目录
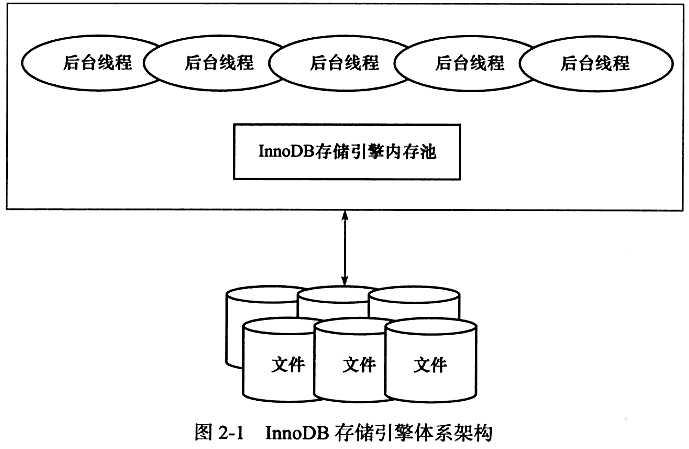
? InnoDB存储引擎有多个内存块,可以认为这些内存块组成了一个大的内存池,负责如下工作:
? 后台线程的主要作用
Master Thread
? 核心线程,主要负责将缓冲池中的数据异步刷新到磁盘,保证数据的一致性,包括脏页的刷新,合并插入缓冲,UNDO页的回收等。
IO Thread
# INNODB版本查询
SHOW VARIABLES LIKE ‘INNODB_VERSION‘\G;
# INNODB THREAD 数量查询
SHOW VARIABLES LIKE ‘innodb_%io_threads‘\G;
# 查询IO THREAD
SHOW ENGINE INNODB STATUS\G;Purge Thread
? 事务被提交后,其所使用的undolog可能不再需要,因此需要PurgeThread来回收已经使用并分配的undo页。从INNODB 1.1版本开始,可以将purge操作从MASTER THREAD中抽离出来,来减轻MASTER THEAD的工作。使用配置开始
[mysqld]
innodb_purge_threads=1? 从INNODB 1.2版本开始,可以支持多个purge Thread,这样做的目的是为了进行加快undo页的回收。例如可以设置4个
SELECT VERSION() \G;
SHOW VARIABLES LIKE ‘innodb_purge_threads‘\G;Page Cleaner Thread
? 是在INNODB 1.2.x版本中引入的。起作用是将之前版本中脏页的刷新操作都放入到单独的线程中来完成。其目的是为简称MASTER THREAD的工作以及对用于查询线程的堵塞,进一步提高性能。
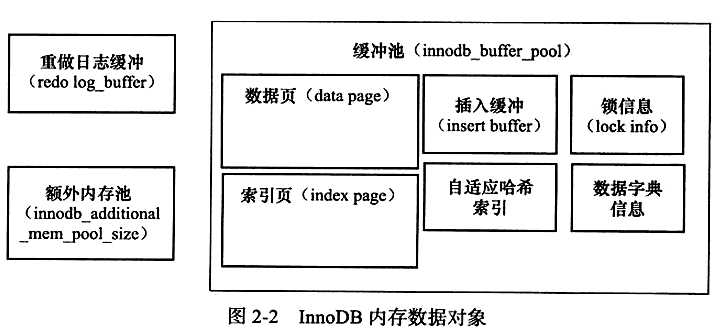
缓冲池
? InnoDB存储引擎是在磁盘按照页的方式进行管理,是基于磁盘的数据库系统。需要使用缓冲池技术提高数据库的整体性能。
? 缓冲池就是一块内存区域,读取先再缓存找,找不到去磁盘加载。写入的是后续通过Checkpoint的机制刷新回磁盘。
SHOW VARIABLES LIKE ‘innodb_buffer_pool_size‘\G;?
