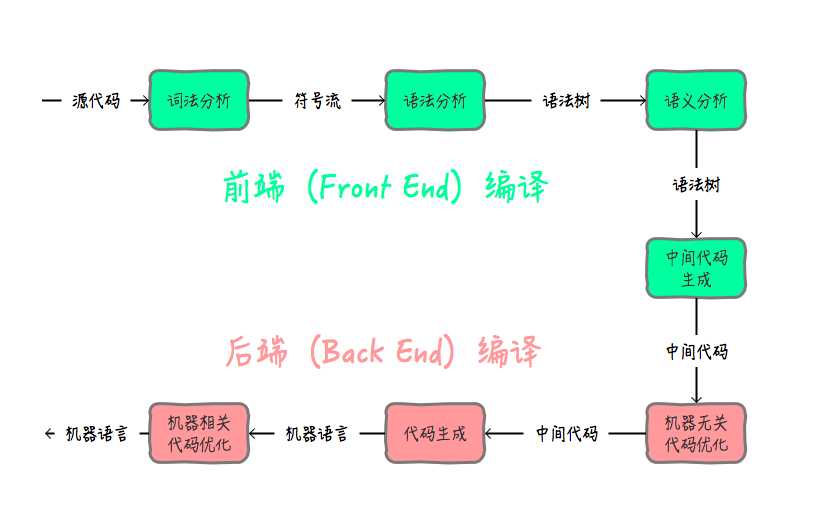
(1)前端编译器:.java文件转变为.class文件Sun的javacEclipse JDT中的增量编译器(ECJ)
(2)后端编译器:.class文件转变为机器码HotSpot VM的C1编译器HotSpot VM的C2编译器
(3)AOT编译器:.java文件按直接转变为机器码GNU Compiler for Java(GCJ)Excelsior JET
解析与填充符号表过程
填充符号表
插入式注解处理器的注解处理过程
分析与字节码生成过程
字节码生成

initProcessAnnotations(processors); // 准备过程:初始化插入注解处理器
// These methoad calls must be chained to avoid memory leaks
delegateCompiler =
processAnnotations( //2:执行注解处理
enterTrees(stopIfError(CompileState.PARSE, // 1.2:填充符号表
parseFiles(sourceFileObjects))), // 1.1:词法分析与语法分析
classnames);
delegateCompiler.compile2(); //3:分析及字节码生成
// inner compile2
case BY_TODO:
while(!todo.isEmpty())
generate( // 3.4:生成字节码
desuger( // 3.3:解语法糖
flow( //3.2: 数据流分析
attribute(todo.remove())))); // 3.1:标注
break; (1)定义:符号表(Symbol Table)是一组符号地址与符号信息构成的表格。
(2)符号表中记录的信息在编译的不同阶段都要用到,如:语义分析时,符号表中的内容用于语义检查(名字与原先的说明是否一致)与生成中间代码;在目标代码生成阶段,对地址名进行地址分配就是根据符号表的记录。(3)解析类:com.sun.tools.javac.comp.Enter
(1)JDK1.5,java语言提供了注解的支持,但当时只能在运行期发挥作用。
(2)JDK 1.6,提供了插入式注解处理器的标准API在编译期间对注解进行处理。这些注解处理器能在处理注解期间对语法树进行修改,所以需要回到解析以及填充符号表的过程,这称为一个Round。
(3)处理类:com.sun.tools.javac.processing.JavacProcessingEnvironment
(1)标注检查
(2)数据及控制流分析
(3)解语法糖
如:类构造器和实例构造器的生成(顺序为父类的构造器先执行)
关联类:com.sun.tools.javac.jvm.Gen、com.sun.tools.javac.jvm.ClassWriter
(1)泛型与类型擦除
Java的泛型基于类型擦除,在编译期间就把泛型变为原来的裸类型。
List<String> list = new ArrayList<>();
list.add("hello");
list.add("world");
System.out.println(list.get(0));
============================>
List list = new ArrayList();
list.add("hello");
list.add("world");
System.out.println((String)list.get(0));(2)自动装箱、拆箱与遍历循环
List<Integer> list2 = Arrays.asList(1,2,3,4,5,6);
int sum = 0;
for (int i : list2)
sum += i;
============================>
