延迟加载
1、延迟加载:先从单表查询、需要时再从关联表去关联查询,大大提高 数据库性能,因为查询单表要比关联查询多张表速度要快。
2、如果查询角色并且关联查询动漫信息。如果先查询角色信息即可满足要求,当我们需要查询动漫信息时再查询动漫信息。把对动漫信息的按需去查询就是延迟加载。
3、resultMap可以实现高级映射(使用association、collection实现一对一及一对多映射),association、collection具备延迟加载功能。
4、使用association实现延迟加载
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <!-- namespace命名空间,作用就是对sql进行分类化管理,理解sql隔离 注意:使用mapper代理方法开发,namespace有特殊重要的作用--> <mapper namespace="ecut.association.mapper.RoleMapperComic"> <resultMap type="Comic" id="ComicResultMap"> <id column="id" property="id"/> <result column="comic_name" property="comicName"/> <result column="remark" property="remark"/> </resultMap> <!-- 延迟加载的resultMap --> <resultMap type="Role" id="RoleLazyResultMap"> <!-- 配置映射的角色信息 --> <!-- id:指定查询列中的唯 一标识,角色信息的中的唯 一标识,如果有多个列组成唯一标识,配置多个id column:角色信息的唯 一标识 列 property:角色信息的唯 一标识 列所映射到Role中哪个属性 --> <id column="id" property="id"/> <result column="role_name" property="roleName"/> <result column="comic_id" property="comicId"/> <result column="note" property="note"/> <!-- 实现对动漫信息进行延迟加载 select:指定延迟加载需要执行的statement的id(是根据comic_id查询动漫信息的statement) 要使用映射文件中findComicById完成根据动漫id(comic_id)动漫信息的查询,如果findComicById不在本mapper中需要前边加namespace column:角色信息中关联动漫信息查询的列,是comic_id 关联查询的sql理解为: SELECT t_role.*, (SELECT comic_name FROM t_comic WHERE t_comic.id = t_role.id)comicName, (SELECT remark FROM t_comic WHERE t_comic.id = t_role.id)remark FROM t_comic --> <association property="comic" javaType="Comic" select="findComicById" column="comic_id"/> <!-- 实现对动漫信息进行延迟加载 --> </resultMap> <!-- 查询角色关联查询动漫信息 ,使用resultMap和延迟加载, 动漫信息需要延迟加载 --> <select id="findRoleComicsByLazyLoading" resultMap="RoleLazyResultMap"> SELECT * FROM t_role </select> <select id="findComicById" parameterType="java.lang.Integer" resultMap="ComicResultMap"> SELECT * FROM t_comic WHERE id = #{value} </select> </mapper>
需要定义两个mapper的方法对应的statement。
a、只查询角色信息
SELECT * FROM t_role
在查询角色的statement中使用association去延迟加载(执行)下边的satatement(关联查询动漫信息)
b、关联查询动漫信息
通过上边查询到的角色信息中comic_id去关联查询动漫信息,使用配置文件中的findComicById
上边先去执行findRoleComicsByLazyLoading,当需要去查询动漫的时候再去执行findComicById,通过resultMap的定义将延迟加载执行配置起来,
使用association中的select指定延迟加载去执行的statement的id。
接口类
package ecut.association.mapper; import java.util.List; import ecut.association.po.Comic; import ecut.association.po.Role; import ecut.association.po.RoleComic; public interface RoleMapperComic {
//根据id查询动漫
public Comic findComicById(Integer id) throws Exception ; //查询角色信息,关联查询所属动漫信息,使用resultMap和延迟加载 public List<Role> findRoleComicsByLazyLoading() throws Exception ; }
<!-- 全局配置参数,需要时再设置 --> <settings> <!-- 打开延迟加载 的开关 --> <setting name="lazyLoadingEnabled" value="true"/> <!-- 将积极加载改为消极加载即按需要加载 --> <setting name="aggressiveLazyLoading" value="false"/> </settings>
在配置文件中开启延迟查询(默认false),并将积极加载改为消极加载(默认true)