? 从1.0.X版本开始,允许有多个缓冲池实例。每个页根据哈希值平均分配到不同缓冲池实例中。好处是减少数据库内部的资源竞争,增加数据库的并发处理能力。
## 查询缓冲池信息、状态
SHOW VARIABLES LIKE ‘innodb_buffer_pool_instances‘\G;
SHOW ENGINE INNODB STATUS\G;
SELECT POOL_ID, POOL_SIZE, FREE_BUFFERS, DATABASES_PAGES
FROM INNODB_BUFFER_POOL_STATUS\G;INNODB内存管理模式——LRU List、Free List(空闲页列表) 和 Flush List(脏页列表)
? InnoDB存储引擎使用LRU算法进行内存管理,不同的是,他最新读取的页不是放在列表的首部,而是放在midpoint的位置。midpoint位置可由参数innodb_old_blocks_pct控制,例如
SHOW VARIABLES LIKE ‘innodb_old_blocks_pct‘\G;? 为什么不是用最基础的LRU算法呢?这是因为某些SQL(例如索引或者数据的扫描操作)可能会将缓冲池中的页被刷新出,影响缓冲池的效率。但是这类SQL的数据使用的页并不是活跃数据。
? 为了更进一步优化这个问题,引入一个新的参数innodb_old_blocks_time,表示页读取到mid位置后需要等待多久才会被加入到LRU列表的热端。所以在执行上述类型的SQL时候,可以先设置这个参数保证原来的LRU列表热点数据不被刷出。
SET GLOBAL innodb_old_blocks_time = 1000;
# 一些操作
.....
SET GLOBAL innodb_old_blocks_time = 0;? 如果用户预估自己热点数据不止63%,可以在执行SQL前改变innodb_old_blocks_pct参数
SET GLOBAL innodb_old_blocks_pct=20;?
? InnoDB开始启动时,LRU加载过程:
innodb_old_blocks_time的设置而导致页没有从old部分移动到new部分的操作称为page not made young。SHOW ENGINE INNODB STATUS\G
# INNODB1.2版本开始,还可以通过表INNODB_BUFFER_POOL_STATUS来观察缓冲池的运行状态
SELECT POOL_ID, HIT_RATE, PAGES_MADE_YOUNG, PAGES_NOT_MADE_YOUNG
FROM information_schema.INNODB_BUFFER_POOL_STATUS\G;
# 通过表INNODB_BUFFER_PAGE_LRU来观察每个LRU列表中每个页的具体信息
SELECT TABLE_NAME, SPACE, PAGE_NUMBER, PAGE_TYPE
FROM INNODB_BUFFER_PAGE_LRU WHERE SPACE = 1;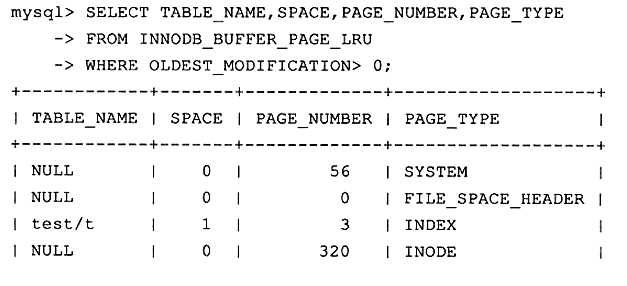
?
? INNODB存储引擎从1.0.X版本开始支持压缩页的功能,即将原来16KB的页压缩为1KB、2KB、4KB和8KB。由于页的大小发生了变化,所以LRU列表也有了些许的变化,对于非16KB的页,是通过unzip_LRU列表进行管理的。通过命令观察得到:
SHOW ENGINE INNODB STATUS\G;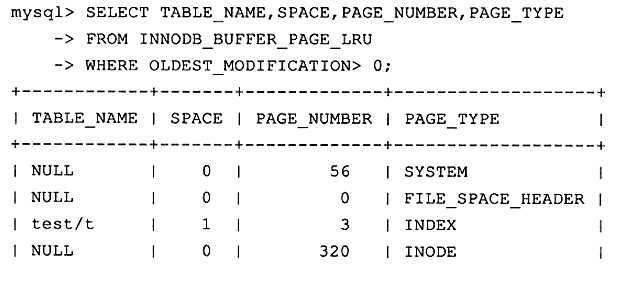
? 这里需要注意的是LRU列表长度包括unzip_LRU列表长度。
? unzip_LRU是怎样从缓冲池中分配内存的呢?
