前言:
主从复制做为MySQL的精髓, 它有两大困难:主从数据的延时与数据的不一致性。本文主要表达的内容是如何排查数据不一致性。针对数据不一致的排查处理,各位业界大佬们都有丰富的处理经验,我就不多哔哔。我今天来主要给大家介绍工作中碰到奇葩示例:由于一个极隐式的骚操作,导致从库丢失数据(数据丢失量在每天将近万条记录)!
环境描述:
业务环境:短时间内(几个月的时间),业务蓬勃发展,客户量从一两万一下增加到几十万用户。
数据库环境:如下图
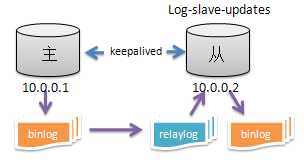
问题描述:
某一天,主库10.0.0.1的CPU使用率突然升高,均值达到80%+,导致keepalived的VIP漂移至从库10.0.0.2。理论上丢失的是切换过程中的几秒钟数据,业务侧对丢失这几秒数据表示没关系。那这个事件到此应该就结束了!
然而,当天晚上,业务打电话过来说:丢失了部分用户信息,导致用户登入不了,已经被客户投诉了,要求帮忙恢复数据并查找数据丢失原因。领导对于这个事也很看重,因为丢失数据,这是一个比较敏感的话题,特别是还被客户投诉了。
数据恢复,这块就不具体深入。稍微提下,这边因为新主10.0.0.2已经有数据写入,只能对比用户表数据把新主少的数据导入进去。
初步排查:
对于主从复制丢失数据,这个问题也没有特别好的办法来,只能老老实实的跟踪数据复制过程,查看是哪里出了问题。
选择丢失数据中时间比较近的,时间为2017-06-09 13:36:01,ID为849791这条数据,来跟踪整个复制过程,因为日志只保留14天的。
分析主库binlog日志,binlog日志中是有这条记录的。
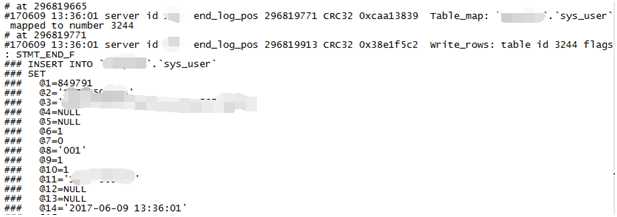
分析从库日志:因为数据库配置了relay_log_purge与log-slave-updates,所以中继日志已经找不到这个时间点的了,只能查看从库binlog日志。然而在从库的binlog日志中并未找到这条记录,说明这条数据是未执行,排除后期人为删除的。那么数据为何不被执行呢?或者说数据是在执行过程中丢失的?
数据分析:
但无可用的中继日志这怎么办?难道没办法查了?这让我想到去观察、对比下丢失的数据,是否含有什么规律。是不定时丢失数据,还是会在某些特定时刻丢失数据。
去整理下某表丢失的数据,通过观察、分析丢失数据的属性。(下图是我截取的部分列,最后一列的时间是创建时间,也就是写表时间)
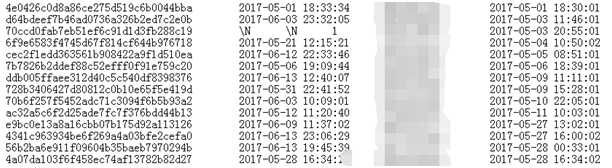
从图中可以看出,丢失的数据的插表时间都是在每分钟的前两秒。这不由的不让人思考,为何丢失的数据是每分钟前2秒的?而且数据丢失的时间间隔也不是很长,基本隔几天就肯定有数据丢失。那么就简单了!
深入调查:
首先,关闭log-slave-updates、relay_log_purge等一切影响判断的而外参数设置,等待上一段时间后,再来对比某表新数据丢失情况。
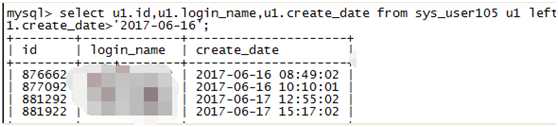
可以看到又有新数据丢失,根据这些丢失数据在来排查问题。
首先先查主库:查看主库的binlog日志状体信息状态。
就以2017-6-17 15:17:02最新丢失的这条数据来跟踪,查看主库10.0.0.2上的binlog日志中是否存在这条数据:
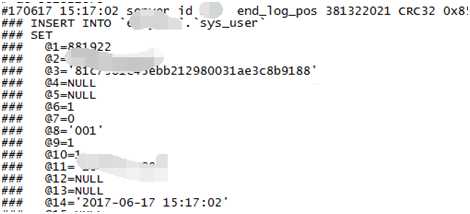
结果显示主库是存在这条数据的。
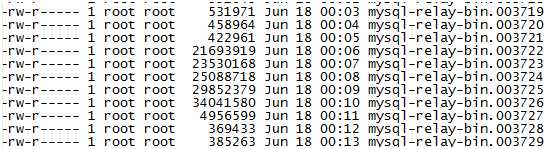
在登入从库查看relay-log日志情况,发现relay-log日志生成太频繁,每分钟生成1个relay-log日志,而且又些文件大小又不一致。那么这套主从集群,业务肯定部署过分割relay-log日志的脚本,而且应该是flush来强制刷新的。如图
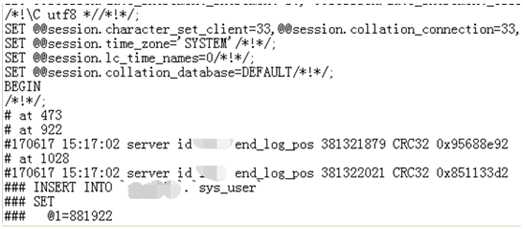
我们先来看从库relay-log日志中是否存在这条数据,查找17分生成的relay日志,提取前两秒能匹配的插入情况。

