正则表达式以前用过,但是从来没有系统的总结过,今天就正则表达式,及一些细节进行一些总结。
正则表达式(Regular Expression):是一个用来匹配包含元字符(通配字符)的一个字符串
元字符:
基本元字符: .(任意的一个非换行字符)
[字符](匹配一个在中括号中的字符)
| 或(优先级最低)
() 用来修改优先级,和分组
限定元字符: +表示紧跟在前面的字符出现一次到多次 {1,}
* 表示紧跟在前面的字符出现0次到多次 {0,}
? 表示紧跟在前面的字符出现0次到1次 {0,1}
{n} 表示紧跟在前面的字符出现n次
{n,} 表示紧跟在前面的字符出现n次到多次
{n,m} 表示紧跟在前面的字符出现n次到m次
首尾元字符: ^ 表示必须以某个字符开头或否定
$表示必须以某个字符结尾或分组引用
在C#中如何使用正则表达式
-> 在C#中的核心功能为
-> 匹配
-> 提取
-> 替换
-> 使用
-> 引入命名空间 System.Text.RegualrExpressions;
-> 使用Regex这个类提供的静态方法
-> 匹配:bool Regex.IsMatch(要匹配的文本, 正则表达式)
-> 提取:
Match Regex.Match(要处理的字符串, 正则表达式)
MatchCollection Regex.Matches(要处理的字符串, 正则表达式)
-> 替换:
string Regex.Replace(要处理的字符串, 正则表达式, 替换为字符串)
提取组
-> 给一个字符串,将所有的图片地址提取出来
-> 在正则表达式中,每一个圆括号是一个分组,在匹配的结果中组会单独的存储
分组是有编号的,编号从左往右数,凡是看到"("记一个编号,编号从1开始
匹配完成以后,使用<Match>的Groups属性获得组的集合
编号中第几组就用<Match>.Groups[几]进行访问
这些理论的东西很多网上都有,下面我们看一下demo

/// <summary> /// 匹配demo /// </summary> public static void Match() { string str = "2014-02-10"; string reg = @"^\d{4}(-\d{2}){2}$"; if (Regex.IsMatch(str, reg)) { Console.WriteLine("匹配成功!"); } else { Console.WriteLine("匹配失败!"); } Console.ReadKey(); }
/// <summary> /// 提取 /// </summary> public static void Extract() { string str = "今天是2014-02-10,天气晴天,明天是2014-02-11,天气小雨。"; string reg = @"\d{4}(-\d{2}){2}"; //提取第一个匹配的字符串 Match m= Regex.Match(str,reg); if (m.Success) { Console.WriteLine("匹配的值 {0}", m.Value); Console.WriteLine("匹配的索引 {0}", m.Index); Console.WriteLine("匹配的长度 {0}", m.Length); } else { Console.WriteLine("不能成功匹配"); } Console.WriteLine("=========================="); //提取所有匹配的字符串 MatchCollection m1= Regex.Matches(str, reg); for (int i = 0; i < m1.Count; i++) { if (m1[i].Success) { Console.WriteLine("匹配的值 {0}", m1[i].Value); Console.WriteLine("匹配的索引 {0}", m1[i].Index); Console.WriteLine("匹配的长度 {0}", m1[i].Length); } else { Console.WriteLine("未能成功匹配i={0}",i); } } Console.ReadKey(); }
由于上面的代码比较简单,在这里笔者就不贴结果图了。
我们一起看下提取组:
/// <summary> /// 提取组 /// </summary> public static void ExtractGroup() { string html = @" <td> <img src=‘hotgirls/00_02.jpg‘ /></td> <td> <img src=‘hotgirls/00_03.jpg‘ /></td>"; string reg = @"src=‘(.+)‘"; MatchCollection m1 = Regex.Matches(html,reg); for (int i = 0; i < m1.Count; i++) { Console.WriteLine(m1[i].Value); Console.WriteLine(m1[i].Groups[0].Value); Console.WriteLine(m1[i].Groups[1].Value); Console.WriteLine("============================="); } Console.ReadKey(); }
上面的reg的正则表达式只有一个左圆括弧,所以有一个分组,我们来看下结果
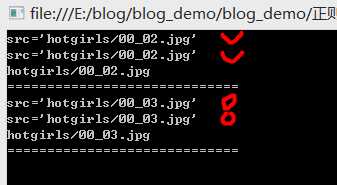
我们发现m1[i].Value的值和m1[i].Groups[0].Value值是一样的,没错,其实他们就是同一个值,我们要获取的图片的路径也拿到了(没有标记的就是),是通过m1[i].Groups[1].Value值获取到的,这个第几组我们是可以通过数括弧数出来, string reg = @"src=‘(.+)‘"; 我们看见上面有一个圆括弧,所有我们就知道第1组的数据就是我们要的图片路径。
贪婪模式
-> string s = "12345";
string r = "(\d+)(\d+)";
从左往右权级递减,正则表达式中只有两个权级,
一个是尽可能匹配,一个是尽可能不匹配
-> 文件目录的案例
string file = @"C:\123\4565\789\abcd.mp3";
string reg = @"((.:)\\.+)\\((.+)(\..+))";//利用贪婪模式写分组正则
string reg = @"((.:)(\\.+)?\\)((.+)(\..+))";//能够匹配c:\abcd.mp3
贪婪模型的demo笔者就不写代码了,用一个正则测试工具Code Architects Regex Tester演示一下。
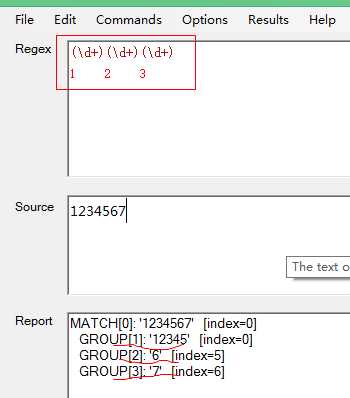
我们可以看见上面有3个圆括号,所以我们分组的话可以分成3组(第0组一般不算),第1组匹配的数据明显要多于第二组和第三组,原因是第一组都把字符给吃掉了,但是总是要留一下给第2组第3组吃,所以留最少的,第二组最少有一个字符,第三组有一个字符,所以第一组吃到了5,第二组吃到了6,第三组吃到了7.
那由此我们猜测一下:如果正则表达式变成了(\d+)(\d*)(\d+)这个,那么第二组最少吃0个字符,第三组吃1个字符,所以我们猜测的结论是
第一组 1,2,3,4,5,6
第二组
第三组 7
我们看下结果
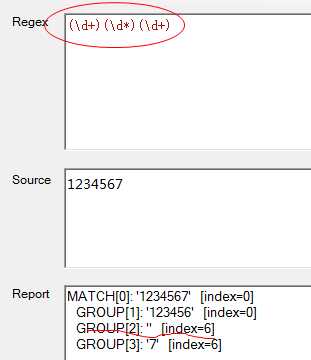
这个结果我们猜测的是一样的,由此得到结论:从左往右权级递减,正则表达式中只有两个权级,一个是尽可能匹配,一个是尽可能不匹配。
下面关于贪婪模式的一些介绍:摘自其他人的博客,他们写的非常好。
参考博文:http://blog.csdn.net/myan/article/details/1520033
深入正则表达式原理
一 、先说正则表达式(regular expression)的基础语法:元字符(metacharacters)和常用的正则表达式
1. 点号:. 匹配单个任意的字符(包括空格,换行符,回车符,制表符,换页符)。
2. 字符组 [ ] 匹配单个字符。如[abdcedf]也就是匹配[]中的任一个字符都能成功:匹配a成功匹配b也能成功,但不能匹配k这样没有在[]中出现的字符。
3. 排除型字符组 [^ ] 排除括号内列出的字符 如[^abcd]匹配e能够成功,匹配a就失败
4. 转义字符 \ 通常是把元字符转化成普通的字符 通常用于转换如:在匹配.号时,正常情况下正则表达式引擎(会在后面谈到)会把.当做元字符来处理,但是加上\就可以把\.中的点号当做一个普通的字符来处理。
5. 问号 ? 匹配一个或没有的字符
6. 星号 * 匹配多个或没有的字符
7. 加号 + 至少匹配一个字符或多个
8. 区间词{min,max} 匹配至少min次,和至多max次
9. ^ 匹配一行的开头
10. $ 匹配一行的结尾
11. \b 匹配单词的分界符
