假设现在有一个二分类问题,输入特征向量\(x\)的每个元素都是连续值,则我们可以将样本标签y的分布(evidence)视为参数为\(\phi\)的伯努利分布:
\[y\sim \mathrm{Bernoulli}(\phi)\]
将\(p(x|y)\)(样本标签为0(1)时,输入特征的分布)视为多元高斯分布:
\[x|y=0\sim \mathcal N (\mu_0,\Sigma)\]
\[x|y=1\sim \mathcal N (\mu_1,\Sigma)\]
写出公式:
\[p(y)=\phi^y(1-\phi)^{1-y}\]
\[p(x|y=0)=\frac 1 {(2\pi)^{\frac n 2}|\Sigma|^{\frac 1 2}}\exp (-\frac 1 2(x-\mu_0)^T\Sigma^{-1}(x-\mu_0))\]
\[p(x|y=1)=\frac 1 {(2\pi)^{\frac n 2}|\Sigma|^{\frac 1 2}}\exp (-\frac 1 2(x-\mu_1)^T\Sigma^{-1}(x-\mu_1))\]
注意:这里的多元高斯分布模型,y=0和y=1时的均值\(\mu_0,\mu_1\)不同,但协方差矩阵是完全一样的
由参数\(\phi,\mu_0,\mu_1,\Sigma\)决定的对数似然
\[l(\phi,\mu_0,\mu_1,\Sigma)=\log \prod_{i=1}^m p(x^{(i)},y^{(i)};\phi,\mu_0,\mu_1,\Sigma)\]
\[=\log \prod_{i=1}^m p(x^{(i)}|y^{(i)};\phi,\mu_0,\mu_1,\Sigma)p(y^{(i)};\phi)\]
通过最大化对数似然函数可得,
\[\phi=\frac 1 m \sum_{i=1}^m1\{y^{(i)}=1\}\]
\[\mu_0=\frac {\sum_{i=1}^m 1\{y^{(i)}=0\}x^{(i)}}{\sum_{i=1}^m 1\{y^{(i)}=0\}}\]
\[\mu_1=\frac {\sum_{i=1}^m 1\{y^{(i)}=1\}x^{(i)}}{\sum_{i=1}^m 1\{y^{(i)}=1\}}\]
\[\Sigma=\frac 1 m \sum_{i=1}^m (x^{(i)}-\mu_{y^{(i)}})(x^{(i)}-\mu_{y^{(i)}})^T\]
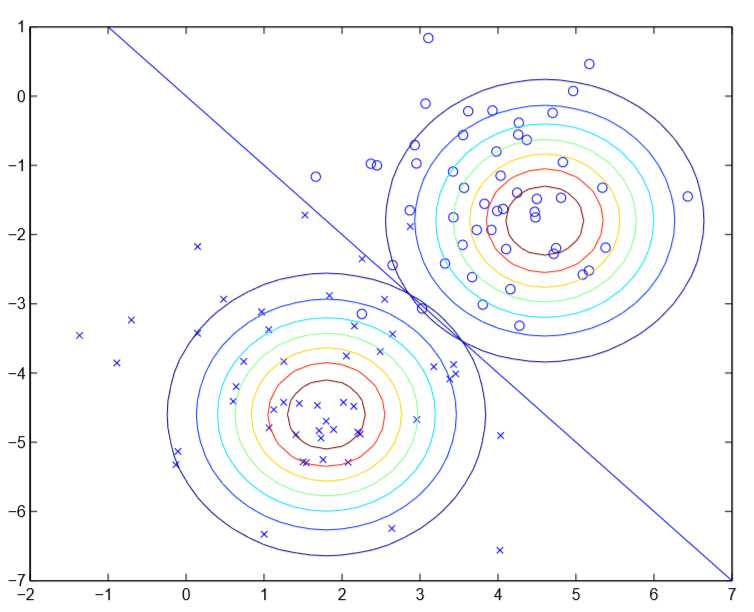
可见图中y=0和1的高斯分布等高线图,除了中心不同以外,其他完全相同。在\(p(y=1|x)>p(y=0|x)\)时,模型输出分类为1,反之为0,使得\(p(y=1|x)=p(y=0|x)=0.5\)的点\(x\)在图中可以构成一条直线(决策边界)
若我们将\(p(y=1|x;\phi,\mu_0,\mu_1,\Sigma)\)视为一个关于n+1维列向量x的函数,则
\[p(y=1|x;\phi,\mu_0,\mu_1,\Sigma)=\frac 1 {1+\exp(-\theta^Tx)}\]
其中\(\theta\)是关于\(\phi,\mu_0,\mu_1,\Sigma\)的函数,上式与逻辑回归的假设函数\(h_\theta(x)=p(y=1|x;\theta)\)是完全一样的
从上面的图可以看出,如果假设\(p(x|y)\)服从多元高斯分布,则可以推出假设\(p(y|x)\)是逻辑回归的假设函数形式;但是如果假设\(p(y|x)\)是逻辑回归的假设函数形式,显然无法推出假设\(p(x|y)\)服从多元高斯分布,决策边界两侧的正负样本分布可以随意,不一定要近似多元高斯分布。
这表明GDA的假设比逻辑回归的假设更强,GDA不仅假设决策边界是线性的,而且假设正样本、负样本服从多元高斯分布,逻辑回归只假设决策边界是线性的
但当正负样本的分布的确满足GDA的假设时,GDA比逻辑回归表现得更高效(asymptotically efficient),即,在训练样本数目很少时,GDA的准确率更高。
反之,由于逻辑回归的假设更弱,因此逻辑回归表现得更鲁棒、受输入数据的分布特性的影响更小,在对非高斯分布(non-Gaussian)的数据时表现更好,因此一般来讲,逻辑回归比GDA用得更多
CS229 Machine Learning学习笔记(第5~8集)
原文:https://www.cnblogs.com/qpswwww/p/9308786.html