这篇文章,里面讲到对于一个41G大小、包含百万条记录的数据库进行查询操作,如果利用了索引,可以把操作耗时从37s降到0.2s。
那么什么是索引呢?利用索引可以加快数据库查询操作的原理是什么呢?
数据库提供了一种持久化的数据存储方式,从数据库中查询数据库是一个基本的操作,查询操作的效率是很重要的。
对于查询操作来说,如果被查询的数据已某种方式组织起来,那么查询操作的效率会极大提高。
在数据库中,一条记录会有很多列。如果把这些记录按照列Col1以某种数据结构组织起来,那么列Col2一定是乱序的。
因此,数据库在原始数据之外,维护了满足特定查找算法的数据结构,指向原始数据,称之为索引。
举例来说,在下面的图中,数据库有两列Col1、Col2。在存储时,按照列Col1组织各行,比如Col1已二叉树方式组织。如果查找col1中的某一个值,利用二叉树进行二分查找,不需要遍历整个数据库。
这样一来列Col2就是乱序的。为了解决这个问题,为Col2建立了索引,即把Col2也按照某种数据结构(这里是二叉树)组织起来。这样子查找列Col2时只需要进行二分查找即可。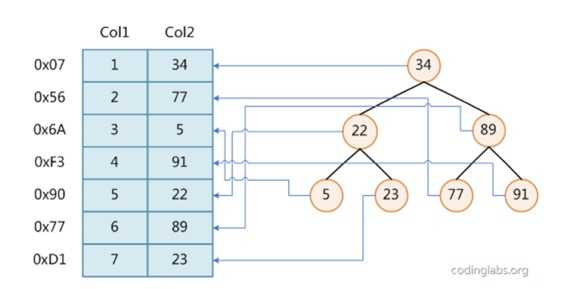 ?
?
由于数据库是存储在磁盘上的,因此实现索引用的数据结构会存储在磁盘上。磁盘的IO是需要注意的问题。
B树
B树是二叉树的变种,主要区别在于每一个节点的度可以大于2,即每一个节点可以分很多叉,大大降低了树的深度。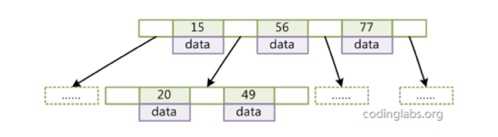 ?
?
上面这些特点使得B+树的深度大大降低,并且实现了对数据的有序组织。
B+树
B+树是对B树的扩展,特点在于非叶子节点不存储data,只存储key。如果每一个节点的大小固定(如4k,正如在sqlite中那样),那么可以进一步提高内部节点的度,降低树的深度。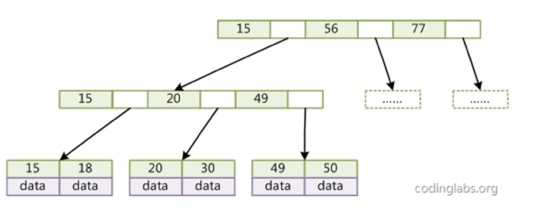 ?
?
顺序访问指针的B+树
对B+树做了一点改变,每一个叶子节点增加一个指向相邻叶子节点的指针,这样子可以提高区间访问的性能。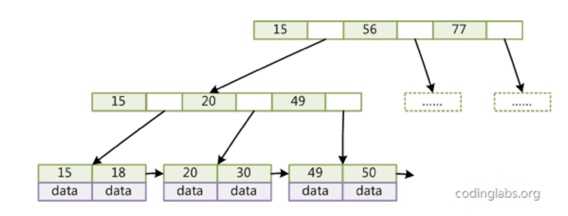 ?
?
