Apache Kylin是一个开源的分布式分析引擎。完全由eBay Inc.中国团队开发
并贡献至开源社区。提供Hadoop之上的SQL查询接口及多维分析(MOLAP)能力以
支持大规模数据能在亚秒内查询巨大的Hive表(十亿百亿的海量数据)。
Apache Kylin社区发展

大数据分析面临的挑战
Huge volume data
Table scan
Big table joins
Data shuffling
Analysis on different granularity
Runtime aggregation expensive
Map Reduce job
Batch processing
High Concurrency
Kylin安装
Centos 6.x
NTP
hadoop集群
-v2.5
-HDFS
-MapReduce
HBase安装
-v1.1.3
Hive安装
-v1.2.1或者v2.0
Kylin
-v1.5.1 HBase1.1.3
Cube的构建
Segment
HBase的表
全量构建
增量构建
时间粒度可以很小--准实时
达到阀值多个小Segment Merge成大的Segment

百度地图应用的集群
软件环境:
CDH+Hive+HBase+Kylin0.71
硬件环境:
Kylin共四台;
1台master(100G内存)+3台slaves(30G内存)
Kylin的展望
Apache Kylin 有多牛?
Apache Kylin 是一个开源的分布式引擎,为Hadoop等大型分布式数据平台之上的超大规模数据集通过标准SQL查询及多维分析(OLAP)功能,提供压秒级的交互式分析能力。
在现在的大数据时代,越来越多的企业开始使用Hadoop管理数据,但是现有的业务分析工具(如Tableau,Microstrategy等)往 往存在很大的局限,如难以水平扩展、无法处理超大规模数据、缺少对Hadoop的支持;而利用Hadoop做数据分析依然存在诸多障碍,例如大多数分析师 只习惯使用SQL,Hadoop难以实现快速交互式查询等等。神兽Apache Kylin就是为了解决这些问题而设计的。
Apache Kylin,中文名麒(shen)麟(shou) 是Hadoop动物园的重要成员。Apache Kylin是一个开源的分布式分析引擎,最初由eBay开发贡献至开源社区。它提供Hadoop之上的SQL查询接口及多维分析(OLAP)能力以支持大 规模数据,能够处理TB乃至PB级别的分析任务,能够在亚秒级查询巨大的Hive表,并支持高并发。
Apache Kylin于2014年10月在github开源,并很快在2014年11月加入Apache孵化器,于2015年11月正式毕业成为Apache顶级项 目,也成为首个完全由中国团队设计开发的Apache顶级项目。于2016年3月,Apache Kylin核心开发成员创建了Kyligence公司,力求更好地推动项目和社区的快速发展。
Kylin的基本原理和架构
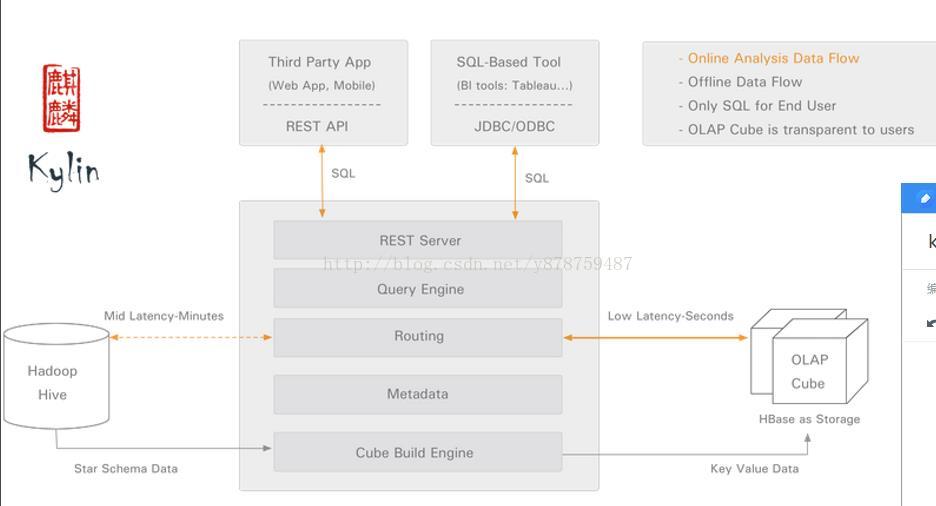
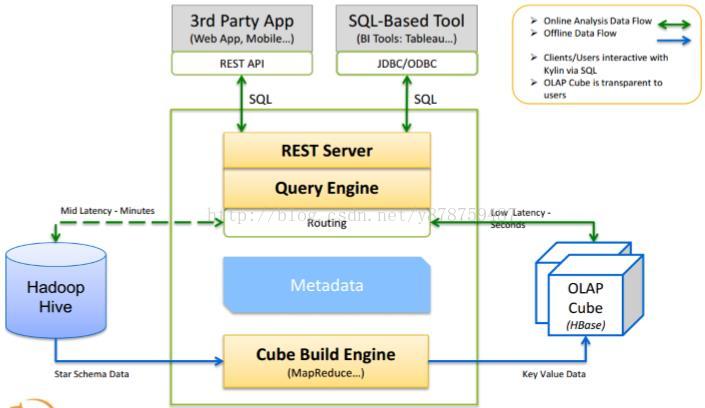
Kylin的核心思想是预计算,即对多维分析可能用到的度量进行预计算,将计算好的结果保存成Cube,供查询时直接访问。把高复杂度的聚合运算、多表连接等操作转换成对预计算结果的查询,这决定了Kylin能够拥有很好的快速查询和高并发能力。
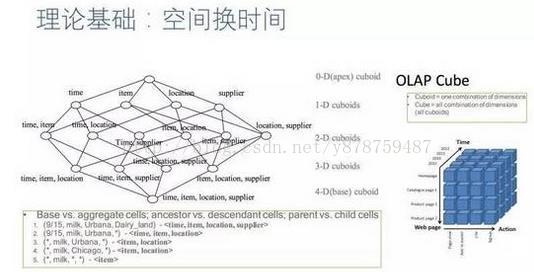
说到Cube的构建,Kylin提供了一个称作Layer Cubing的算法。简单来说,就是按照
dimension数量从大到小的顺序,从Base Cuboid开始,依次基于上一层Cuboid的结果进行再聚合。每一层的计算都是一个单独的Map Reduce任务。
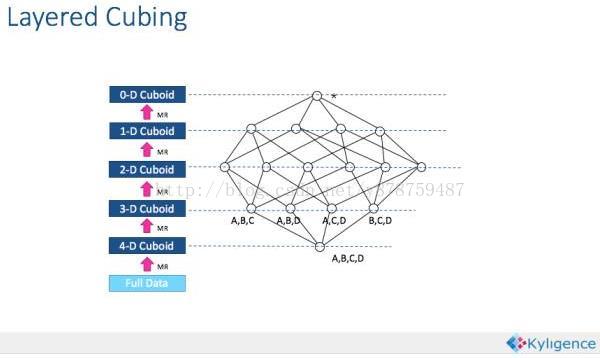