package ecut.association.test; import java.io.IOException; import java.io.InputStream; import java.util.List; import org.apache.ibatis.io.Resources; import org.apache.ibatis.session.SqlSession; import org.apache.ibatis.session.SqlSessionFactory; import org.apache.ibatis.session.SqlSessionFactoryBuilder; import org.junit.Before; import org.junit.Test; import ecut.association.mapper.RoleMapperComic; import ecut.association.po.Comic; import ecut.association.po.Role; import ecut.association.po.RoleComic; public class ComicMapperTest { private SqlSessionFactory factory; @Before public void init() throws IOException { String resource = "ecut/association/mybaits-config.xml"; InputStream inputStream = Resources.getResourceAsStream(resource); SqlSessionFactoryBuilder builer =new SqlSessionFactoryBuilder(); factory = builer.build(inputStream); } @Test public void testFindRoleComicsByLazyLoading() throws Exception { SqlSession session = factory.openSession(); RoleMapperComic mapper = session.getMapper(RoleMapperComic.class); List<Role> roleComics = mapper.findRoleComicsByLazyLoading(); //执行getComic()去查询动漫信息,这里实现按需懒加载 System.out.println(roleComics); } }
执行上边mapper方法(findRoleComicsByLazyLoading),内部去调用映射文件中的findComicById只查询角色信息(单表)。
在程序中去遍历上一步骤查询出的List<Role>,当我们调用roleComics中的getComic方法时,开始进行延迟加载。
延迟加载,去调用映射文件中findComicById这个方法获取动漫信息。
DEBUG [main] - ==> Preparing: SELECT * FROM t_role DEBUG [main] - ==> Parameters: DEBUG [main] - <== Total: 7 DEBUG [main] - ==> Preparing: SELECT * FROM t_comic WHERE id = ? DEBUG [main] - ==> Parameters: 1(Integer) DEBUG [main] - <== Total: 1 DEBUG [main] - ==> Preparing: SELECT * FROM t_comic WHERE id = ? DEBUG [main] - ==> Parameters: 2(Integer) DEBUG [main] - <== Total: 1 DEBUG [main] - ==> Preparing: SELECT * FROM t_comic WHERE id = ? DEBUG [main] - ==> Parameters: 3(Integer) DEBUG [main] - <== Total: 1 [ 角色信息:id =1,roleName =Saber, note = fate stay night, comicId = 1;动漫信息:id=1,comicName=null,remark=null, 角色信息:id =2,roleName =鸣人, note = 火影忍者, comicId = 2;动漫信息:id=2,comicName=null,remark=null, 角色信息:id =3,roleName =佐助, note = 火影忍者, comicId = 2;动漫信息:id=2,comicName=null,remark=null, 角色信息:id =4,roleName =赤丸, note = 火影忍者, comicId = 2;动漫信息:id=2,comicName=null,remark=null, 角色信息:id =5,roleName =兜, note = 火影忍者, comicId = 2;动漫信息:id=2,comicName=null,remark=null, 角色信息:id =6,roleName =鹿丸, note = 火影忍者, comicId = 2;动漫信息:id=2,comicName=null,remark=null, 角色信息:id =7,roleName =萨博, note = 海贼王, comicId = 3;动漫信息:id=3,comicName=null,remark=null]
先查询角色表然后根据comi_id去查询动漫表,查询了三次因为有三个不同的comic_id,相同的comic_id不会调用查询因为会存在缓存。
4、不使用mybatis提供的association及collection中的延迟加载功能,如何实现延迟加载??
查询缓存
1、mybatis提供查询缓存,用于减轻数据压力,提高数据库性能。
2、mybaits提供一级缓存,和二级缓存。

3、作用:如果缓存中有数据就不用从数据库中获取,大大提高系统性能。
一级缓存
1、工作原理

2、测试案例
mybatis默认支持一级缓存,不需要在配置文件去配置。
