#结构化时间-->字符串时间
#time.strftime("格式定义","结构化时间") 结构化时间参数若不传,则显示当前时间
import time
# print(time.strftime("%Y-%m-%d %X"))
# #2018-08-17 08:55:16
# print(time.strftime("%Y-%m-%d",time.localtime(1500000000)))
# #2017-07-14
# print(time.strftime(‘%Y--%m__%d %x‘,time.localtime(30000000000))) #2920--08__30 08/30/20
# #字符串时间-->结构化时间
# #time.strptime(时间字符串,字符串对应格式)
# print(time.strptime("07/24/2017","%m/%d/%Y"))
# #time.struct_time(tm_year=2017, tm_mon=7, tm_mday=24, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=0, tm_yday=205, tm_isdst=-1))
# print(time.strptime(‘2019.6.28 5.22‘,‘%Y.%m.%d %H.%M‘))
# #time.struct_time(tm_year=2019, tm_mon=6, tm_mday=28, tm_hour=5, tm_min=22, tm_sec=0, tm_wday=4, tm_yday=179, tm_isdst=-1)
#结构化时间 --> %a %b %d %H:%M:%S %Y串
#time.asctime(结构化时间) 如果不传参数,直接返回当前时间的格式化串
# print(time.asctime(time.localtime(1500000000)))
# ‘Fri Jul 14 10:40:00 2017‘
# print(time.asctime())
# ‘Mon Jul 24 15:18:33 2017‘
#时间戳 --> %a %b %d %H:%M:%S %Y串
#time.ctime(时间戳) 如果不传参数,直接返回当前时间的格式化串
# print(time.ctime())
# ‘Mon Jul 24 15:19:07 2017‘
# print(time.ctime(1500000000))
# ‘Fri Jul 14 10:40:00 2017‘
# #计算时间
# s=input(‘start time :%Y-%m-%d %X‘)
# e=input(‘end time :%Y-%m-%d %X‘)
# d=time.mktime(time.strptime(e,‘%Y-%m-%d %X‘))-time.mktime(time.strptime(s,‘%Y-%m-%d %X‘))
# print(time.localtime(d))
#2018-5-22 3:55:21
#2108-5-22 6:55:22 time.struct_time(tm_year=2060, tm_mon=1, tm_mday=1, tm_hour=11, tm_min=0, tm_sec=1, tm_wday=3, tm_yday=1, tm_isdst=0)
#random模块
import random
# random.random() #0-1之间的小数
# random.uniform(5,6) #5-6之间的随机小数
# random.randint(1,9) # 大于等于1且小于等于9之间的整数 【】
# random.randrange(1,55,2) # 大于等于1且小于55之间的奇数,有步长值
# random.choice([1,‘23‘,[4,5]]) # #1或者23或者[4,5],随机返回一个
# random.choices([1,‘23‘,[4,5]]) #一样效果
# print(random.sample([1,‘23‘,[4,5]],2)) # #列表元素任意2个组合
# ##打乱列表顺序
# item=[1,3,5,7,9]
# random.shuffle(item) # 打乱次序
# item
# [5, 1, 3, 7, 9]
# random.shuffle(item)
# item
# [5, 9, 7, 1, 3]
#生成随机验证码
# def code():
# items=[]
# for i in range(3):
# a=random.randint(1,99)
# b=chr(random.randrange(65,99))
# item=random.choices([a,b])
# random.shuffle(item)
# items=items+item
# print(items,end=‘‘)
# code()
#os模块
import os
