数据导入可见:《Python之Pandas知识点》
此文图方便,就直接输入数据了。
import pandas as pd
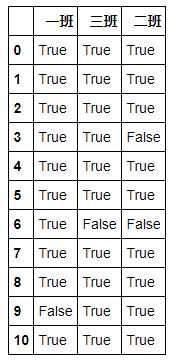
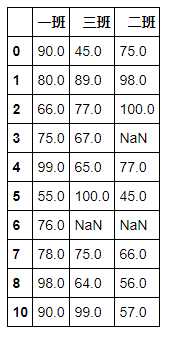
df = pd.DataFrame({‘一班‘:[90,80,66,75,99,55,76,78,98,None,90],
‘二班‘:[75,98,100,None,77,45,None,66,56,80,57],
‘三班‘:[45,89,77,67,65,100,None,75,64,88,99]})
# 如何判断缺失值 df.isnull() # isna() df.notnull() # notna()
DataFrame.dropna(axis=0, how=‘any‘, thresh=None, subset=None, inplace=False)
# 删除第九行 df.fropna(axis=0, how=‘any‘, subset=[‘一班‘])
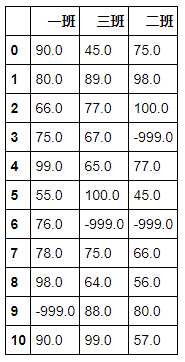
DataFrame.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None)
df.fillna(-999)
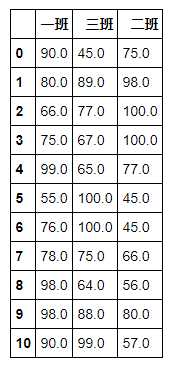
# 分别填补 df.fillna({‘一班‘:-60,‘二班‘:-70,‘三班‘:-80})
# 将每一列的空值插补为该列的均值 df.fillna(df.mean())
# 用上一个数值进行填补 df.fillna(method = ‘ffill‘)
删除法简单易行,但是会引起数据结构变动,样本减少;而替换法使用难度较低,但是会影响数据的标准差,导致信息量变动。在面对数据缺失问题时,除了这两种方法之外,还有一种常用的方法——插值法。
# 默认是线性插值linear df.interpolate()
常用的插值法有线性插值、多项式插值、样条插值等。
from scipy.interpolate import interp1d # 注意这里是数字1,不是l num = df[‘一班‘][df[‘一班‘].notnull()] # 不为空的数据 LinearInsValue1 = interp1d(linear.index, linear.values, kind=‘linear‘) LinearInsValue1(df[‘一班‘][df[‘一班‘].isnull()].index)
from scipy.interpolate import lagrange LagInsValue = lagrange(linear.index, linear.values) # 没有kind形参 LagInsValue(df[‘一班‘][df[‘一班‘].isnull()].index)
from scipy.interpolate import spline # sp 线 # 代码合为一行了 spline(linear.index, linear.values, xnew=df[‘一班‘][df[‘一班‘].isnull()].index)
原文:https://www.cnblogs.com/WoLykos/p/9357639.html