? 首先,在unzip_LRU列表中对不同压缩页大小的页进行分别管理。其次通过伙伴算法进行内存的分配。来如对需要从缓冲池中申请页为4KB的大小的过程如下:
# 观察unzip_LRU列表中的页
SELECT
TABLE_NAME, SPACE, PAGE_NUMBER, COMPERSSID_SIZE
FROM INNODB_BUFFER_PAGE_LRU
WHERE COMPRESSED_SIZE <> 0;? 在LRU列表中的页被修改后,该页成为脏页,即缓冲池中的页和磁盘上的页的数据产生了不一致。这时数据库会通过CHECKPOINT机制将脏页刷新会磁盘。
? Flush列表中的页即为脏页列表。
? 脏页既存在于LRU列表中,也存在与Flush列表中。LRU列表用来管理缓冲池中的页的可用性,Flush列表用来管理将页刷新回磁盘,二者互不影响。
# modified db pages显示脏页的数量
SHOW ENGINE INNODB STATUS
# 可以通过源数据库表INNODB_BUFFER_PAGE_LRU来查看
SELECT TABLE_NAME, SPACE, PAGE_NUMBER, PAGE_TYPE
FROM INNODB_BUFFER_PAGE_LRU
WHERE OLDEST_MODIFICATION > 0;?
重做日志缓冲
? INNODB存储引擎首先将重做日志信息放在这个缓冲区中,然后按照一定的频率刷新到重做日志文件。一般不用设置的很大。因为刷新速度很快。可通过innodb_log_buffer_size控制,默认8MB
SHOW VARIABLES LIKE ‘innodb_log_buffer_size‘\G;? 刷新到磁盘的策略
额外的内存池
? 在INNODB存储引擎中,对内存的管理是通过一种称为内存堆(heap)的方式进行的。在对一些数据结构本身的内存进行分配时,需要从额外的内存池中进行申请,当该区域的内存不够时,也会从缓冲池中进行申请。所以在申请了很大的INNODB缓冲池时,也要相应增加这个数值。
? 一条DML语句会使得产生脏页(内存的数据比磁盘新),那就需要刷新到磁盘中。基本上是采用Write Ahead Log策略。即当事务提交时,先写重做日志,再修改页。当由于发生宕机而导致数据丢失时,通过重做日志来完成数据的恢复。
? 而Checkpoint技术是为了解决这个过程的痛点:
缩短数据库恢复的时间
? 由于checkpoint之前的数据都刷回去磁盘了,所以只需要对checkpoint后的重做日志进行恢复。大大缩短了恢复时间。
缓冲池不够用时,将脏页刷新到磁盘
? LRU算法会溢出最近最少使用的页,如果是脏页,强制Checkpoint。
重做日志不可用时,刷新脏页。
? 重做日志的空间是循环使用的,当要被重用的时候,被重用的部分必须进行checkpoint。
? 在InnoDB存储引擎中,通过LSN(Log Sequence Number)来标记版本的。LSN是8字节的数字。每个页、重做日志、Checkpoint都有LSN。可以通过命令来查看
SHOW ENGINE INNODB STATUS\G;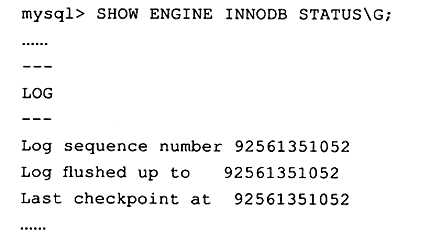
? 在InnoDB存储引擎内部,有两种Checkpoint,分别为:
Sharp Checkpoint
? 是在数据库关闭时刷新全部脏页到磁盘。参数是innodb_fast_shutdown=1
Fuzzy Checkpoint
? 运行时使用,指刷新一部分脏页。
Master Thread Checkpoint
? 每秒或者每十秒刷新从缓冲池的脏页列表中刷新一定比例的页回磁盘。
FLUSH_LRU_LIST Checkpoint
? 是因为InnoDB存储引擎需要保障LRU列表中需要有足够多的空闲页可使用。
? 在InnoDB 1.1.x版本之前,检查LRU列表空间是否足够是在用户查询线程中,会堵塞用户的查询操作。而且如果查询空间不足,会将尾端的页移除,如果有脏页就进行Checkpoint。
? 在InnoDB1.2.x版本开始,这个操作会放在Page Cleaner 线程中进行。
? 可以通过参数进行设置预留的空间大小,设置LRU列表需要保留多少个空闲页的空间
SHOW VARIABLES LIKE ‘innodb_lru_sacn_depth‘\G;?