‘‘‘
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.curdir 返回当前目录: (‘.‘)
os.pardir 获取当前目录的父目录字符串名:(‘..‘)
os.makedirs(‘dirname1/dirname2‘) 可生成多层递归目录
os.removedirs(‘dirname1‘) 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir(‘dirname‘) 生成单级目录;相当于shell中mkdir dirname
os.rmdir(‘dirname‘) 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir(‘dirname‘) 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() 删除一个文件
os.rename("oldname","newname") 重命名文件/目录
os.stat(‘path/filename‘) 获取文件/目录信息
os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"
os.pathsep 输出用于分割文件路径的字符串 win下为;,Linux下为:
os.name 输出字符串指示当前使用平台。win->‘nt‘; Linux->‘posix‘
os.system("bash command") 运行shell命令,直接显示
os.popen("bash command).read() 运行shell命令,获取执行结果
os.environ 获取系统环境变量
os.path
os.path.abspath(path) 返回path规范化的绝对路径 os.path.split(path) 将path分割成目录和文件名二元组返回 os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素 os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。
即os.path.split(path)的第二个元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后访问时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
os.path.getsize(path) 返回path的大小
stat 结构:
st_mode: inode 保护模式
st_ino: inode 节点号。
st_dev: inode 驻留的设备。
st_nlink: inode 的链接数。
st_uid: 所有者的用户ID。
st_gid: 所有者的组ID。
st_size: 普通文件以字节为单位的大小;包含等待某些特殊文件的数据。
st_atime: 上次访问的时间。
st_mtime: 最后一次修改的时间。
st_ctime: 由操作系统报告的"ctime"。在某些系统上(如Unix)是最新的元数据更改的时间,在其它系统上(如Windows)是创建时间(详细信息参见平台的文档)。
stat 结构
‘‘‘
import sys
#sys模块
# sys.argv 命令行参数List,第一个元素是程序本身路径
# sys.exit(n) 退出程序,正常退出时exit(0),错误退出sys.exit(1)
# sys.version 获取Python解释程序的版本信息
# sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
# sys.platform 返回操作系统平台名称
#序列化模块 将原本的字典、列表等内容转换成一个字符串的过程就叫做序列化。
#json 带s的方法为内存角度 不带s方法则为文件的角度
# import json
# dic = {‘k1‘:‘v1‘,‘k2‘:‘v2‘,‘k3‘:‘v3‘}
# #dic = [1,[‘a‘,‘b‘,‘c‘],3,{‘k1‘:‘v1‘,‘k2‘:‘v2‘}] #嵌套也可以
# dic1=json.dumps(dic) #序列化
# print(type(dic1),dic1) #<class ‘str‘> {"k1": "v1", "k2": "v2", "k3": "v3"} 通用中字符串为“”
# dic2=json.loads(dic1)
# print(type(dic2),dic2) #<class ‘dict‘> {‘k1‘: ‘v1‘, ‘k2‘: ‘v2‘, ‘k3‘: ‘v3‘}
#dump load
import json
