在计算机程序的开发过程中,随着程序代码越写越多,在一个文件里代码就会越来越长,越来越不容易维护。
为了编写可维护的代码,我们把很多函数分组,分别放到不同的文件里,这样,每个文件包含的代码就相对较少,在python中。一个.py文件就称为一个模块(Module)
模块让你能够有逻辑地组织你的Python代码段。
把相关的代码分配到一个 模块里能让你的代码更好用,更易懂。
模块也是Python对象,具有随机的名字属性用来绑定或引用。
简单地说,模块就是一个保存了Python代码的文件。模块能定义函数,类和变量。模块里也能包含可执行的代码。
提高了代码的可维护性。
其次,编写代码不必从零开始。当一个模块编写完毕,就可以被其他地方引用。我们编写程序的时候也经常引用其他模块,包括python的内置的模块和第三方模块。
注:我们自已编写模块名时,尽量不要与内置函数或者模块名字冲突。如果与系统的模块同名,否则无法导入系统自带的模块
1.自定义模块
2.内置标准模块(又称标准库)
3.第三方模块(开源模块)
第三方常用的开源模块如下
1.yum 2.pip 3.apt-get
Python的from语句让你从模块中导入一个指定的部分到当前命名空间中。语法如下:
from modname import name1[, name2[, ... nameN]]
把一个模块的所有内容全都导入到当前的命名空间也是可行的,只需使用如下声明:
from modname import *
这提供了一个简单的方法来导入一个模块中的所有项目。然而这种声明不该被过多地使用。如果引入的其它来源的命名,很有可能覆盖已有的定义。
当你导入一个模块,Python解析器对模块位置的搜索顺序是:
模块搜索路径存储在system模块的sys.path变量中。变量里包含当前目录,PYTHONPATH和由安装过程决定的默认目录。
Python 提供了一个 time 和 calendar 模块都可以用于格式化日期和时间。
时间间隔是以秒为单位的浮点小数。
每个时间戳都以自从1970年1月1日午夜(历元)经过了多长时间来表示。
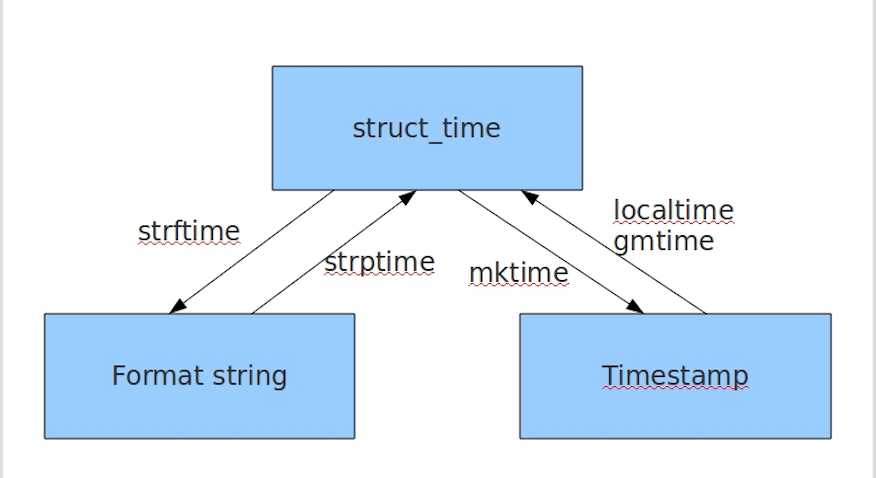
Python 的 time 模块下有很多函数可以转换常见日期格式。
time模块常用的方法:
time.time() 时间戳
print(time.time())
time.localtime(second) 加上second(时间戳)转换结构化时间,不加则显示当前的结构化时间
print(time.localtime())
print(time.localtime(1371643198))
time.gmtime(second) #utc时区加上second(时间戳)转换结构化时间,不加则显示当前的结构化时间
print(time.gmtime())
print(time.gmtime(1391614837))
mktime ()结构化时间转换为时间戳
print(time.mktime(time.localtime()))
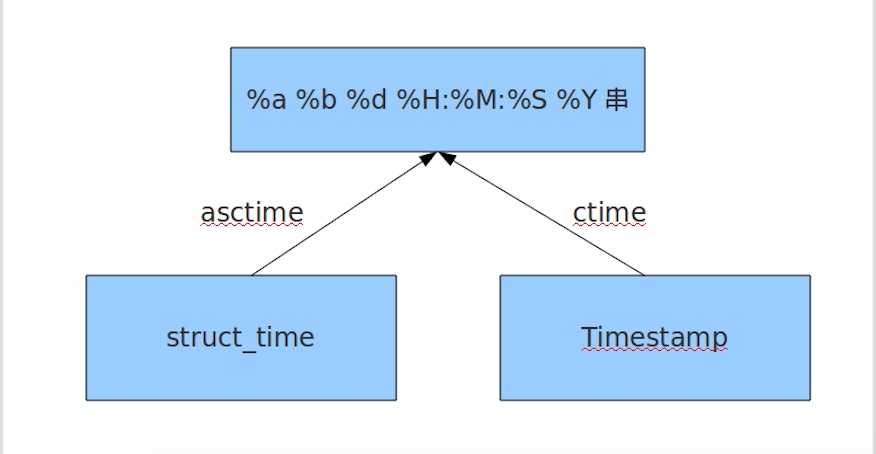
time.ctime(seconds)#将加上时间戳转换为时间戳的格式化时间,不加则返回当前的的格式化时间
print(time.time())
print(time.ctime(1331644244))
time.asctime(p_tuple)#加参数是加一个结构化时间,把加的结构化时间转换为格式化时间,不加则返回当前的格式化时间
print(time.asctime())
print(time.asctime(time.gmtime()))
time.strftime(format,p_tuple) #把一个结构化时间转化相应的格式时间
print(time.strftime("%Y-%m-%d %X",time.localtime()))
time.strptime(string,format) #把相应的格式时间,转换为结构化时间
print(time.strptime("2015-5-20 20:22:36","%Y-%m-%d %X"))