如图,访问key在15到30的data。
根据索引查找数据时,分两步
通过两次B+树查找避免了一次全表扫描。
1. 对某一行或某几行添加PRIMARY KEY或UNIQUE约束,那么数据库会自动为这些列创建索引
2. 指定某一列为INTEGER PRIMARY KEY,那么这一列和rowid被指定为同一列。即可以通过rowid来获取,也可以通过列名来获取。
下面是一个数据库中一个表的统计信息,通过sqlite3_analyzer工具得到。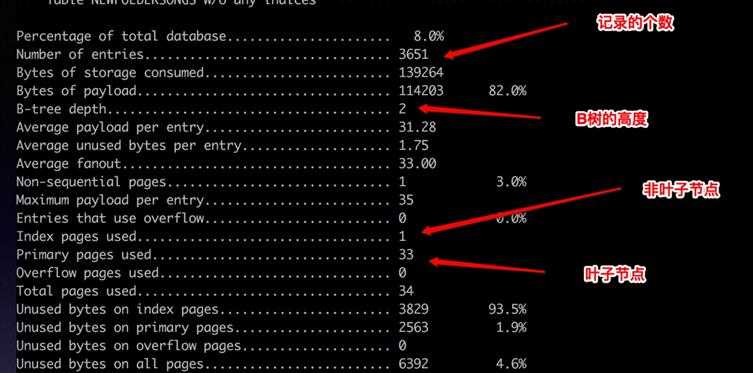 ?
?
可以看到表中一共有3651条记录,B树的深度只有2,有33个叶子节点,1个非叶子节点。因此最多只需要2次磁盘IO就可以根据rowid找到一行的数据。
比如我们有这么一个表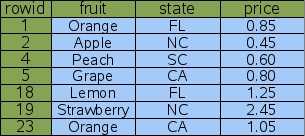 ?
?
benchmark
查询语句如下
SELECT price FROM fruitsforsale WHERE fruit=‘Peach’
由于没有索引,因此不得不做一次全表扫描。通过顺序访问指针遍历各个记录(record),比较fruit这一列和‘peatch’是否一致,如果一致,返回这一行的price列的值。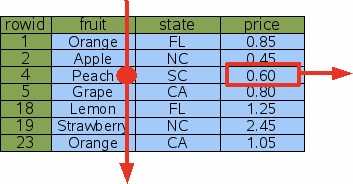 ?
?
对‘fruit’列加索引
如下,运行同样的语句,可以根据索引找到目标列对应的rowid为4,然后根据rowid找到对应行,从而选出price。通过两次B+树查找避免了全表查找。这也是最简单的情况 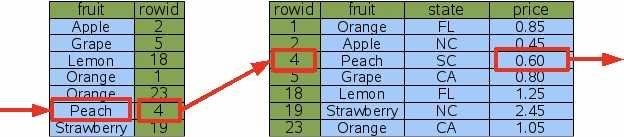 ?
?
多条索引命中
建立索引时,不要求索引是uique的,即索引表中的key可以是一样的。
如下图,索引表中有orange两条记录,找到第一条记录时,根据顺序访问指针可以轻易找到下一条索引,避免另一次B+树查找。(rowid=1和rowid=23可能位于两个不同的叶子节点中)
即这个查找索引的过程,可以通过一次B+树查和一次next操作完成,而next操作是很快的。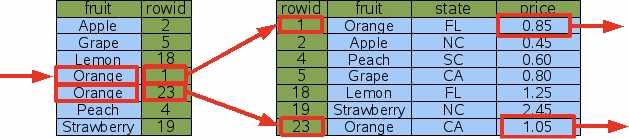 ?
?
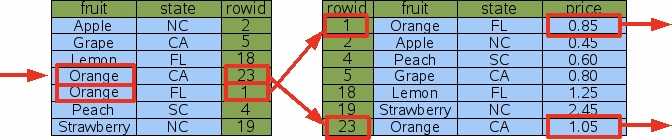
利用索引加快搜索和排序
在大多情况下,我们需要同时进行查找和排序操作,这时如果建立适当的索引,可以提高查找效率。
比如下面表中对fruit和state两列做了索引,运行下面的sql语句时,就不需要进行排序操作了,因为索引表是带有顺序的。
SELECT price FROM fruitforsale WHERE fruit=‘Orange‘ ORDER BY state
 ?
?
在sqlite中有一个命令叫做explain query plan,可以查看sqlite是如何执行查找操作的。下面的数据库语句不是引言中的查询语句,原理一样
37s的操作(没有用索引) ?
?
0.2s的操作(用了索引) ?
?
注意detail列。不用索引时,使用的是“SCAN”这个词,即全表扫描。使用索引时,使用的是“SEARCH”这个词。
对于一个41G的表来说,进行全表扫描的代价显然是很大的。
原文:https://www.cnblogs.com/fakeCoder/p/9482659.html