# f=open(‘log‘,mode=‘w‘)
# dic = {‘k1‘:‘v1‘,‘k2‘:‘v2‘,‘k3‘:‘v3‘}
# json.dump(dic,f) #记得写f :dump(obj,fp) f为文件变量名
# f.close()
# f=open(‘log‘,mode=‘r+‘)
# dic2=json.load(f)
# f.close()
# print(type(dic2),dic2) #<class ‘dict‘> {‘k1‘: ‘v1‘, ‘k2‘: ‘v2‘, ‘k3‘: ‘v3‘}
#ensure_ascii关键字参数 实现中文文件内显示
# f=open(‘log‘,‘w‘)
# json.dump({‘国籍‘:‘中国‘},f)
# ret=json.dumps({‘国籍‘:‘中国‘})
# f.write(ret+‘/n‘)
# json.dump({‘国籍‘:‘中国‘},f,ensure_ascii=False)
# ret=json.dumps({‘国籍‘:‘中国‘},ensure_ascii=False)
# f.write(ret+‘/n‘)
# f.close() #每次加一个/n的算法为了一次性不拿出太多数据 写部分自加。。 用了ensure之后使得文件内gbk可看到汉字,一般用处不大,默认bytes
# f=open(‘log‘)
# s=f.readlines()
# print(s) #[‘{"\\u56fd\\u7c4d": "\\u4e2d\\u56fd"}{"\\u56fd\\u7c4d": "\\u4e2d\\u56fd"}/n{"国籍": "中国"}{"国籍": "中国"}/n‘]
#json格式化输出
# data = {‘username‘:[‘李华‘,‘二愣子‘],‘sex‘:‘male‘,‘age‘:16}
# dic2 = json.dumps(data,sort_keys=True,indent=2,separators=(‘,‘,‘:‘),ensure_ascii=False)
# print(dic2) # 数据,按键值排序=T,一开始缩进空格数量,分隔符,保证ascii
‘‘‘{
"age":16,
"sex":"male",
"username":[
"李华",
"二愣子"
]
}‘‘‘
#pickle
import pickle
# dic = {‘k1‘:‘v1‘,‘k2‘:‘v2‘,‘k3‘:‘v3‘}
# dic2=pickle.dumps(dic)
# print(dic2) #一串二进制内容
# dic3=pickle.loads(dic2)
# print(dic3) #{‘k1‘: ‘v1‘, ‘k2‘: ‘v2‘, ‘k3‘: ‘v3‘}
# import time
# dict=time.localtime(1000000000)
# print(dict) #结构化时间
# f=open(‘log‘,‘wb‘) #用bytes
# pickle.dump(dict,f) #dump的内容,文件变量名
# f.close()
# f=open(‘log‘,‘rb‘)
# dict2=pickle.load(f) #无ensure
# print(dict2.tm_year) #只显示年
#shelve
import shelve
# f = shelve.open(‘shelve_file‘)
# f[‘key‘] = {‘int‘:10, ‘float‘:9.5, ‘string‘:‘Sample data‘} #直接对文件句柄操作,就可以存入数据
# f.close() #可以为新创立文件,分成三个文件
# import shelve
# f1 = shelve.open(‘shelve_file‘)
# existing = f1[‘key‘] #取出数据的时候也只需要直接用key获取即可,但是如果key不存在会报错
# f1.close()
# print(existing)
#这个模块有个限制,它不支持多个应用同一时间往同一个DB进行写操作。
# 所以当我们知道我们的应用如果只进行读操作,我们可以让shelve通过只读方式打开DB
# f=shelve.open(‘shelve_file‘,flag=‘r‘)
# e=f[‘key‘]
# print(e)
# f.close()
#由于shelve在默认情况下是不会记录待持久化对象的任何修改的,所以我们在shelve.open()时候需要修改默认参数,否则对象的修改不会保存。
# f1 = shelve.open(‘shelve_file‘)
# print(f1[‘key‘])
# f1[‘key‘][‘new_value‘]=‘not here before‘
# f1.close()
# f2=shelve.open(‘shelve_file‘,writeback=True)
# print(f2[‘key‘])
# f2[‘key‘][‘new_value‘]=‘not here before‘
# f2.close()
#writeback方式有优点也有缺点。优点是减少了我们出错的概率,并且让对象的持久化对用户更加的透明了;