MapReduce的计算结果最终保存到HBase中,HBase中每行记录的Rowkey由dimension组成,measure会保存在column family中。为了减小存储代价,这里会对dimension和messure进行编码。查询阶段,利用HBase列存储的特性就可以保证Kylin有良好的快速响应和高并发。
有了这些预计算的结果,当收到用户的SQL请求,Kylin会对SQL做查询计划,并把本该进行的Join、Sum、Count Distinct等操作改写成Cube的查询操作。
Kylin提供了一个原生的Web界面,在这里,用户可以方便的创建和设置Cube、管控Cube构建进度,并提供SQL查询和基本的结果可视化。
根据公开数据显示,Kylin的查询性能不只是针对个别的SQL,而是对上万种SQL的平均表现,生产环境下90%file查询能够在3s内返回。在上个月举办的Apache Kylin Meetup中,来自美团、京东、百度等互联网公司分享了他们的使用情况。例如在京东云海的案例中,单个Cube最大有8个维度,最大数据条数4亿,最大存储空间800G,30个Cube共占存储空间4
T左右。查询性能上,当QPS在50左右,所有查询平均在200ms以内,当QPS在200左右,平均响应时间在1s以内。
目前,有越来越多的国内外公司将Kylin作为大数据生产环境中的重要组件,如eBay、银联、百度、中国移动等。
Kylin的最新特性
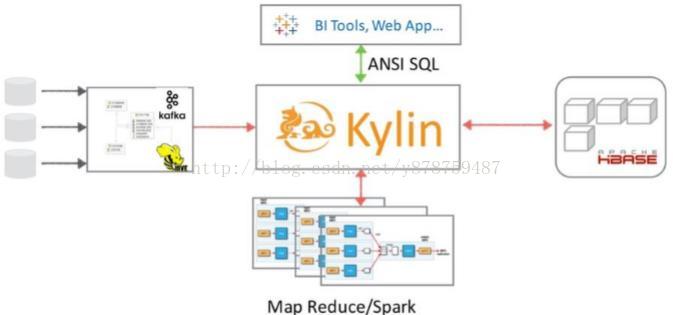
Kylin的最新版本1.5.X引入了不少让人期待的新功能,可扩展架构将Kylin的三大依赖(数据源、Cube引擎)彻底解耦。Kylin将不再直接依赖于Hadoop/HBase/Hive,而是把Kylin作为一个可扩展的平台暴露抽象接口,具体的实现以插件的方式指定所用的数据源、引擎和存储。
开发者和用户可以通过定制开发,将Kylin接入除Hadoop/HBase/Hive以外的大数据系统,比如用kafka代替Hive作数据源,用Spark代替MR做计算引擎,用Cassandra代替HBase做存储,都将变得更为简单。这也保证了Kylin可以随平台技术一起演进,紧跟技术潮流。
在Kylin1.5.x中还对HBase存储结构进行了调整,将大的Cuboid分片存储,将线性扫描改良为并行扫描。基于上万查询进行了测试对比结果显示,分片的存储结构能够极大提速原本较慢的查询5-10倍,但对原本较快的查询提速不明显,综合起来平均提速2倍左右。
除此之外,1.5.x还引入了Fast cubing算法,利用Mapper端计算先完成大数据聚合,再将聚合后的结果交给Reducer,从而降低网络瓶颈的压力。对500多个Cube任务的实验显示,引入Fast cubing后,总体的Cube构建任务提速1.5倍。
kylin的用途
Apache Kylin旨在减少Hadoop在10亿及百亿规模以上数据级别的情况下的查询延迟,目前底层数据存储基于HBase,具有较强的可伸缩性。Apache Kylin为Hadoop数据提供了ANSI-SQL接口,并且支持大多数的ANSI-SQL的函数;能够支持在秒级别延迟的情况下同Hadoop进行交互式查询;支持多维联机分析处理数据仓库(MOLAP
Cube);用户能够定义数据模型;并且通过Apache Kylin能够预建超过10多亿行原始记录的数据模型;可与其他BI工具无缝集成,包括Tableau,Excel,PowerBI等;并提供了JDBC,ODBC接口;可分布式部署,Query Server可以水平扩展,存储基于HBase也可以水平扩展。并且Apache Kylin将在后续版本支持流式近实时Cube计算,支持实时数据多维分析等各种场景。
Kylin介绍,功能特点【转】
原文:https://www.cnblogs.com/qqflying/p/9267018.html