
# 个人站点 http://www.cnblogs.com/wh1520577322/ http://www.cnblogs.com/liucong12345/ http://www.cnblogs.com/kin1492/
url
# 个人站点页面设计 re_path(r‘^(?P<username>\w+)$‘, views.home_site, name=‘home_site‘),
view

404.html
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> <link rel="stylesheet" href="/static/blog/bs/css/bootstrap.css"> </head> <body> <div class="container" style="margin-top: 100px"> <div class="text-center"> <a href="http://www.cnblogs.com/"><img src="/static/img/log_small.gif" alt="cnblogs"></a> <p><b>404.</b> 抱歉! 您访问的资源不存在!</p> <p class="d">请确认您输入的网址是否正确,如果问题持续存在,请发邮件至 404042726@qq.com 与 <strong style="font-size: 28px">老村长</strong> 联系。</p> <p><a href="/">返回网站首页</a></p> </div> </div> </body> </html>

(2)查询当前站点对应的所有文章

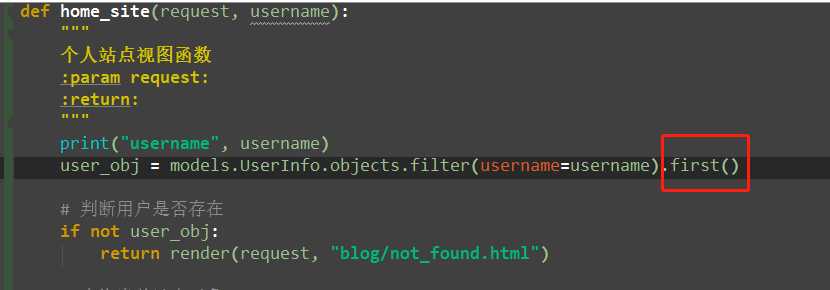
def home_site(request, username): """ 个人站点视图函数 :param request: :return: """ print("username", username) user_obj = models.UserInfo.objects.filter(username=username).exists() # 判断用户是否存在 if not user_obj: return render(request, "blog/not_found.html") # 查询当前站点对象 blog = user_obj.blog # 当前用户或者当前站点对应的所有文章 # 方式1:基于对象查询 article_list = user_obj.article_set.all() # 方式2:基于__ article_list = models.Article.objects.filter(user=user_obj) return render(request, ‘blog/home_site.html‘)
# 跨表的分组查询的模型:
# 每一个后的表模型.objects.values("pk").annotate(聚合函数(关联表__统计字段)).values("表模型的所有字段以及统计字段") # 推荐pk字段查找
# 查询每一个分类名称以及对应的文章数
# 查询当前站点的每一个分类名称以及对应的文章数
# 查询当前站点的每一个标签名称以及对应的文章数
# 查询当前站点每一个年月的名称以及对应的文章数








# 查询每一个分类名称以及对应的文章数 # 全部blog的 ret1 = models.Category.objects.values(‘pk‘).annotate(c=Count("article__title")).values("title", ‘c‘) print(ret1) # 查询当前站点的每一个分类名称以及对应的文章数 # 只取当前用户站点的 # ret1 = models.Category.objects.filter(blog=blog).values(‘pk‘).annotate(c=Count("article__title")).values("title",‘c‘) ret1 = models.Category.objects.filter(blog=blog).values(‘pk‘).annotate(c=Count("article__title")).values_list("title", ‘c‘) print(ret1)











1 date_format ============date,time,datetime=========== create table t_mul(d date,t time,dt datetime); insert into t_mul values(now(),now(),now()); select * from t_mul; mysql> select * from t_mul; +------------+----------+---------------------+ | d | t | dt | +------------+----------+---------------------+ | 2017-08-01 | 19:42:22 | 2017-08-01 19:42:22 | +------------+----------+---------------------+ 1 row in set (0.00 sec) select date_format(dt,"%Y/%m/%d") from t_mul;




extra(select=None, where=None, params=None, tables=None, order_by=None, select_params=None) 有些情况下,Django的查询语法难以简单的表达复杂的 WHERE 子句,对于这种情况, Django 提供了 extra() QuerySet修改机制 — 它能在 QuerySet生成的SQL从句中注入新子句 extra可以指定一个或多个 参数,例如 select, where or tables. 这些参数都不是必须的,但是你至少要使用一个!要注意这些额外的方式对不同的数据库引擎可能存在移植性问题.
(因为你在显式的书写SQL语句),除非万不得已,尽量避免这样做
参数之select
The select 参数可以让你在 SELECT 从句中添加其他字段信息,它应该是一个字典,存放着属性名到 SQL 从句的映射。 queryResult=models.Article .objects.extra(select={‘is_recent‘: "create_time > ‘2017-09-05‘"}) 结果集中每个 Entry 对象都有一个额外的属性is_recent, 它是一个布尔值,表示 Article对象的create_time 是否晚于2017-09-05.
练习: in sqlite: article_obj=models.Article.objects .extra(select={"standard_time":"strftime(‘%%Y-%%m-%%d‘,create_time)"}) .values("standard_time","nid","title") print(article_obj) # <QuerySet [{‘title‘: ‘MongoDb 入门教程‘, ‘standard_time‘: ‘2017-09-03‘, ‘nid‘: 1}]>