List list2 = Arrays.asList(new Integer[] { Integer.valueOf(1), Integer.valueOf(2), Integer.valueOf(3), Integer.valueOf(4), Integer.valueOf(5), Integer.valueOf(6) });
int sum = 0;
for (Iterator localIterator = list2.iterator(); localIterator.hasNext(); ) {
int i = ((Integer)localIterator.next()).intValue();
sum += i;
}
// 自动装箱 int -> Integer
1 -> Integer.valueOf(1)
// 自动拆箱 Integer -> int
Integer::intValue()
// 增强for循环
for(int i : list)
->
for(Iterator localIterator = list.iterator(); localIterator.hasNext(); ){
int i = localIterator.next();
}
// 自动装箱以及自动拆箱的陷阱
Integer a = 1;
Integer b = 2;
Integer c = 3;
Integer d = 3;
Integer e = 321;
Integer f = 321;
Long g = 3L;
System.out.println(c == d); // true
System.out.println(e == f); // false,==不遇到算术运算符不自动拆箱(即两个Integer比较)
System.out.println(c == (a + b)); // true
System.out.println(c.equals(a + b)); // true
System.out.println(g == (a + b)); // true
System.out.println(g.equals(a + b)); // false
注意:equals方法不处理数据转换,==方法不遇到算术运算符不会自动拆箱。
Integer a = Integer.valueOf(1);
Integer b = Integer.valueOf(2);
Integer c = Integer.valueOf(3);
Integer d = Integer.valueOf(3);
Integer e = Integer.valueOf(321);
Integer f = Integer.valueOf(321);
Long g = Long.valueOf(3L);
System.out.println(c == d);
System.out.println(e == f);
System.out.println(c.intValue() == a.intValue() + b.intValue());
System.out.println(c.equals(Integer.valueOf(a.intValue() + b.intValue())));
System.out.println(g.longValue() == a.intValue() + b.intValue());
System.out.println(g.equals(Integer.valueOf(a.intValue() + b.intValue()))); // Integer 与 Long比较(3)条件编译:com.sun.tools.javac.comp.Lower完成
if (true){
System.out.println("true");
}else{
System.out.println("false");
}
===============================>
System.out.println("true");概述:JIT编译期能在JVM发现热点代码时,将这些热点代码编译成与本地平台相关的机器码,并进行各个层次的优化,从而提高热点代码的执行效率。