#time.struct_time(tm_year=2015, tm_mon=5, tm_mday=20, tm_hour=20, tm_min=22, tm_sec=36, tm_wday=2, tm_yday=140, tm_isdst=-1)
time.sleep(second)#将程序延迟指定的秒数运行
print(time.sleep(5))
time.clock()
# 这个需要注意,在不同的系统上含义不同。在UNIX系统上,它返回的是“进程时间”,它是用秒表示的浮点数(时间戳)。
# 而在WINDOWS中,第一次调用,返回的是进程运行的实际时间。而第二次之后的调用是自第一次调用以后到现在的运行
# 时间,即两次时间差。
import random print(random.random())#随机生成一个小于1的浮点数 print(random.shuffle([1,3,5,7,9]))#打乱列表中元素的顺序 print(random.randint(1,3)) #[1-3]随机生成1到3的数 print(random.randrange(1,5)) #[1-5)随机生成1到4的数 print(random.uniform(1,5))#随机生成1-5的之间的浮点数 print(random.sample([1,‘123‘,[4,5]],2))#随机在列表中选取2个元素 print(random.choice([1,‘234‘,[5,6]]))#随机在列表中选取一个元素
常用sys模块的方法
1 sys.argv #在命令行参数是一个空列表,在其他中第一个列表元素中程序本身的路径 2 sys.exit(n) #退出程序,正常退出时exit(0) 3 sys.version #获取python解释程序的版本信息 4 sys.path #返回模块的搜索路径,初始化时使用python PATH环境变量的值 5 sys.platform #返回操作系统平台的名称 6 sys.stdin #输入相关 7 sys.stdout #输出相关 8 sys.stderror #错误相关
import os os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径 os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd os.curdir 返回当前目录: (‘.‘) os.pardir 获取当前目录的父目录字符串名:(‘..‘) os.makedirs(‘dirname1/dirname2‘) 可生成多层递归目录 os.removedirs(‘dirname1‘) 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 os.mkdir(‘dirname‘) 生成单级目录;相当于shell中mkdir dirname os.rmdir(‘dirname‘) 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname os.listdir(‘dirname‘) 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 os.remove() 删除一个文件 os.rename("oldname","newname") 重命名文件/目录 os.stat(‘path/filename‘) 获取文件/目录信息 os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/" os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n" os.pathsep 输出用于分割文件路径的字符串 win下为;,Linux下为: os.name 输出字符串指示当前使用平台。