整理之前的学习笔记,看的某视频的记录
爬虫:自己取抓取互联网上的信息的程序。
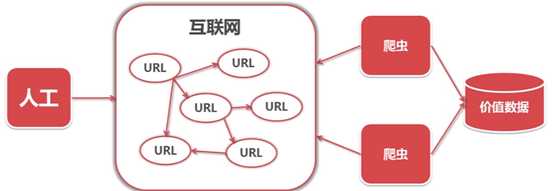
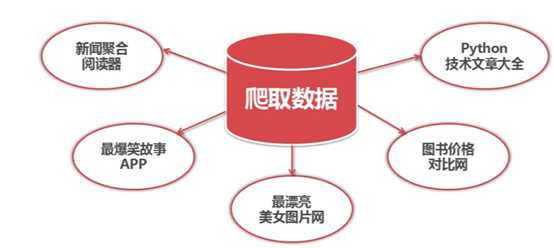
爬虫价值:爬取数据
爬虫的架构
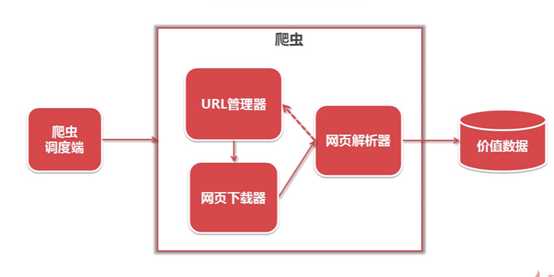
爬虫调度段:启动爬虫,监视爬虫
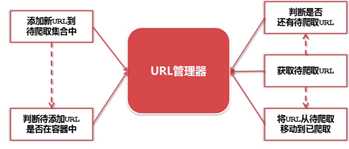
URL管理器:
网页下载器(urllib)
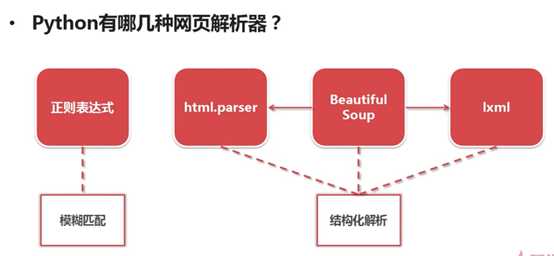
网页解析器(BeautifulSoup)
运行的流程
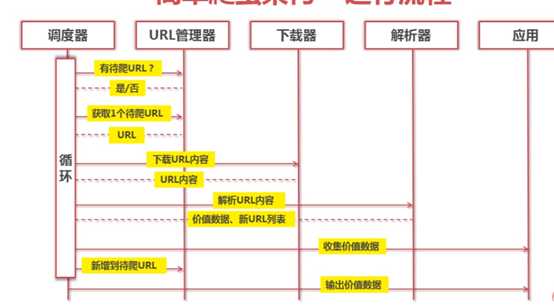
URL管理器:管理待抓取URL集合和已经抓取URL集合
---防止重复抓取/循环抓取
5个最小的功能范围
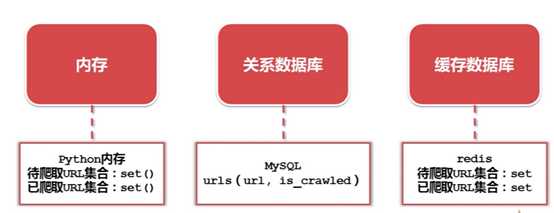
爬到的数据如何存储
实现方式
Python内存
关系数据库
缓存数据库
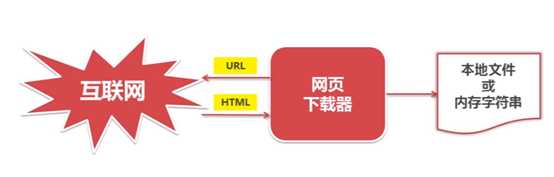
网页下载器: 将互联网上URL对应的网页下载到本地的工具
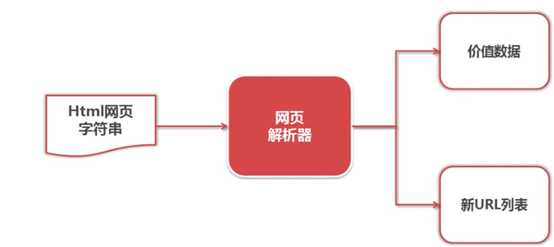
网页解析器:从网页中提取有价值的数据的工具
原文:https://www.cnblogs.com/taoHongFei/p/9291304.html