1 /**
2 * 使用搜狗搜索检索关键字并爬取结果集的标题
3 * @author tele
4 *
5 */
6 public class SougouCrawler extends RamCrawler{
7
8 public SougouCrawler() {
9
10 }
11
12 public SougouCrawler(String keyword,int maxnum) {
13 for(int i=1;i<=maxnum;i++) {
14 //拼接url
15 String url ="https://www.sogou.com/web?query="+keyword+"&s_from=result_up&cid=&page="+ i +"&ie=utf8&p=40040100&dp=1&w=01029901&dr=1";
16 CrawlDatum crawlDatum = new CrawlDatum(url).meta("pageNum",i);
17 addSeed(crawlDatum);
18 addRegex(".*");
19 }
20 }
21
22
23 @Override
24 public void visit(Page page, CrawlDatums next) {
25 String pageNum = page.meta("pageNum");
26 Elements results = page.doc().select("div.results div[^class] h3 a");
27 for(int i=0;i<results.size();i++) {
28 System.out.println("第"+ pageNum +"页第"+ (i+1) +"条结果------" + results.get(i).text());
29 }
30 }
31
32 public static void main(String[] args) throws Exception {
33 String keyword="淘宝";
34 SougouCrawler crawler = new SougouCrawler(keyword,3);
35 crawler.setThreads(8);
36
37 Configuration conf = Configuration.copyDefault();
38 conf.setExecuteInterval(3000);
39 conf.setReadTimeout(5000);
40 conf.setWaitThreadEndTime(3000);
41
42 crawler.setConf(conf);
43 crawler.start(1);//只有一层
44 }
45 }
输出截图(部分)
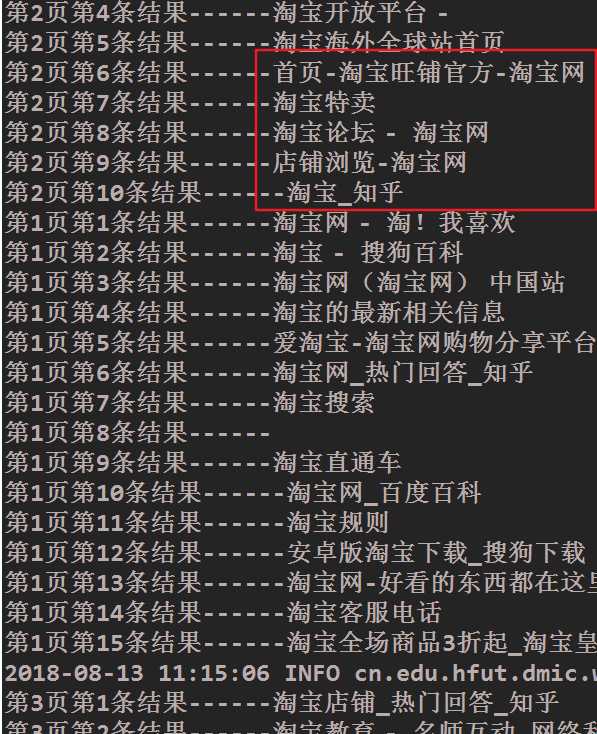
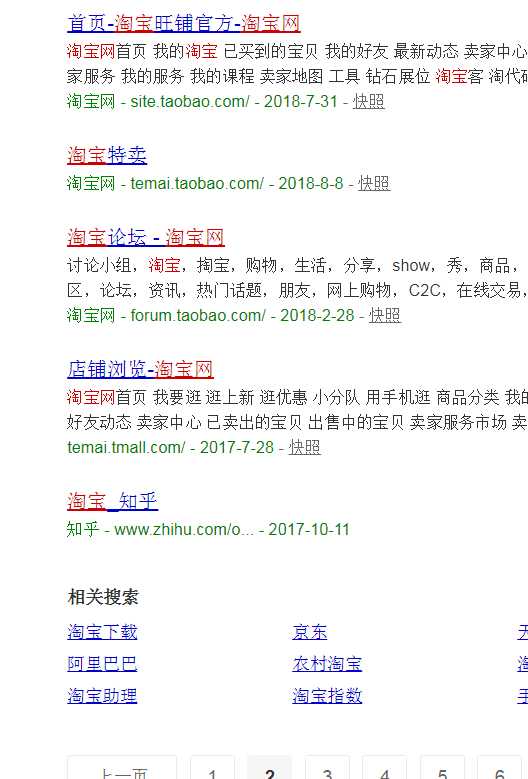
验证第二页数据标题
原文:https://www.cnblogs.com/tele-share/p/9466947.html