win->‘nt‘; Linux->‘posix‘ os.system("bash command") 运行shell命令,直接显示 os.environ 获取系统环境变量 os.path.abspath(path) 返回path规范化的绝对路径 os.path.split(path) 将path分割成目录和文件名二元组返回 os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素 os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素 os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False os.path.isabs(path) 如果path是绝对路径,返回True os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 print(os.path.join("D:\\python\\tt","mm")) #做路径拼接用的 D:\python\tt\mm os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间 os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
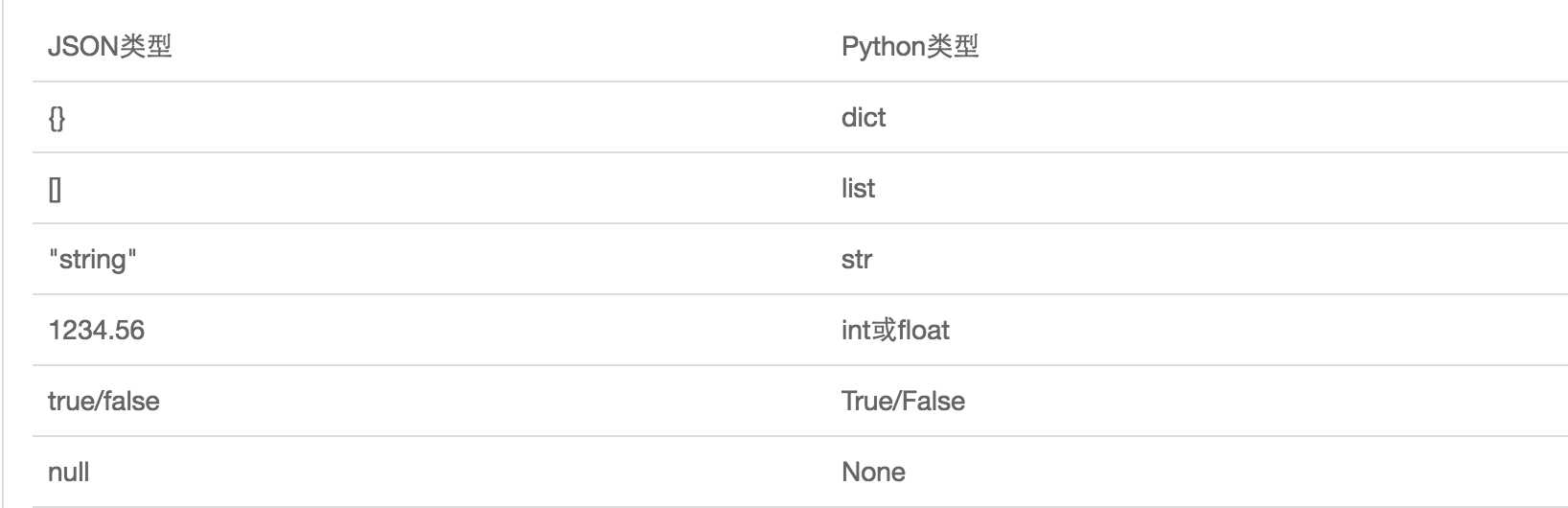
JSON (JavaScript Object Notation) 是一种轻量级的数据交换格式。它基于ECMAScript的一个子集。
JSON和Python内置的数据类型对应如下:
Python3 中可以使用 json 模块来对 JSON 数据进行编解码,它包含了四个函数:
json.dumps(x) 把python的(x)原对象转换成json字符串的对象,主要用来写入文件。
json.loads(f) 把json字符串(f)对象转换成python原对象,主要用来读取文件和json字符串
json.dump(x,f) 把python的(x)原对象,f是文件对象,写入到f文件里面,主要用来写入文件的
json.load(file) 把json字符串的文件对象,转换成python的原对象,只是读文件
json和内置函数的eval()方法,eval将一个字符串转成python对象,不过,eval 方法有局限性,对于普通的数据类型,json.loads和eval都能用,但遇到特殊类型的时候,eval就不管用了所以eval的重点还是通常用来执行一个字符串表达式,并返回表达式的值
什么是序列化:
我们把对象(变量)从内存中变成可存储或传输的过程称之为序列化。
反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化。
json:用于字符串和python数据类型间进行转换。
pickle:用于python特有的类型和python的数据类型间进行转换。
# 写入 JSON 数据 with open(‘data.json‘, ‘w‘) as f: json.dump(data, f) # 读取数据 with open(‘data.json‘, ‘r‘) as f: data = json.load(f)
list = "[1,2,3,4,5,6,‘aa‘]" aa = pickle.dumps(list) print(type(aa)) #<class ‘bytes‘> # print(pickle.dumps(list)) #bytes对象 with open("pickle_new","wb") as p: #注意w是写入str,wb时写入字节 ,wb写入文件是二进制, pickle.dump(list,p) with open("pickle_new","rb") as pickb: #以二进制方式读取 # print(pickle.load(pickb)) #[1,2,3,4,5,6,‘aa‘] print(pickle.loads(pickb.read())) #[1,2,3,4,5,6,‘aa‘]
注:pickle的问题和所有其他编程语言特有的序列化的问题一样,就是pickle它只能用于python,并且可能不同版本的python彼此都不兼容,因此,只能用pickle保存那些不重要的数据,不能成功的反序列化也没关系。
原文:https://www.cnblogs.com/lq0310/p/9509472.html