存档留用
(= 存档留着备用)
爬取的是一个开放的自动回复机器人 API 网站 http://i.itpk.cn/。 结构 大致如下:
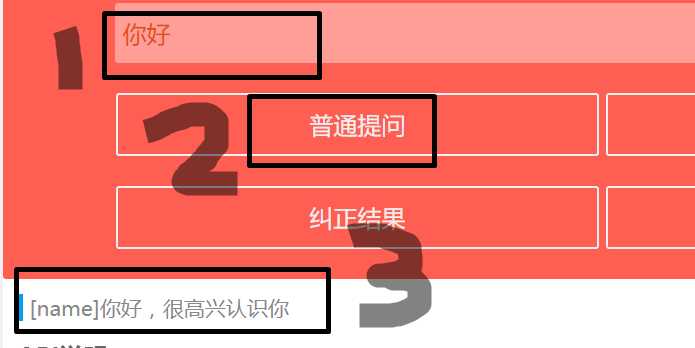
我做的事情就是 输入文字,点击按钮,爬取内容,如上图所示。
package org.sample.service.impl; import com.gargoylesoftware.htmlunit.WebClient; import com.gargoylesoftware.htmlunit.html.HtmlAnchor; import com.gargoylesoftware.htmlunit.html.HtmlElement; import com.gargoylesoftware.htmlunit.html.HtmlInput; import com.gargoylesoftware.htmlunit.html.HtmlPage; import org.sample.service.ThirdPartyRobot; import java.io.IOException; public class ThirdPartyRobotImpl implements ThirdPartyRobot { @Override public String getReplyByWords(String words) { String result = getReplyByWordsThroughMoLiRobot(words); return result; } private String getReplyByWordsThroughMoLiRobot(final String words) { // 打开浏览器 进入页面 WebClient webClient = new WebClient(); // webClient.getOptions().setJavaScriptEnabled(false); webClient.getOptions().setCssEnabled(false); webClient.getOptions().setUseInsecureSSL(false); HtmlPage page = null; try { page = webClient.getPage("http://i.itpk.cn/"); } catch (IOException e) { e.printStackTrace(); return null; } // 获取文本框 输入内容 HtmlInput question = (HtmlInput) page.getElementById("question"); question.setValueAttribute(words); // System.out.println(question.asText()); // 获取按钮 点击按钮 HtmlAnchor getAnswer = page.getAnchorByText("普通提问"); try { getAnswer.click(); } catch (IOException e) { e.printStackTrace(); return null; } // List<HtmlAnchor> Anchors = page.getAnchors(); // for (HtmlAnchor x : getAnswer) { // System.out.println(x.getHrefAttribute()); // System.out.println(x.asText()); // } try { Thread.sleep(300); } catch (InterruptedException e) { e.printStackTrace(); return null; } // 获取结果文本 HtmlElement reply = (HtmlElement) page.getElementById("reply"); String replyText = reply.asText(); // 关闭浏览器 webClient.close(); return replyText; } }
这次作业是写了个。。以 websocket 为基础的群聊 & 自动回复机器人,收到句子首先进行本地数据库匹配,匹配不到就启动爬虫。。总结与感想:Service 和 DAO 一定一定要定义好接口,这样最开始数据库设计不当,或者 service 实现不好 修改起来才方便。
原文:https://www.cnblogs.com/xkxf/p/9138470.html