可以被视为最简单形式的前馈式人工神经网络。
在集合空间中可以这样认为:
线性方程W*X+b=0 为一个超平面,其中W是超平面的法向量,b为截距,这个超平面将特征空间划分为两个部分,分为正例和负例。W是法向量如(X1,X2,X3.......)
感知机的学习策略:
就是确定感知机模型的参数W,B,使得定义的(经验)损失函数极小化。
损失函数:
在这里我们将损失函数定义为:误分类点到超平面s的总距离。

学习方法:
感知机的学习算法是误分类驱动的,具体采用梯度下降法。
思想:当一个实例被误分的时候通过修改w和b使得超平面向误分类点移动,减少误分类点到超平面的距离。
首先任意取一个w b的超平面,比如w=0 b=0.然后用梯度下降法极小化目标函数(损失函数),极小化过程是一次随机选取误分类点使其梯度下降。
损失函数L(w,b)的梯度是对w和b求偏导,即:


原文:http://www.cnblogs.com/GuoJiaSheng/p/3852923.html