发现并没有这条insert操作,难道数据未写入relay日志,刷新日志时导致事务丢失?? 把查询时间拉长至50秒。

发现也没有这条数据,并且数据跟前面两秒的一致。
赶紧去18分生成的relay日志查看,发现这条数据在15:18分这个relay日志中的第一个事务的位置。
那么是没有执行,还是执行过程丢失?仔细观察主库binlog与从relay-log日志的记录,也没能看出什么名堂,从事务开始到commit,都一样。
问题定位:
如果1条数据无法比较!那就再随机拿几条丢失的数据来跟踪。发现情况都一样,数据都已经复制到relay日志中,而且内容根本看不出为何不能执行。
唯一有疑点的是这些事务都在日志的第一个事务中。顿时,我有种想法,会不会强制刷新relay日志,造成日志的第一个事务有时不执行,或执行过程中丢失?如果是脚本引起的,那么除这些事务未执行外,肯定还有其他事务也未执行。
那么,我就随机选择几个relay-log日志,找到第一个事务。
具体分析如下:

再登入从库查询结果:
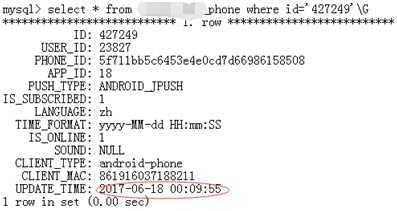
可以看出从库数据并未更新。
随后,随机分析了几个relay日志,发现第一个事务都未被执行。而且操作的表都是有不同的,操作也是有不同,有insert、update等等。顿时感觉,事情大条了。如果每个日志的第一个事务都未执行,那么从库要少多少条数据?不敢想象,现在业务还在上升期,不久业务量会是现在的几倍,可能更多。 那到那时就不是投诉那么简单了。
又抓取了部分relay日志情况,第一个事务也都未被执行。我可以肯定了,是所有relay日志的第一个事务都未被执行。
那么这个问题也可以是分割relay日志的脚本造成的了,它是如何造成的呢?一般强制刷新日志是用flush命令来操作的。flush命令一般是不会造成数据丢失,当然像他们这样频繁的操作,我是不知道会不会造成BUG,导致丢数据。还有在flush relay logs的时候有没有用到其他的什么操作呢?
我决定抓一把数据库中的操作过的命令。
抓取命令,问题解决:
想到就做,登上从库主机、登入数据库,开启general_log日志。
坐等5分钟,打开日志,寻找每分钟前几秒的记录;
视乎发现了非常可怕的操作!
上图,以表我的震惊。
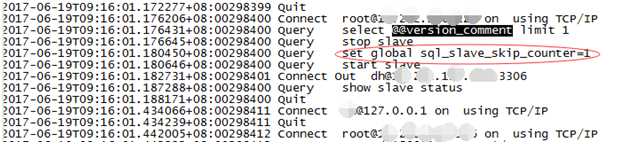
业务用了stop slave与Start slave来刷新relay日志,并有跳过一个事务的操作!这就解释的通了,为何relay日志第一个事务全都丢失了。
至此!问题已经清晰,是由于开发设置的分割relay日志的脚本,使用了非常规命令及sql_slave_skip_counter跳过事务命令来分隔relay-log日志,导致事务大量丢失。
这个事件反映出了很多人(包括DBA)对数据库基本原理、基本命令的不熟悉,对未知事物缺乏敬畏之心啊。
原文:https://www.cnblogs.com/mysql-hongling/p/9503971.html