12. {?=} 肯定顺序环视
13. {?!} 否定顺序环视
14. {?<=} 肯定逆向环视
15. {?<!} 否定逆向环视
16. {?:} 非捕获分组
17. {?>} 固化分组 二、下面的正则表达式针对各种语言又有一些的变化:
1. \d 匹配任意的数字
2. \D 匹配任意的非数字
3. \w 匹配任意的小写字母,大写字母和数字和下划线_等于[a-zA-Z0-9_]
4. \W 匹配任意的非字母等于[^\s]
5. \s 匹配空字符如空格符,制表符,等
6. \S 匹配非空字符
7. \1\2 主要用于分组获得所分的组项,有时用的很方便哦。
还有就是一些常用的匹配表达式:
1. \n 匹配换行符
2. \A 匹配一行的开头与^一样的功能 三、 上面的都是些简单的语法,我相信大多数都能懂,那我就讲一些难懂的内容吧:
(1) .正则表达式的核心是正则表达式引擎处理方式。一般正则表达式引擎分为两种:NFA和DFA。 但其中的NFA又有两个分支:传统的NFA和POSIX NFA 以下是各种语言所支持的引擎:
传统NFA:GNU Emacs、java、grep、less、more、.NET、Perl、PHP、Python、Ruby、sed等
DFA :awk、egrep、flex、MySQL、Procmail
POSIX NFA:mawk、Mortice Kern等等。
DFA/NFA混合引擎:GNU awk 、GNU grep/egrep、Tcl
(2). 正则表达式真正起作用是由于这些引擎来计算匹配。所以要想弄懂正则表达式的内部机制,就必须要明白你所熟悉的语言(如java,.net用的都是传统的NFA)是采用的那种引擎。每一种语言都有这自己引擎,也就有自己的独特的规范和独特的匹配原则。所以正则表达式说采用的匹配结果也不一样。
但不管是DFA还是NFA他们又有一些共性原则如:
1. 优先匹配最左端(最靠开头)的匹配结果。
2.标准的匹配量词(*、+、?和{min,max})是匹配优先的。
1* 先来说第一条:最左端匹配结果:
如果你用:cat来匹配下面的一句话: The dragging belly indicates that your cat is too fat. 你本想匹配其中的cat,但是结果却不是,而是indicates中的cat。单词cat 是能够被匹配出来,但是indicates中的cat出现 的更早,所以就先匹配成功了。对于java程序员来说,他只关心是否能匹配而不关心在哪匹配。再来一个例子: 用:fat | cat | belly | your来匹配字符串上面的那一句话。结果会是什么呢? 你认为会是最后的fat是吗?因为fat在 fat | cat | belly | your最前面,是吗?错:答案是belly,句中的belly,为什么呢?由于匹配是从句中的第一个字母T来一次匹配fat | cat | belly | your,中的所有选项,结果发现都不符合,就走到h来匹配,结果也不符合,就依次走下去,直到b字母,有一项符合,就是fat | cat | belly | your中的belly中的b,所以依次匹配发现成功了,所以就正确了。就不在向后面的单词匹配(这种结果只是在支持NFA的引擎中)。
2* 再来说说第二条:标准量词(*、+等)是匹配优先(greedy 贪婪的意思)的。从英文单词中,我们就可以发现一些原理。其实的确就是这样。 用\b\w+s\b 来匹配包含s的字符串,如regexes,整个是能够比配成功的,你或许会认为它是正则表达式\w+匹配到xe结束然后让s来匹配最后的regexes中的s,若你这样想,那就错了,其实\w+一次性的匹配到结束包括s在内都被它给匹配了,但后面有个s所以,她很不情愿的吐出一个s来,让后面的s来匹配。这样使得匹配成功。这个+是不是很greedy啊?像欧也妮~葛朗台是吗?O(∩_∩)O哈哈~,对了,就是,这条规则很重要,对于正则表达式的优化很重要。很多时候就是在这个基础上进行优化的。 下面就再来比较一下DFA和NFA的区别。 一般DFA速度较快,而NFA的控制能力较强。这两者各有千秋。 NFA引擎是表达式主导(有点困了,还是下次再写吧,那先留个目录,有助于下次写的:下面主要是NFA的工作原理,不同regular Expression 的流派,然后就是正则表达式的优化和调校,再者就是正则表达式的书写和案例经典例子的回放,最后是写我最爱的Java语言的正则表达式的应用)
一、上篇中说到NFA正则引擎的表达式主导:
(1). 为什么说NFA是表达式主导,请看下面的例子: 用 to(nite | knight | night) 来匹配 " I am going to seeing film tonight,could you go with me? "这段文本。
NFA引擎会从文本中的第一个字母I开始匹配,它会把匹配表达式全部走一遍,然后发现没有成功,则正则表达式引擎会驱动向下走,到达第二个字符-空格,发现整个匹配表达式也没有匹配成功,则继续,然后到a,依次类推,直到“tonight"这个to,成功匹配后,转向文本中tonight中的n,发现(nite)符合,这它不会再向下匹配,返回成功,然后转向tonight中的i,发现也能成功,则它也不会继续向下匹配,然后转向文本tonight中的g,到正则表达式中的(nite)发现t不匹配,则此时正则引擎会回退从knight单词的k字母进行匹配,发现也不符合,则回退,再从night单词中的n开始匹配,发现符合,则继续匹配,然后到i,发现匹配再到g,依次类推直到匹配成功。最后返回匹配成功。你明白没?其实表达式的控制权在不同的元素字母之间转换,所以我们称之为“表达式主导”
(2). DFA引擎的文本主导: 继续我们的这个例子。 但我们进行I字母的匹配时不成功,就不说了,一直到tonight单词是,前面的to比配成功后,当进行to(nite | knight | night)中的n进行匹配时,DFA会同时向三个选项发出匹配请求,有(nite和night)两个符合,(发现没是同时发出请求)则就会抛弃knight选项,以后就不会再进行匹配,然后是i字母的匹配,发现nite和night都符合,则继续,到tonight中的g,在DFA中同时再向nite和night发出匹配请求,发现只有night符合,就会抛弃nite这个选项,然后继续向下匹配。知道成功。发现没,这种方法少了NFA中的很多的回退,所以效率高。。。。
二、有现在主流的语言都是用的是NFA正则引擎,那我们就来重点介绍它的实现机制: 要想了解其中的原理,我们先了解几个概念:回溯、备用状态 专业术语是回溯其实在我的理解就是回退。NFA引擎最很重要的性质是:她会一次处理各个表达式,或组成元素,遇到需要在两个可能成功中进行选择的时候,她会选择其一,同时记住另一个,以备稍后的可能的需要。 并且重要的是:不论选择那一种途径,如果它能匹配成功,而且正则表达式的余下部分也能匹配成功,此时才宣告最终匹配成功,或许你觉得我这个说的是废话。但你请看下面的,如果正则表达式中余下的部分最终匹配失败,引擎会知道需要回溯到之前作出选择的地方,选择其他的备用分支继续尝试。这样最终表达式所有的可能途径知道最终的成功或失败。回溯常和备用状态联系起来分析,那就来说一下,什么叫备用状态。
按我的理解是:大家应该都知道迷宫,走迷宫最常用的方法就是做记号,此刻我们假如用石头做记号,每当我们遇到十字路口是,我们就丢下一块石头,来标记我们所选择的路口,但我们发现不此路不通时,我们就进行回溯,回退到离我们最近的哪一个十字路口,然后重新选择我们的方向,这种方法是我们最常用的。我要说的是,正则表达式中的备用状态就是那个我们在每个十字路口的石头。其实我觉得这就算递归中的回溯,要是你理解了递归,这个应该不难理解。NFA中的LIFO(后进先出)的原则我觉就是那个迷宫此路不通的记号石头就是我们最好的LIFO例子。 整个NFA中的优化其实就是这个回溯原则和greedy原则(上一篇中讲到的),进行合理的优化和匹配。
三、忽略优先量词(*?、+?、??、{min、max}?、)
针对NFA的greedy原则,正则表达式有了忽略优先量词,这很大程度上解决了,很多由于greedy原则带来的麻烦和效率的问题。她只会匹配符合要求的最小的选择。
如: 若用 <B>.*</B> 来匹配<B>I</B>and<B>you</B>are chinese,we are very happy to be chinese. 结果会是:<B>I</B>and<B>you</B> 但用<B>.*?</B>匹配 则结果是:<B>I</B>
四:固化分组:(?>) 使用固化分组,这会让引擎不记住备用状态,这又是能很好的提高正则表达式的效率。这也是优化正则表达式的常用方式。如下面的例子:用 i.*! 来匹配 iHello! 在没有用固化分组时,是可以匹配成功的。 若用固化分组,i(?>.*)! 来匹配 iHello! 则匹配不成功,由于*是贪婪的她会一直匹配到最后,又由于固化分组了.*,她不会再吐出字符让后面的!来匹配。所以匹配失败。
原文:http://www.cnblogs.com/dongqinglove/p/3543730.html