MPI 和 MPI4PY 的搭建上一篇文章已经介绍,这里面介绍一些基本用法。
mpi4py 的 helloworld
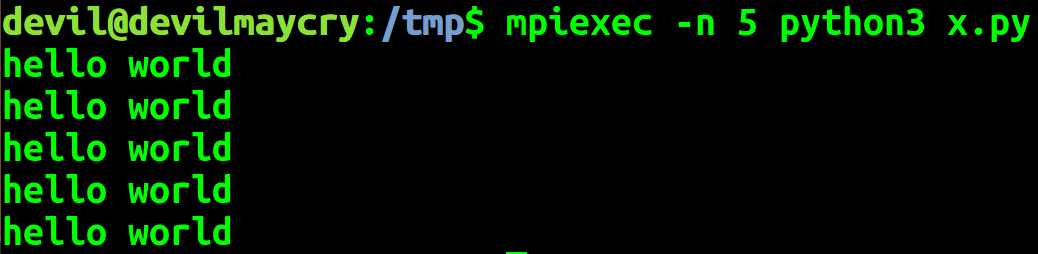
from mpi4py import MPI print("hello world")
mpiexec -n 5 python3 x.py
2. 点对点通信
因为 mpi4py 中点对点的 通信 send 语句 在数据量较小的时候是把发送数据拷贝到缓存区,是非堵塞的操作, 然而在数据量较大时候是堵塞操作,由此如下:
在 发送较小数据时:
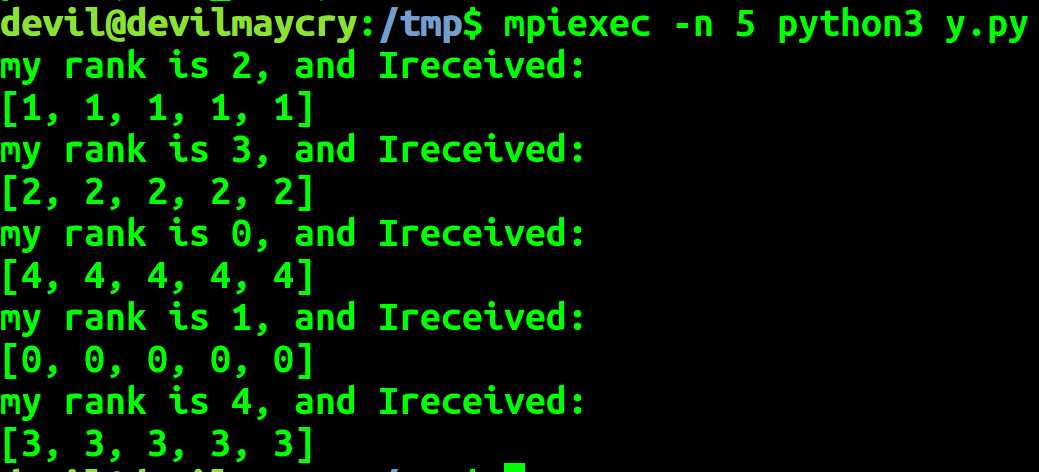
import mpi4py.MPI as MPI comm = MPI.COMM_WORLD comm_rank = comm.Get_rank() comm_size = comm.Get_size() # point to point communication data_send = [comm_rank]*5 comm.send(data_send,dest=(comm_rank+1)%comm_size) data_recv =comm.recv(source=(comm_rank-1)%comm_size) print("my rank is %d, and Ireceived:" % comm_rank) print(data_recv)
在数据量较大时, 比如发送 :
# point to point communication data_send = [comm_rank]*1000000
这时候就会造成各个进程之间的死锁。(因为这时候各个进程是堵塞执行,每个进程都在等待另一个进程的发送数据)
修改后的代码,所有进程顺序执行, 0进程发送给1,1接收然后发送给2,以此类推:
import mpi4py.MPI as MPI comm = MPI.COMM_WORLD comm_rank = comm.Get_rank() comm_size = comm.Get_size() data_send = [comm_rank]*1000000 if comm_rank == 0: comm.send(data_send, dest=(comm_rank+1)%comm_size) if comm_rank > 0: data_recv = comm.recv(source=(comm_rank-1)%comm_size) comm.send(data_send, dest=(comm_rank+1)%comm_size) if comm_rank == 0: data_recv = comm.recv(source=(comm_rank-1)%comm_size) print("my rank is %d, and Ireceived:" % comm_rank) print(data_recv)
3 群体通信
3.1 广播bcast
一个进程把数据发送给所有进程
import mpi4py.MPI as MPI comm = MPI.COMM_WORLD comm_rank = comm.Get_rank() comm_size = comm.Get_size() if comm_rank == 0: data = range(comm_size) dat = comm.bcast(data if comm_rank == 0 else None, root=0) print(‘rank %d, got:‘ % (comm_rank)) print(dat)
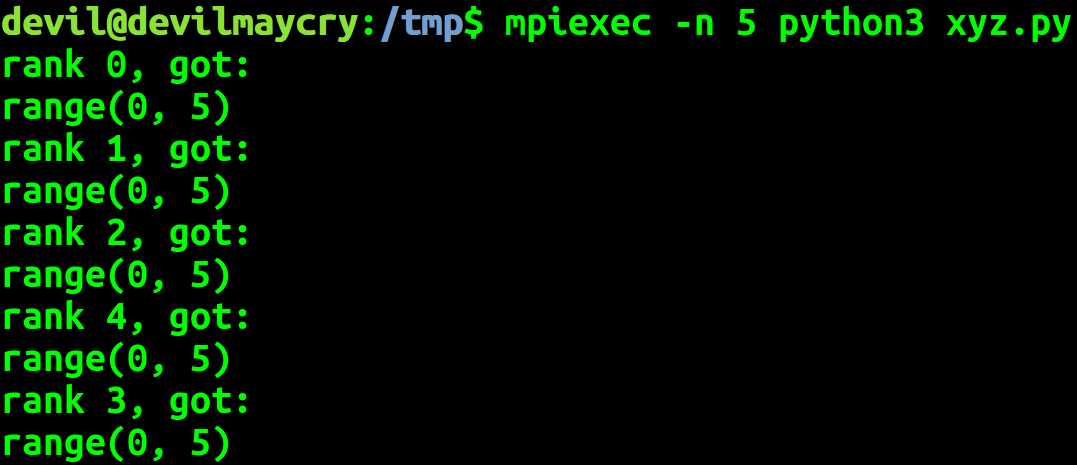
发送方 也会收到 这部分数据,当然发送方这份数据并不是网络传输接受的,而是本身内存空间中就是存在的。
3.2 散播scatter
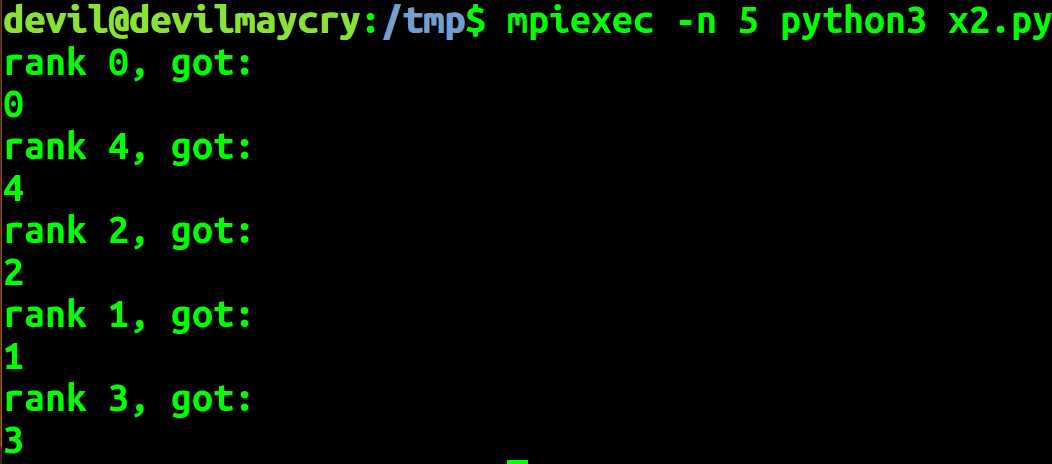
import mpi4py.MPI as MPI comm = MPI.COMM_WORLD comm_rank = comm.Get_rank() comm_size = comm.Get_size() if comm_rank == 0: data = range(comm_size) else: data = None local_data = comm.scatter(data, root=0) print(‘rank %d, got:‘ % comm_rank) print(local_data)
3.3 收集gather
将所有数据搜集回来
