**本文恐怕不是完全的标题党**
视频多目标跟踪需要解决的关键点是前后两帧之间的Target Association,这是最难的环节(没有之一)。第T帧检测到M个目标,第T+S(S>=1)帧检测到N个目标,怎样将这M*N对目标正确地关联起来,是“跟踪算法”最难的环节。(注意这里提到的是多目标,单目标跟踪很简单)
通常的跟踪方式是根据目标中心点距离、IOU(目标区域的交并比)等这些纯物理指标进行关联,中心点距离越小、IOU越大(区域重合面积越大),则认为是同一个目标。这种方式优点就是简单、匹配速度快,而缺点就是当碰到目标被遮挡、目标过于密集、视频跳帧太大检测等情况时,跟踪就会失败。
高级的跟踪方式(本文主要讲述的方式)不仅会考虑上面提到的目标物理特性,还会计算前后两帧中目标的外观特征(Appearance Feature)相似度。这里的外观特征不是传统的提取图像特征,更不是通过比较两张图的颜色直方图来进行对比分析。而是需要训练单独的模型(区分于目标检测阶段),通过该模型计算每个目标的外观特征值,然后计算特征值之间的“余弦距离”来比较两个目标的相似度。这种方式可以有效地解决**目标被遮挡**、**目标过于密集**、**视频跳帧检测分析**等问题,缺点就是引入了另外一个特征提取模型,速度相对来说要慢一些。对于那些每秒处理帧数要求不高的场合,此种方式尤其有效。下图是通过该方法进行目标跟踪的效果(模型效果一般,目标容易跟丢):

可以看到,目标消失后再出现时,仍然能够准确跟踪到。目标非常密集,但是也并不影响最终跟踪效果。
多目标跟踪一般流程
在**Tracking By Detecting**的模式下,要想跟踪目标,先要将视频中的目标检测出来,这一步称为“目标检测”,然后根据检测得到的结果,将每帧中的目标关联起来。目标检测算法很多,SSD和YOLO等,网上开源实现版本也有很多。
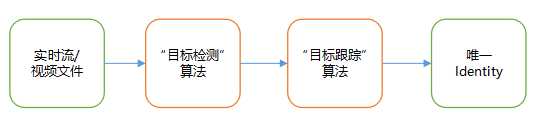
如上图,经过检测算法处理之后得到的结果只有物理上的特性,帧与帧之间不存在任何关联,只有通过跟踪算法处理之后,才能加入时序的特性。
跟踪算法初级版本
该方式只考虑前后两帧中每个目标的物理特性,中心点位置以及IOU,通过分析这两个特性来关联前后帧中的目标。
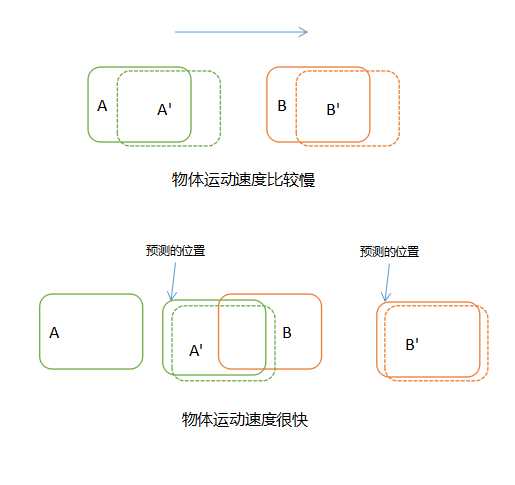
如上图所示,实线方框代表目标在前一帧中的实际位置和下一帧中的预测位置,虚线框代表目标在下一帧中的实际位置,通过计算下一帧实际位置与前一帧的预测位置的IOU,来关联目标。IOU越到,代表重合度越高,越高则代表为同一目标,赋予唯一TrackId。关于该部分的详细内容,可以参见上一篇博客。
跟踪算法高级版本