# 查询当前站点每一个年月的名称以及对应的文章数 # 查看最近发布的文章 ret1 = models.Article.objects.extra(select={‘is_recent‘:"create_time > 2018-07-28"}).values(‘title‘, ‘is_recent‘) # print(ret1) # 查看这个月发布的文章 ret1 = models.Article.objects.extra(select={‘y_m_date‘:"date_format(create_time,‘%%Y-%%m‘)"}).values(‘title‘, ‘y_m_date‘) # print(ret1) # 统计年月日 ret1 = models.Article.objects.extra(select={‘y_m_date‘:"date_format(create_time,‘%%Y-%%m‘)"}).values(‘y_m_date‘).annotate(c=Count(‘nid‘)).values_list(‘y_m_date‘, ‘c‘) #(只统计本站点,用户的) ret1 = models.Article.objects.filter(user=user_obj).extra(select={‘y_m_date‘:"date_format(create_time,‘%%Y-%%m‘)"}).values(‘y_m_date‘).annotate(c=Count(‘nid‘)).values_list(‘y_m_date‘, ‘c‘) print(ret1)

4 日期归档查询的方式2 from django.db.models.functions import TruncMonth Sales.objects .annotate(month=TruncMonth(‘timestamp‘)) # Truncate to month and add to select list .values(‘month‘) # Group By month .annotate(c=Count(‘id‘)) # Select the count of the grouping .values(‘month‘, ‘c‘) # (might be redundant, haven‘t tested) select month and count

# 时区选择 # TIME_ZONE = ‘UTC‘ TIME_ZONE = ‘Asia/Shanghai‘ USE_I18N = True USE_L10N = True # 转换时区 # USE_TZ = True USE_TZ = False


# 方式2: from django.db.models.functions import TruncMonth ret1 = models.Article.objects.filter(user=user_obj).annotate(month=TruncMonth(‘create_time‘)).values(‘month‘).annotate(c=Count(‘nid‘)).values_list(‘month‘,‘c‘) print(ret1)

def home_site(request, username): """ 个人站点视图函数 :param request: :return: """ # print("username", username) user_obj = models.UserInfo.objects.filter(username=username).first() # 判断用户是否存在 if not user_obj: return render(request, "blog/not_found.html") # 查询当前站点对象 blog = user_obj.blog # 当前用户或者当前站点对应的所有文章 # 方式1:基于对象查询 article_list = user_obj.article_set.all() # 方式2:基于__ article_list = models.Article.objects.filter(user=user_obj) # 跨表的分组查询的模型: # 每一个后的表模型.objects.values("pk").annotate(聚合函数(关联表__统计字段)).values("表模型的所有字段以及统计字段") # 推荐pk字段查找 from django.db.models import Avg, Max, Min, Count, F, Q # 查询每一个分类名称以及对应的文章数 # 全部blog的 ret1 = models.Category.objects.values(‘pk‘).annotate(c=Count("article__title")).values("title", ‘c‘) # print(ret1) # 查询当前站点的每一个分类名称以及对应的文章数 # 只取当前用户站点的 # ret1 = models.Category.objects.filter(blog=blog).values(‘pk‘).annotate(c=Count("article__title")).values("title",‘c‘) ret1 = models.Category.objects.filter(blog=blog).values(‘pk‘).annotate(c=Count("article__title")).values_list("title", ‘c‘) # print(ret1) # 查询当前站点的每一个标签名称以及对应的文章数 ret = models.Tag.objects.values(‘pk‘).annotate(c=Count(‘article‘)).values_list(‘title‘,‘c‘) ret1 = models.Tag.objects.filter(blog=blog).values(‘pk‘).annotate(c=Count(‘article‘)).values_list(‘title‘,‘c‘) # print(ret) # print(ret1) # 查询当前站点每一个年月的名称以及对应的文章数 # 查看最近发布的文章 ret1 = models.Article.objects.extra(select={‘is_recent‘:"create_time > 2018-07-28"}).values(‘title‘, ‘is_recent‘) # print(ret1) # 查看这个月发布的文章 ret1 = models.Article.objects.extra(select={‘y_m_date‘:"date_format(create_time,‘%%Y-%%m‘)"}).values(‘title‘, ‘y_m_date‘) # print(ret1) # 统计年月日 ret1 = models.Article.objects.extra(select={‘y_m_date‘:"date_format(create_time,‘%%Y-%%m‘)"}).values(‘y_m_date‘).annotate(c=Count(‘nid‘)).values_list(‘y_m_date‘, ‘c‘) #(只统计本站点,用户的) ret1 = models.Article.objects.filter(user=user_obj).extra(select={‘y_m_date‘:"date_format(create_time,‘%%Y-%%m‘)"}).values(‘y_m_date‘).annotate(c=Count(‘nid‘)).values_list(‘y_m_date‘, ‘c‘) # print(ret1) # 方式2: from django.db.models.functions import TruncMonth ret1 = models.Article.objects.filter(user=user_obj).annotate(month=TruncMonth(‘create_time‘)).values(‘month‘).annotate(c=Count(‘nid‘)).values_list(‘month‘,‘c‘) print(ret1) return render(request, ‘blog/home_site.html‘)
6
7
原文:https://www.cnblogs.com/venicid/p/9380448.html