import mpi4py.MPI as MPI comm = MPI.COMM_WORLD comm_rank = comm.Get_rank() comm_size = comm.Get_size() if comm_rank == 0: data = range(comm_size) else: data = None local_data = comm.scatter(data, root=0) local_data = local_data * 2 print(‘rank %d, got and do:‘ % comm_rank) print(local_data) combine_data = comm.gather(local_data,root=0) if comm_rank == 0: print("root recv {0}".format(combine_data))
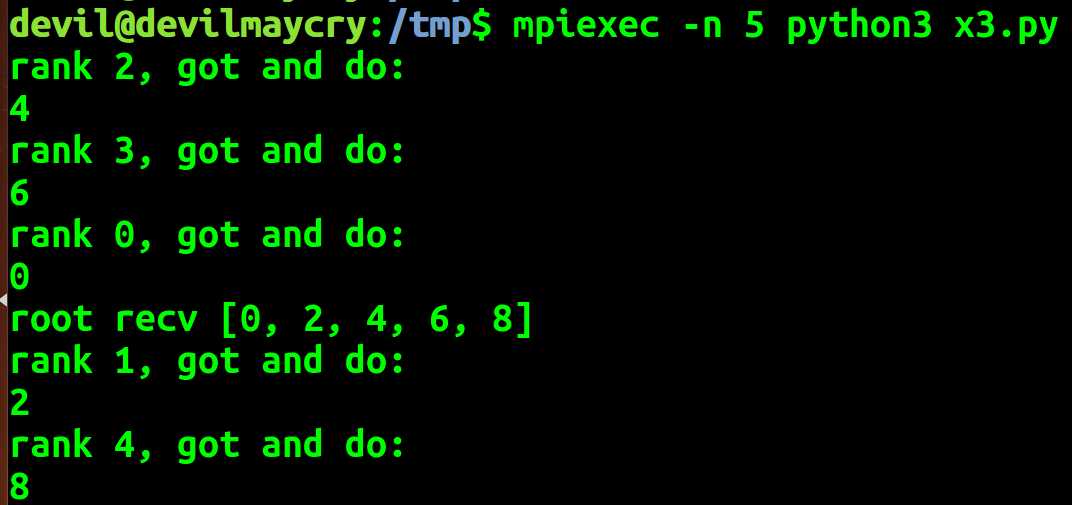
3.4 规约reduce
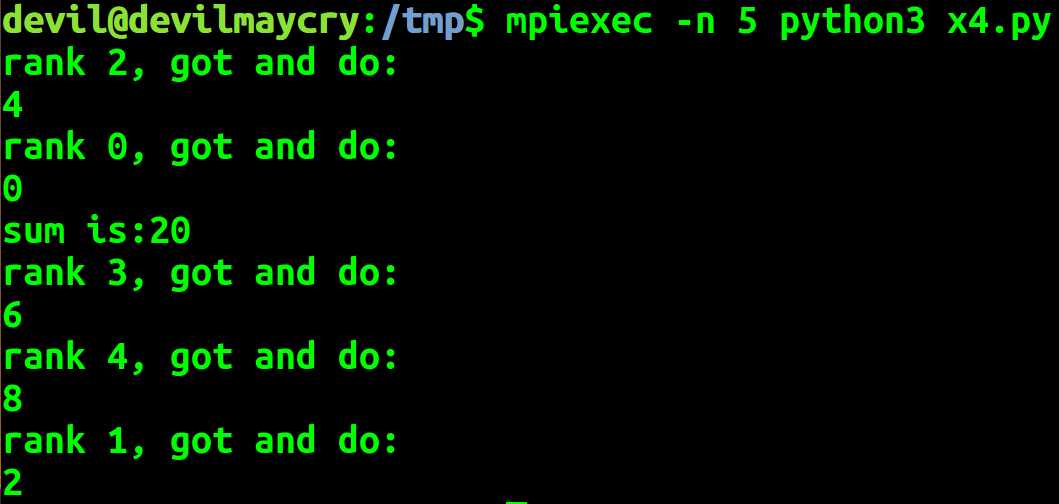
import mpi4py.MPI as MPI comm = MPI.COMM_WORLD comm_rank = comm.Get_rank() comm_size = comm.Get_size() if comm_rank == 0: data = range(comm_size) else: data = None local_data = comm.scatter(data, root=0) local_data = local_data * 2 print(‘rank %d, got and do:‘ % comm_rank) print(local_data) all_sum = comm.reduce(local_data, root=0,op=MPI.SUM) if comm_rank == 0: print(‘sum is:%d‘ % all_sum)
SUM MAX MIN 等操作在数据搜集是在各个进程中进行一次操作后汇总到 root 进程中再进行一次总的操作。
op=MPI.SUM
op=MPI.MAX
op=MPI.MIN
参考文章:
《Python多核编程mpi4py实践》
https://blog.csdn.net/zouxy09/article/details/49031845
原文:https://www.cnblogs.com/devilmaycry812839668/p/9484644.html