package ecut.association.test; import java.io.IOException; import java.io.InputStream; import java.util.List; import org.apache.ibatis.io.Resources; import org.apache.ibatis.session.SqlSession; import org.apache.ibatis.session.SqlSessionFactory; import org.apache.ibatis.session.SqlSessionFactoryBuilder; import org.junit.Before; import org.junit.Test; import ecut.association.mapper.RoleMapperComic; import ecut.association.po.Comic; import ecut.association.po.Role; import ecut.association.po.RoleComic; public class RoleMapperComicTest { private SqlSessionFactory factory; @Before public void init() throws IOException { String resource = "ecut/association/mybaits-config.xml"; InputStream inputStream = Resources.getResourceAsStream(resource); SqlSessionFactoryBuilder builer =new SqlSessionFactoryBuilder(); factory = builer.build(inputStream); } // 一级缓存测试 @Test public void testCache1() throws Exception { SqlSession session = factory.openSession();// 创建代理对象 RoleMapperComic mapper = session.getMapper(RoleMapperComic.class); // 下边查询使用一个SqlSession // 第一次发起请求,查询id为1的动漫 Comic comic1 = mapper.findComicById(1); System.out.println("动漫信息:id="+comic1.getId()+",comicName="+comic1.getComicName()+",remark="+comic1.getRemark()); // 如果session去执行commit操作(执行插入、更新、删除),清空SqlSession中的一级缓存,这样做的目的为了让缓存中存储的是最新的信息,避免脏读。 /*// 更新comic1的信息 comic1.setComicName("fate"); mapper.updateComic(comic1); //执行commit操作去清空缓存 session.commit();*/ // 第二次发起请求,查询id为1的动漫 Comic comic2 = mapper.findComicById(1); System.out.println("动漫信息:id="+comic2.getId()+",comicName="+comic2.getComicName()+",remark="+comic2.getRemark()); session.close(); } }
第二次查询直接从缓存中获取没有查询数据库,若进行了update操作缓存中的数据被清空,第二次查询需要重新查询数据库
3、应用场景
正式开发,是将mybatis和spring进行整合开发,事务控制在service中。一个service方法中包括 很多mapper方法调用。
二级缓存
1、工作原理
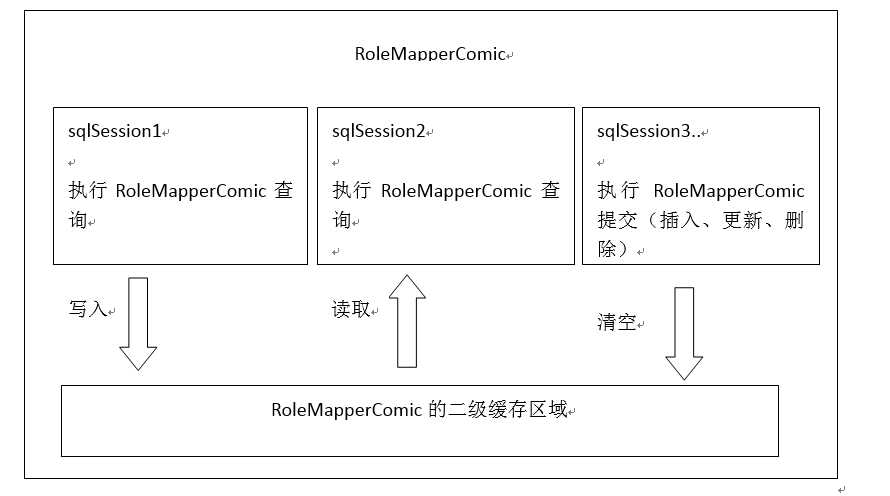
2、测试案例
<!-- 全局配置参数,需要时再设置 --> <settings> <!-- 打开延迟加载 的开关 --> <setting name="lazyLoadingEnabled" value="true"/> <!-- 将积极加载改为消极加载即按需要加载 --> <setting name="aggressiveLazyLoading" value="false"/> <!-- 开启二级缓存 --> <setting name="cacheEnabled" value="true"/> </settings>
mybaits的二级缓存是mapper范围级别,除了在SqlMapConfig.xml设置二级缓存的总开关,还要在具体的mapper.xml中开启二级缓存。
<cache />
在RoleMapperComic.xml中开启二缓存,RoleMapperComic.xml下的sql执行完成会存储到它的缓存区域(HashMap)。
package ecut.association.po; import java.io.Serializable; import java.util.List; public class Comic implements Serializable { private static final long serialVersionUID = -3674954993814032572L; private Integer id; private String comicName; private String remark; private List<Role> roles; public Integer getId() { return id; } public void setId(Integer id) { this.id = id; } public String getComicName() { return comicName; } public void setComicName(String comicName) { this.comicName = comicName; } public String getRemark() { return remark; } public void setRemark(String remark) { this.remark = remark; } public List<Role> getRoles() { return roles; } public void setRoles(List<Role> roles) { this.roles = roles; } }
为了将缓存数据取出执行反序列化操作,因为二级缓存数据存储介质多种多样,不一样在内存。
