传统的语言模型在预测序列中的下一个单词时只会考虑到前面的有限个单词,RNN与之不同,RNN网络会根据前面已经出现的所有输入来调整整个网络。下图是RNN网络的典型结构:

Xt表示在t时刻的输入,ht表示t时刻的隐藏层状态,yt表示t时刻的输出。每一个隐藏层都有许多的神经元,这些神经元将上一层的输入做线性变换(矩阵乘法,也就是乘以权重),然后再使用非线性激活函数进行激活。t时刻的输入Xt和t-1时刻的隐藏层状态作为t时刻隐藏层的输入,并由隐藏层产生t时刻的输出特征ht,再对ht使用全连接和softmax作为最终的输出。用公式表示如下:
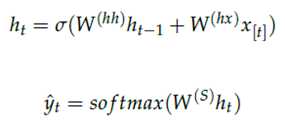
RNN网络中的损失函数通常定义为交叉熵损失函数,假设序列长度为T,词库的大小为V,那么在时间步长为t时的损失可以表示为:

在整个时间步长内,损失函数可表示为:

语言模型效果好坏的评价指标通常是复杂度,其计算公式如下:
![]()
复杂度越低,模型预测的序列中下一个词的可信度就越高。
梯度消失和梯度爆炸问题
在RNN网络中,权重矩阵从一个时间步长被传递到下一个时间步长。在反向传播的过程中,计算损失函数在t时刻的梯度需要将从0时刻到t时刻的所有梯度相加,而越早时刻的梯度越可能会出现梯度弥散或者梯度爆炸的现象。下面我们从数学角度来分析一下这一现象:
为计算损失函数对权重的梯度,我们需要将每一个时间步长处的损失累加起来,用公式表示为: ,在每一个时刻时,我们使用链式法则可以将误差对权重的导数表示为:
,在每一个时刻时,我们使用链式法则可以将误差对权重的导数表示为:

需要注意的是![]() 是ht对之前每一个时间步长(1<=k<=t)处的的偏导数,对于使用链式法则将其展开为:
是ht对之前每一个时间步长(1<=k<=t)处的的偏导数,对于使用链式法则将其展开为:

因为hj是一个n维向量,所以是一个n*n维的矩阵,将上面几个式子整合在一起可以得到:


这里![]() 分别表示权重矩阵和导数对角矩阵的L2范数的上界。所以有:
分别表示权重矩阵和导数对角矩阵的L2范数的上界。所以有:

表达式的最右边是一个指数函数,当![]() 大于1或者小于1时,随着序列长度的增加,很容易发生梯度爆炸和梯度弥散的现象。在训练过程中,梯度爆炸很容易被检测到,因为计算机能够表示的数是有限的,而当发生梯度弥散时,模型的学习效果会下降。
大于1或者小于1时,随着序列长度的增加,很容易发生梯度爆炸和梯度弥散的现象。在训练过程中,梯度爆炸很容易被检测到,因为计算机能够表示的数是有限的,而当发生梯度弥散时,模型的学习效果会下降。
解决梯度弥散、爆炸的方法
下图展示了RNN网络损失函数对权重和偏置的关系图。

从图中可以看见,图中存在一个非常陡峭的面,在更新参数的过程中,如果当前参数所处的位置刚好位于这个高高的“误差墙”上,由于这个面上的梯度非常大,那么采用梯度下降法更新后的参数可能就跑得很远,如图中蓝色的实线所示。因此,为了解决这个问题,gradient clipping算法为梯度的范数设置了一个阈值,当梯度的范数大于某个值的时候,将梯度设置为这个阈值,算法描述如下:

但是这个方法也存在一个问题:只能够解决梯度爆炸的问题,而不能够解决梯度弥散的问题。为了结局梯度弥散的问题,我们引入了两种技术:
1、 对于隐层态的权重矩阵Whh使用单位矩阵进行初始化而不是随机初始化;
2、 使用RELU激活函数而不是Sigmoid激活函数,因为RELU函数的导数为0或者1,在反向传播的过程中不会衰减至0。
深度双向RNN网络
上面我们谈到的RNN网络是根据过去时刻的单词来预测下一个单词,其实我们也可以根据未来的单词来预测这一个单词。双向RNN网络就是这样的结构,其结构示意图如下所示:

这个网络有两个隐藏层,一个从右向左传播,另一个从左向右传播;由于网络的权重和偏置参数是单向RNN网络的两倍,所以这个网络也需要两倍的内存空间来存储参数。最终的输出结果则是将这两个隐藏层的输出组合起来。数学表达式如下:

RNN机器翻译模型
传统的翻译模型十分复杂,在翻译的不同阶段使用了大量不同的机器学习算法。这里我们使用RNN网络来构建一种翻译模型作为传统翻译模型的替代。该模型的网络结构如下:

这个网络前3个时间步长将源语言进行编码,提取特征,后面两个时间步长将h3解码输出为目标语言。数学表达式如下:

第一个方程表示编码的过程,第二个方程和第三个方程表示解码过程。
损失函数使用交叉熵损失。事实上,这个网络的实际表现并不是那么令人满意,在实际应用中,通常会有下面这几个改进:
1、 在训练过程中,编码和解码使用的权重分别采用独立的不同的值,这相当于将两组权重解耦和,从而能够获得更高的正确率;
2、 在解码器的训练过程中使用三种不同的输入:上一时刻的预测结果、上一时刻的隐藏态和编码器中最后时刻的隐藏态,即:ht= f(ht-1, c, yt-1);
3、 使用更深的更多层的循环神经网络,因为更深的神经网络有着更强的学习能力,能够提升预测的精确度;
4、 训练双向的编码器网络;
5、 如果一个句子ABC经翻译后的结果为DEF,那么我们在训练的过程中可以将输入的序列顺序改为CBA,因为直观地讲,A被翻译为D的可能性较大,这样可以降低翻译的错误率;
如何解决梯度爆炸和梯度弥散问题
一般的RNN网络会存在梯度弥散和梯度爆炸问题,梯度爆炸的问题可以通过使用Gradient Clipping的方法来解决,而梯度弥散的问题则需要重新设计RNN的网络结构。GRU和LSTM就是为了解决梯度弥散的问题而设计的。
GRU
门控循环单元的结构如下所示:

一般的循环神经网络在理论上虽然可以获得长期依赖,但是在实际训练过程中却很难做到。GRU拥有更持久的记忆,因而能够更容易地获得长期依赖。其数学表达式如下:

1、 产生新的记忆:将新的输入xt和上一时刻的隐藏态结合起来产生我内心的记忆;
2、 重置门:重置门的作用是决定上一时刻的隐藏态在产生新的记忆过程中的重要程度,当它发现过去的隐藏态与新的记忆无关时,它可以完全消除过去的隐藏态对产生新的记忆的影响;
3、 更新门:更新门决定了上一时刻的隐藏态对当前时刻隐藏态的重要程度;当zt=0时,新的隐藏态全部由新产生的记忆组成,而当zt=1时,新的隐藏态与过去的隐藏态完全一样;
4、 隐藏态:隐藏态由更新门的值、新的记忆值和上一时刻的隐藏态共同决定;
需要注意的是,在训练GRU的过程中,W、U、W(r)、U(r)、 W(z)、U(z)全部都是需要学习的参数。
LSTM
LSTM是另一种复杂的激活单元,它和GRU有些许不同。设计LSTM的目的和GRU类似。LSTM的结构示意图如下:

另一种图像化表达形式:

其数学表达式为:

1、 产生新的记忆: 使用t时刻的输入和上一时刻的隐藏态来计算新的记忆;
2、 输入门:在产生新的记忆时,我们发现网络并不会去检查新的输入对于新时刻的记忆有多重要,而输入门的意义就在这里,它将新的输入和上一时刻的隐藏态作为输入来计算it,it被用来控制新产生的记忆对新时刻下最终记忆的贡献程度;
3、 遗忘门:遗忘门的作用与输入门类似,但是遗忘门不是用来检查新时刻的输入,而是用来控制上一时刻的最终记忆对于新时刻的最终记忆状态的贡献程度;
4、 最终记忆:最终记忆的产生依赖于输入门和遗忘门的输出以及上一时刻的最终记忆和新时刻产生的新记忆,它是将上一时刻的最终记忆和新时刻产生的新记忆综合后的结果;
这里遗忘门的输出ft和上一时刻的记忆状态Ct-1是逐元素相乘,而不是矩阵相乘,输入门it与新产生的记忆![]() 之间也是逐元素相乘的;
之间也是逐元素相乘的;
5、 输出门:这个门在GRU里不存在,这个门的作用是将最终记忆与隐藏态分离开来;最终记忆里包含了大量的不需要在隐藏态里保存的信息,因此输出们的作用是决定最终记忆里哪些部分需要被暴露在隐藏态中。
LSTM能够解决梯度弥散和梯度爆炸问题的原因
1、 遗忘门与上一时刻的记忆之间是矩阵元素相乘,而不是矩阵相乘;
2、 遗忘门在不同的时间步长会取不同的值;
3、 遗忘门的激活函数是sigmoid函数,值域范围为(0,1)。
原文:https://www.cnblogs.com/puheng/p/9379730.html