# 但这种方式并不是所有的情况下都需要,首先,使用writeback以后,shelf在open()的时候会增加额外的内存消耗,
# 并且当DB在close()的时候会将缓存中的每一个对象都写入到DB,这也会带来额外的等待时间。因为shelve没有办法知道缓存中哪些对象修改了,
# 哪些对象没有修改,因此所有的对象都会被写入。
#包和模块的导入
# 内置模块
# 扩展的 django
# 自定义的
# 所有的模块导入都应该尽量往上写
# 内置模块
# 扩展模块
# 自定义模块
# 模块不会重复被导入 : sys.moudles
# 从哪儿导入模块 : sys.path
#import
# import 模块名
# 模块名.变量名 和本文件中的变量名完全不冲突
# import 模块名 as 重命名的模块名 : 提高代码的兼容性
# import 模块1,模块2
#from import
# from 模块名 import 变量名
#直接使用 变量名 就可以完成操作
#如果本文件中有相同的变量名会发生冲突
# from 模块名 import 变量名字 as 重命名变量名
# from 模块名 import 变量名1,变量名2
# from 模块名 import *
# 将模块中的所有变量名都放到内存中
# 如果本文件中有相同的变量名会发生冲突
# from 模块名 import * 和 __all__ 是一对
# 没有这个变量,就会导入所有的名字
# 如果有all 只导入all列表中的名字
# __name__ 跨平台、文件使用
# 在模块中 有一个变量__name__,
# 当我们直接执行这个模块的时候,__name__ == ‘__main__‘
# 当我们执行其他模块,在其他模块中引用这个模块的时候,这个模块中的__name__ == ‘模块的名字‘
# 文件
# import demo
# def read():
# print(‘my read func‘)
# demo.read()
# print(demo.money)
# 先从sys.modules里查看是否已经被导入
# 如果没有被导入,就依据sys.path路径取寻找模块
# 找到了就导入
# 创建这个模块的命名空间
# 执行文件,把文件中的名字都放到命名空间里
# 模块的导入
# import
# from import
# as重命名
# 都支持多名字导入
# sys.moudles记录了所有被导入的模块
# sys.path 记录了导入模块的时候寻找的所有路径
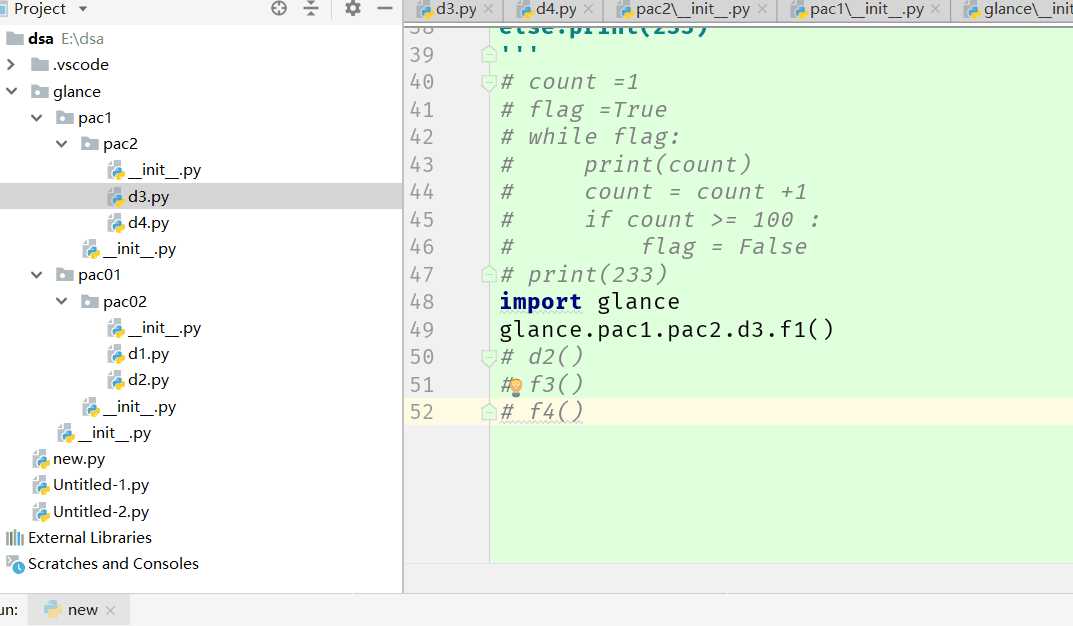
# 把解决一类问题的模块放在同一个文件夹里 —— 包
# import os
# os.makedirs(‘glance/api‘) #在该目录下添加文件夹
# os.makedirs(‘glance/cmd‘)
# os.makedirs(‘glance/db‘)
# l = []
# l.append(open(‘glance/__init__.py‘,‘w‘)) #存储到列表中
# l.append(open(‘glance/api/__init__.py‘,‘w‘))
# l.append(open(‘glance/api/policy.py‘,‘w‘))
# l.append(open(‘glance/api/versions.py‘,‘w‘))
# l.append(open(‘glance/cmd/__init__.py‘,‘w‘))
# l.append(open(‘glance/cmd/manage.py‘,‘w‘))
# l.append(open(‘glance/db/models.py‘,‘w‘))
# map(lambda f:f.close() ,l) #用列表一口气关掉
#使用绝对路径# 使用绝对路径 不管在包内部还是外部 导入了就能用
# 不能挪动,但是直观
# import sys
# sys.path.insert(0,‘C:\\Users\\Administrator\\PycharmProjects\\s9\\day21\\dir‘)
# # print(sys.path)
# from glance.api import policy
# policy.get()
# 相对路径
# from dir import glance
# glance.api.policy.get()
# 可以随意移动包 只要能找到包的位置,就可以使用包里的模块
# 包里的模块如果想使用其它模块的内容只能使用相对路径,使用了相对路径就不能在包内直接执行了
#***********导入文件夹下所有文件****************
#在每一级文件夹下有————init__文件,来impor他该文件夹等级下所有文件和文件夹
#调用时,只需要import设置了的最高级的文件夹名称,调用时一路点到文件的某个具体方法里执行
原文:https://www.cnblogs.com/shori/p/9495541.html