目的:提高热点代码的执行效率。
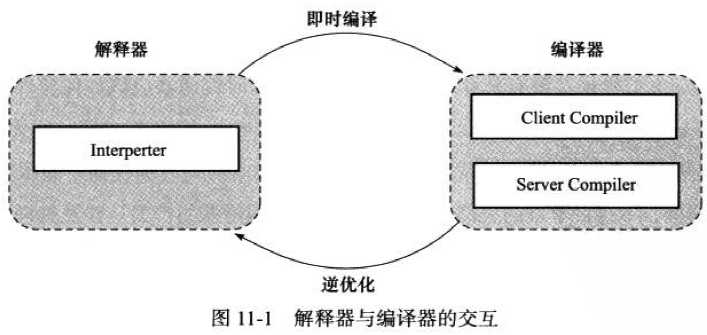
(1)并存的优势
(2)Hotspot虚拟机内置的JIT编译器
(3)JVM的运行模式
(4)编译层次:
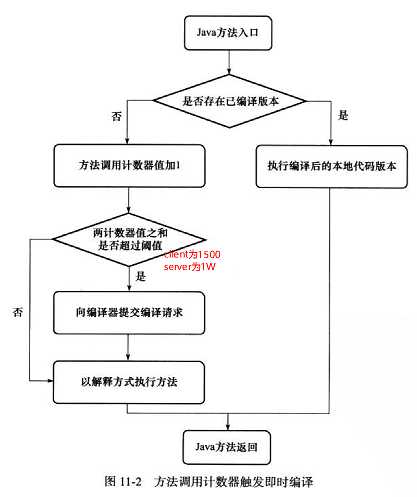
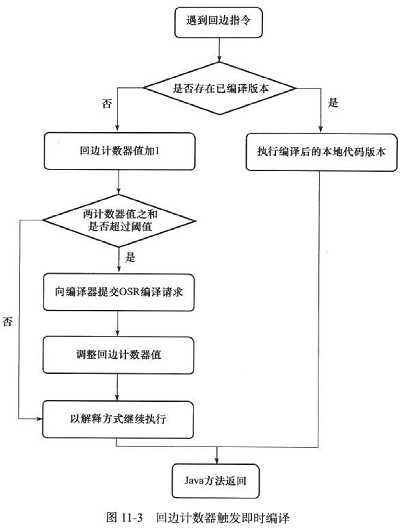
(1)编译对象(热点代码)
循环体编译优化发生在方法执行过程中,称为栈上替换(On Stack Replacement,简称OSR编译,机方法栈帧还在栈上,方法就被替换了)
(2)热点代码探测判定
(3)基于计数器的热点探测分类
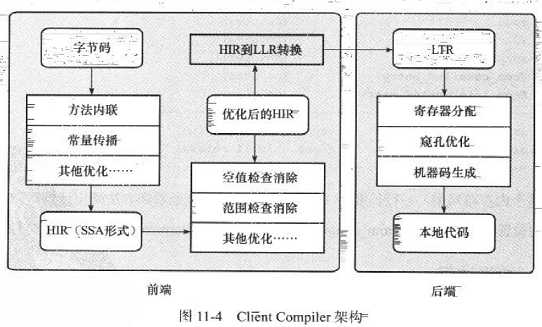
(1)一个平台独立的前端将字节码构造成一种高级中间代码(HIR,High Level Intermediate Representation)表示。HIR使用静态单分配的形式代表代码值,使得HIR的构造过程中和之后进行优化动作更容易实现。在此之前会进行基础优化,如:方法内联、常量传播等。
(2)一个平台相关的后端从HIR中产生低级中间代码(LIR)表示,而在此之前进行HIR上的优化,如:空值检查、范围检查消除等
(3)平台相关的后端使用线性扫描算法在LIR上分配寄存器,并在LIR上做窥孔优化,产生机器代码。
(1)优化技术概述
// 优化前
static class B{
int value;
final int get(){
return value;
}
}
public void foo(){
y = b.get();
// ...do stuff
z = b.get();
sum = y + z;
}
// 内联优化后
public void foo(){
y = b.value;
// ...do stuff
z = b.value;
sum = y + z;
}
// 冗余访问消除或公共子表达式消除后
public void foo(){
y = b.value;
// ...do stuff
z = y;
sum = y + z;
}
// 复写传播后
public void foo(){
y = b.value;
// ...do stuff
y = y;
sum = y + y;
}
// 无用代码消除后
public void foo(){
y = b.value;
// ...do stuff
sum = y + y;
}(2)公共子表达式消除 :一个表达式已经被计算过且从先前的计算到现在都没发生变化,那么E就成为了公共子表达式。
// 未优化前
int d = (c * b) * 12 + a + (a + b + c);
// 公共子表达式消除后
int E = c * b;
int d = E * 12 + a + (E + a);
// 代数化简后
int d = 13 * E + 2 * a;(3)数组边界检查消除
(4)方法内联
// 优化前
public static void foo(Object obj){
if(obj != null){
Sout("do something");
}
}
public static void testInline(String[] args){
Object obj = null;
foo(obj);
}
// 优化后
public static void testInline(String[] args){
Object obj = null;
if(obj != null){
Sout("do something");
}
}(5)逃逸分析 :为其他优化提供分析手段
(6)根据逃逸分析证明一个对象不会逃逸到方法或线程中,则进行高效的优化
(1)Java的劣势:
(2)Java的优势:
原文:https://www.cnblogs.com/linzhanfly/p/9245074.html