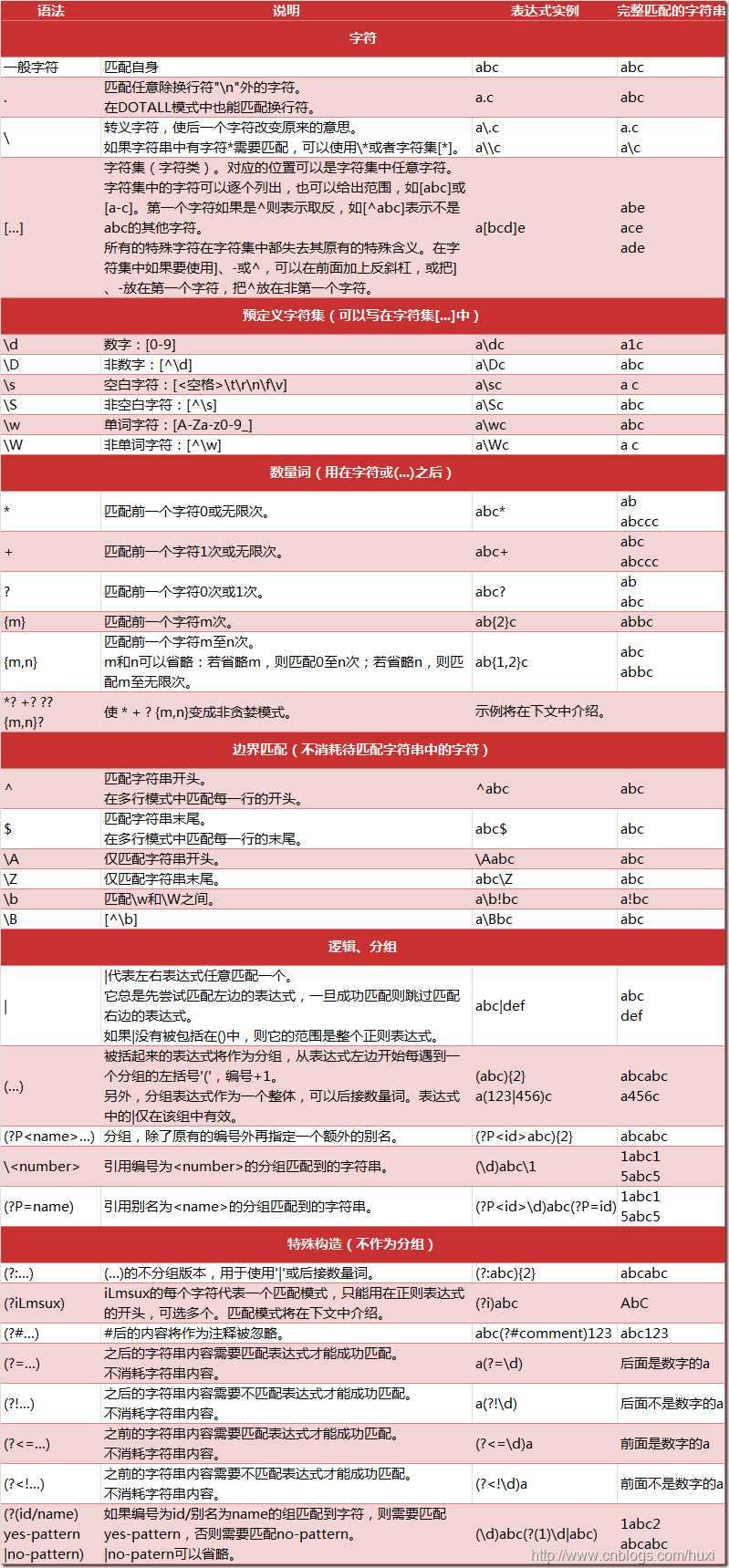
# 数量词的贪婪模式与非贪婪模式
正则表达式通常用于在文本中查找匹配的字符串。Python里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字符;非贪婪的则相反,总是尝试匹配尽可能少的字符。例如:正则表达式"ab*"如果用于查找"abbbc",将找到"abbb"。而如果使用非贪婪的数量词"ab*?",将找到"a"。
如下 加?为非贪婪匹配即尽可能少的匹配,不加则为贪婪匹配尽可能多的匹配,python 中总是默认贪婪匹配的
>>> import re
>>> re.findall(r'[a-z]*?','abcd')
['', '', '', '', '']
>>> re.findall(r'[a-z]+?','abcd')
['a', 'b', 'c', 'd']
>>> re.findall(r'[a-z]??','abcd')
['', '', '', '', '']
>>> re.findall(r'[a-z]*','abcd')
['abcd', '']
# 零宽断言以及不捕获分组,命名分组
(?=X ) 零宽度正先行断言。仅当子表达式 X 在 此位置的右侧匹配时才继续匹配。例如,\w+(?=\d) 与后跟数字的单词匹配,而不与该数字匹配。此构造不会回溯。
(?!X) 零宽度负先行断言。仅当子表达式 X 不在 此位置的右侧匹配时才继续匹配。例如,例如,\w+(?!\d) 与后不跟数字的单词匹配,而不与该数字匹配?。
(?<=X) 零宽度正后发断言。仅当子表达式 X 在 此位置的左侧匹配时才继续匹配。例如,(?<=19)99 与跟在 19 后面的 99 的实例匹配。此构造不会回溯。
(?<!X) 零宽度负后发断言。仅当子表达式 X 不在此位置的左侧匹配时才继续匹配。例如,(?<!19)99 与不跟在 19 后面的 99 的实例匹配
(?:) 不捕获分组,对于 ‘abc’ 用正则 r'(?:a)bc' findall 或 search 得到 ‘bc’ ,a 不会被捕获
(?P<name>exp) --》 (?P=name) 比 匿名分组 () --》 \1 的 好处是 可以很直观看到是如何反向引用分组的
>>> re.findall(r'(?P<alpha>[a-z])\d+(?P=alpha)','a123a456a')
['a']
原文:https://www.cnblogs.com/Frank99/p/9388881.html