豆瓣上有图书的排行榜,所以这次写了一个豆瓣的爬虫。
首先是分析排行榜的url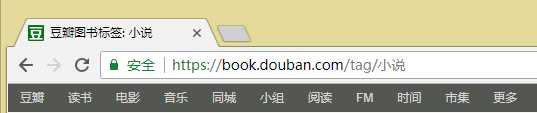
根据这个可以很容易的知道不同图书的排行榜就是在网站后面加上/tag/【类别】,所以我们首先要获得图书的类别信息。
这里可以将读书首页的热门标签给爬下来。


爬取标签内容并不难,代码如下:
1 def getLabel(url): #获得热门标签 2 html = getHTMLText(url) 3 soup = BeautifulSoup(html, ‘html.parser‘) 4 a = soup.find_all(‘a‘) 5 label_list = [] 6 for i in a: 7 try: 8 href = i.attrs[‘href‘] 9 match = re.search(r‘/tag/.*‘, href) 10 if match and match[0][5]!=‘?‘: 11 label_list.append(match[0]) 12 except: 13 continue 14 return label_list
接下来是进入排行榜页面进行信息爬取,

代码如下:
1 def getBookInfo(): 2 label_list = getLabel(‘https://book.douban.com/‘) 3 label = get_label(label_list) 4 name = [] 5 author = [] 6 price = [] 7 score = [] 8 number = [] 9 for page in label_list[int(label)-1:int(label)]: 10 for i in range(2): 11 html = getHTMLText(‘https://book.douban.com‘ + page + ‘?start=‘ + str(i*20) + ‘&type=T‘) 12 soup = BeautifulSoup(html, ‘html.parser‘) 13 book_list = soup.find_all(‘div‘, attrs={‘class‘:‘info‘}) #找到书籍的信息列表 14 for book in book_list: 15 a = book.find_all(‘a‘,attrs={‘title‘:re.compile(‘.*‘)})[0] #找到包含书籍名的a标签 16 name.append(a.get(‘title‘)) #获得标题属性 17 18 pub = book.find_all(‘div‘, attrs={‘class‘:‘pub‘})[0] 19 pub = pub.string.strip().replace(‘\n‘,‘‘) 20 author.append(re.findall(r‘(.*?)/‘, pub)[0].strip()) 21 split_list = pub.split() #空格分割 22 for j in split_list: 23 match = re.search(r‘\d.*\..*‘, j) #获得价格信息 24 if match: 25 price.append(match[0]) 26 27 span = book.find_all(‘span‘, attrs={‘class‘:‘pl‘})[0] #获得评价人数所在标签 28 span = span.string.strip().replace(‘\n‘,‘‘) 29 number.append(re.findall(r‘\d+‘, span)[0]) #获得人数 30 31 span = book.find_all(‘span‘, attrs={‘class‘:‘rating_nums‘})[0] 32 score.append(span.string) 33 34 tplt = "{:3}\t{:15}\t{:15}\t{:10}\t{:4}\t{:7}" #规定输出格式 35 print(tplt.format("序号", "书籍", "作者", "价格", "评分", "评价人数")) 36 l = len(name) 37 for count in range(l): 38 print(tplt.format(count+1, name[count],author[count],price[count],score[count],number[count]))
最终的总代码为:
1 import requests 2 import re 3 from bs4 import BeautifulSoup 4 5 6 def getHTMLText(url): 7 try: 8 r = requests.get(url, timeout=30) 9 r.raise_for_status() 10 r.encoding = r.apparent_encoding 11 return r.text 12 except: 13 return "" 14 15 16 def getLabel(url): #获得热门标签 17 html = getHTMLText(url) 18 soup = BeautifulSoup(html, ‘html.parser‘) 19 a = soup.find_all(‘a‘) 20 label_list = [] 21 for i in a: 22 try: 23 href = i.attrs[‘href‘] 24 match = re.search(r‘/tag/.*‘, href) 25 if match and match[0][5]!=‘?‘: 26 label_list.append(match[0]) 27 except: 28 continue 29 return label_list 30 31 32 def get_label(label_list): 33 count = 1 34 for i in label_list: 35 print(str(count) + ‘: ‘ + label_list[count-1][5:] + ‘\t‘, end=‘‘) 36 count = count + 1 37 choose = input(‘\n\n请输入你想查询的图书类别:‘) 38 while int(choose)<=0 or int(choose)>=count: 39 choose = input(‘\n请输入正确的类别编号:‘) 40 return int(choose) 41 42 def getBookInfo(): 43 label_list = getLabel(‘https://book.douban.com/‘) 44 label = get_label(label_list) 45 name = [] 46 author = [] 47 price = [] 48 score = [] 49 number = [] 50 for page in label_list[int(label)-1:int(label)]: 51 for i in range(2): 52 html = getHTMLText(‘https://book.douban.com‘ + page + ‘?start=‘ + str(i*20) + ‘&type=T‘) 53 soup = BeautifulSoup(html, ‘html.parser‘) 54 book_list = soup.find_all(‘div‘, attrs={‘class‘:‘info‘}) #找到书籍的信息列表 55 for book in book_list: 56 a = book.find_all(‘a‘,attrs={‘title‘:re.compile(‘.*‘)})[0] #找到包含书籍名的a标签 57 name.append(a.get(‘title‘)) #获得标题属性 58 59 pub = book.find_all(‘div‘, attrs={‘class‘:‘pub‘})[0] 60 pub = pub.string.strip().replace(‘\n‘,‘‘) 61 author.append(re.findall(r‘(.*?)/‘, pub)[0].strip()) 62 split_list = pub.split() #空格分割 63 for j in split_list: 64 match = re.search(r‘\d.*\..*‘, j) #获得价格信息 65 if match: 66 price.append(match[0]) 67 68 span = book.find_all(‘span‘, attrs={‘class‘:‘pl‘})[0] #获得评价人数所在标签 69 span = span.string.strip().replace(‘\n‘,‘‘) 70 number.append(re.findall(r‘\d+‘, span)[0]) #获得人数 71 72 span = book.find_all(‘span‘, attrs={‘class‘:‘rating_nums‘})[0] 73 score.append(span.string) 74 75 tplt = "{:3}\t{:15}\t{:15}\t{:10}\t{:4}\t{:7}" #规定输出格式 76 print(tplt.format("序号", "书籍", "作者", "价格", "评分", "评价人数")) 77 l = len(name) 78 for count in range(l): 79 print(tplt.format(count+1, name[count],author[count],price[count],score[count],number[count])) 80 81 82 83 if __name__ ==‘__main__‘: 84 print(‘豆瓣图书综合排序查询\n‘) 85 getBookInfo() 86
最后的运行效果:
首先是类别表:
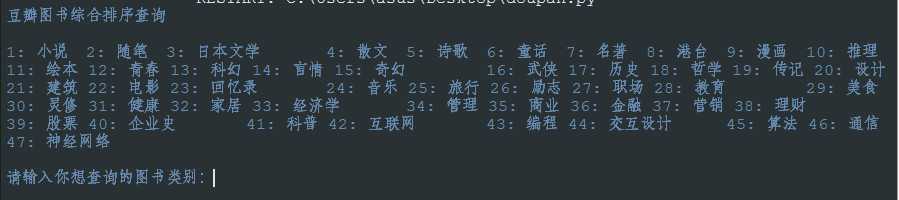
输入图书类别后就可以显示图书信息了:
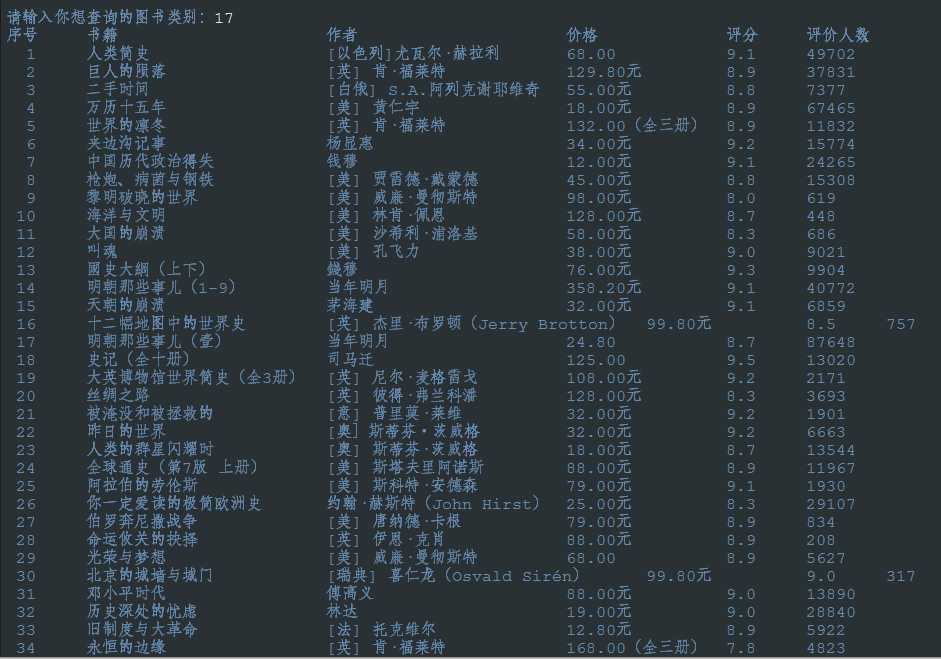
我这里只爬取了两页的图书信息。
因为有些书的信息是不完整的,所以在爬取时可能会出现错误。我正则表达式写得也不是很好,很多地方都是会出错的,比如价格那儿。
原文:https://www.cnblogs.com/zyb993963526/p/9188881.html