package ecut.association.test; import java.io.IOException; import java.io.InputStream; import java.util.List; import org.apache.ibatis.io.Resources; import org.apache.ibatis.session.SqlSession; import org.apache.ibatis.session.SqlSessionFactory; import org.apache.ibatis.session.SqlSessionFactoryBuilder; import org.junit.Before; import org.junit.Test; import ecut.association.mapper.RoleMapperComic; import ecut.association.po.Comic; import ecut.association.po.Role; import ecut.association.po.RoleComic; public class RoleMapperComicTest { private SqlSessionFactory factory; @Before public void init() throws IOException { String resource = "ecut/association/mybaits-config.xml"; InputStream inputStream = Resources.getResourceAsStream(resource); SqlSessionFactoryBuilder builer =new SqlSessionFactoryBuilder(); factory = builer.build(inputStream); } // 二级缓存测试 @Test public void testCache2() throws Exception { SqlSession session1 = factory.openSession(); SqlSession session2 = factory.openSession(); SqlSession session3 = factory.openSession(); // 创建代理对象 RoleMapperComic mapper1 = session1.getMapper(RoleMapperComic.class); // 第一次发起请求,查询id为1的动漫 Comic comic1 = mapper1.findComicById(1); System.out.println("动漫信息:id="+comic1.getId()+",comicName="+comic1.getComicName()+",remark="+comic1.getRemark()); //这里执行关闭操作,将session中的数据写到二级缓存区域 session1.close(); //使用session3执行commit()操作 RoleMapperComic mapper3 = session3.getMapper(RoleMapperComic.class); Comic comic = mapper3.findComicById(1); comic.setComicName("fate"); mapper3.updateComic(comic); //执行提交,清空RoleMapperComic下边的二级缓存 session3.commit(); session3.close(); RoleMapperComic mapper2 = session2.getMapper(RoleMapperComic.class); // 第二次发起请求,查询id为1的动漫 Comic comic2 = mapper2.findComicById(1); System.out.println("动漫信息:id="+comic2.getId()+",comicName="+comic2.getComicName()+",remark="+comic2.getRemark()); session2.close(); } }
即使session关闭也可以在二级缓存中获取数据,无需查询数据库。
3、useCache和刷新缓存的配置
<select id="findComicById" parameterType="java.lang.Integer" resultMap="ComicResultMap" useCache="false">
SELECT * FROM t_comic WHERE id = #{value}
</select>
总结:针对每次查询都需要最新的数据sql,要设置成useCache=false,禁用二级缓存。
在mapper的同一个namespace中,如果有其它insert、update、delete操作数据后需要刷新缓存,如果不执行刷新缓存会出现脏读。设置statement配置中的flushCache="true" 属性,默认情况下为true即刷新缓存,如果改成false则不会刷新。使用缓存时如果手动修改数据库表中的查询数据会出现脏读。
<update id="updateComic" parameterType="Comic" flushCache="true"> update t_comic set comic_name = #{comicName} where id =#{id} </update>
总结:一般下执行完commit操作都需要刷新缓存,flushCache=true表示刷新缓存,这样可以避免数据库脏读。
4、二级缓存应用场景
5、二级缓存的局限性
MyBaitis整合Ehcache
1、分布式缓存
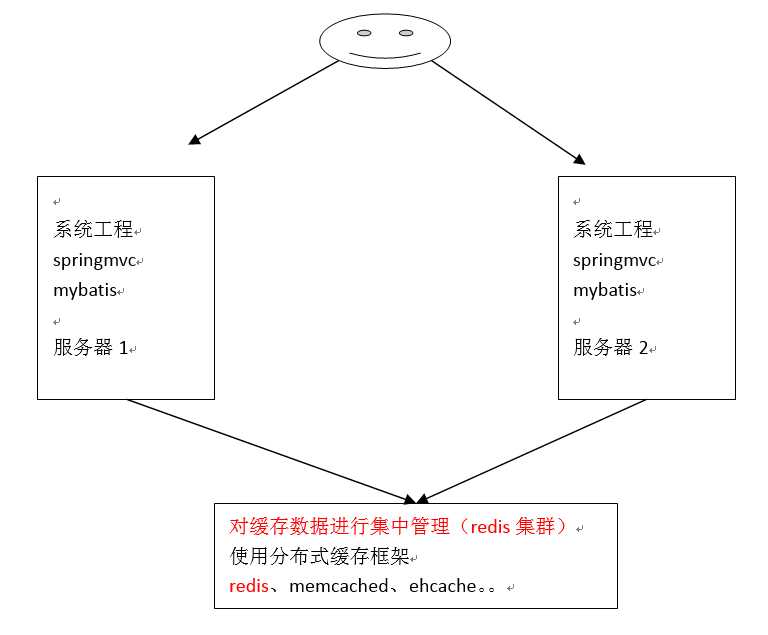
不使用分布缓存,缓存的数据在各各服务单独存储,不方便系统 开发。所以要使用分布式缓存对缓存数据进行集中管理。
mybatis无法实现分布式缓存,需要和其它分布式缓存框架进行整合。
2、整合方法
3、整合步骤(参照官网配置http://www.mybatis.org/ehcache-cache/)
<!-- 开启本mapper的namespace下的二缓存 type:指定cache接口的实现类的类型,mybatis默认使用PerpetualCache 要和ehcache整合,需要配置type为ehcache实现cache接口的类型 --> <cache type="org.mybatis.caches.ehcache.EhcacheCache"/>
配置mapper中cache中的type为ehcache对cache接口的实现类型。
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE ehcache > <ehcache> <!-- 存储位置 --> <diskStore path="java.io.tmpdir"/> <!-- 默认的cache配置 --> <defaultCache maxElementsInMemory="10000" eternal="false" timeToIdleSeconds="120" timeToLiveSeconds="120" overflowToDisk="true" /> </ehcache>
在classpath下配置ehcache.xml
转载请于明显处标明出处
https://www.cnblogs.com/AmyZheng/p/9382573.html
原文:https://www.cnblogs.com/AmyZheng/p/9382573.html