Async/Sync Flush Checkpoint
? 是指重做日志文件不可用(空间快用完了)的情况,这时需要强制将一些页刷新会磁盘,而此时脏页是从脏页列表中选取的。
? 在INNODB1.2.x版本后,放入到了单独的page Cleaner Thread中。可以通过命令来观察状态
SHOW ENGINE INNODB STATUS\G;Dirty Page too much Checkpoint
? 脏页的数量太多,导致InnoDB强制进行CheckPoint。可以由参数来配置,表示缓冲中脏页的数量占据百分比为多少后,进行脏页的刷新。
SHOW VARIABLES LIKE ‘innodb_max_dirty_pages_pct‘\G;InnoDB 1.0.x版本之前的Master Thread? Master Thread具有最高的线程优先级别,内部由多个循环(loop)组成,会根据运行状态在不同的循环中切换。
loopbackgroup loopflush loopsuspend loop? 包括每秒操作和每十秒操作。
? 每秒操作包括:
日志缓冲刷新到磁盘,即使这个事务还没提交(总是)
合并插入缓冲(可能)
? 判断前一秒发生IO次数是否小于5次,才会执行
至多刷新100个InnoDB的缓冲池中的脏页到磁盘(可能)
// 当前脏页比例
if buf_get_modified_ratio_pct> innodb_max_drity_pages_pct
then
刷新100个脏页到磁盘如果当前没有用户活动,则切换到background loop(可能)
? 每十秒操作包括:
? 以上的操作,都是基于过去10秒内IO次数小于200才会进行。
? 当前没有用户活动或者数据库关闭,就会切换到background loop循环
? 如果flush loop事情完成了,就会切到suspend_loop,将master_thread挂起,等待事件发生
? 可以看出之前版本的代码,做了很多的硬编码,很大程度上限制了InnoDB存储引擎对IO的性能(SSD盘使用后)。所以有时候数量上去后,其实是代码中未充分使用资源,导致性能瓶颈。所以抽出参数供用户来设置调节。
? 原来的规则是:脏页在缓冲池所占的比例小于innodb_max_dirty_pages_pct时,不刷新脏页,大于时,刷新100个脏页。
? 现在的规则是,引擎会通过一个名为buf_flush_get_desired_flush_rate的函数来获取刷新脏页合适的数量。粗略翻阅源代码后发现buf_flush_get_desired_flush_rate通过重做日志的产生速度来决定最合适的刷新脏页的数量。
SHOW VARIABLES LIKE ‘innodb_purge_batch_size‘\G;? 通过命令可以查看当前master thread的状态信息
SHOW ENGINE INNODB STATUS\G;? 对于脏页的刷新操作,分离到一个单独的Page Cleaner Thread,从而减轻了Master Thread的工作。进一步提升了系统的并发性。
原文:https://www.cnblogs.com/BlueMountain-HaggenDazs/p/9297876.html