该方式会引入另外一个外观特征提取模型(网上搜Person Re-Id,或参见本文末尾),对于每个检测到的目标,先利用该模型计算它的特征(可以理解为该目标的一种特征编码),然后计算每个目标特征之间的余弦距离。余弦距离越小(注意:这里指1-余弦距离,参见后面关于距离的说明),代表目标越相似,通过它可以作为关联目标的一种指标。
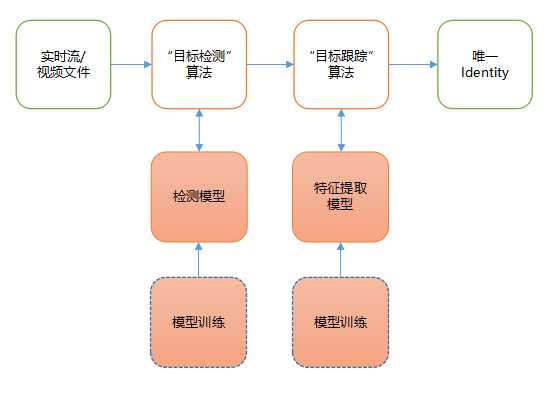
如上图,除了在目标检测环节需要提前训练模型之外,跟踪环节也需要训练相应的模型。因此,该方式不但会增加前期准备工作,还会增加算法运行时间。
该方式的详细执行流程如下:
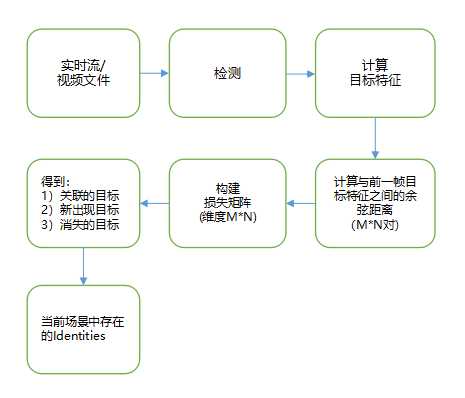
逻辑相当简单,难的是找到计算Appearance Feature的模型,github上有相应的算法实现:https://github.com/nwojke/cosine_metric_learning,该算法可以训练提取特征的模型。注意,如果训练数据只包含行人,那么训练出来的模型只适合计算行人的Appearance Feature(其他物体也能计算,但是不准确)。
该仓库中给出的示例代码是用来训练行人数据集的,所以对于行人特别有效。目前我正尝试训练车辆的数据集,待结果出来之后再更新此博客。
关于机器学习中的各种距离
欧几里得距离(欧氏距离)
该距离很简单,就是我们从小到大接触到的N维空间中两点的直线距离,对于最常见的2/3维空间两点的距离计算公式为:
Distance = numpy.sqrt((x1-x2)**2 + (y1-y2)**2 + (z1-z2)**2) (三维空间两点距离)
欧式距离越小,代表两者越接近相同,当距离为零时,代表两者完全相同。
余弦距离
余弦距离表示N维空间中两点与原点连接线段之间夹角的余弦值。余弦距离越大,表示夹角越小,那么两点越相似。如果余弦距离为1(最大值),那么表示两者非常相似。注意这里只能说明两点非常相似,并不一定相同。摘自网上的一幅图:
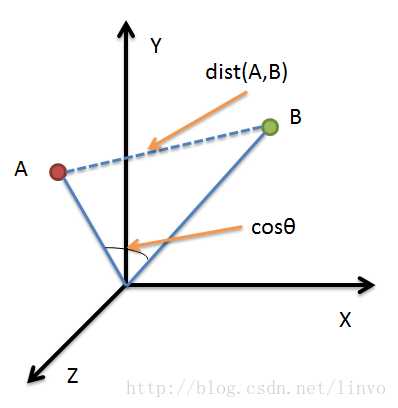
余弦距离的意义:
当两点夹角为零时,表示两点的各个维度的值所占的比例相同。比如(2,2,2)和(6,6,6),(1,2,3)和(3,6,9)。对应本文中计算Appearance Feature特征值之间的余弦距离,实际意义就是比较特征值(比如128维)中每一个维度值所占的比例是否相等,越接近相等,说明特征值对应的图片越相似。
Person Re-Id/ Vehicle Re-Id也是一个值得研究的方向,通过给定query target,可以在多个视频中搜索该目标,一般可以用于公安罪犯抓捕、违法车辆搜索等领域。虽然传统的人脸识别方式已经很成熟了,用人脸识别技术可以在城市监控摄像头中准确定位犯罪分子,但是通常情况下,监控摄像机拍摄到的人脸并不清晰,所以人脸识别准确率不高。而Person Re-Id(或者Vehicle Re-Id或者其他什么ReId)是基于整体轮廓进行特征提取的,它不要求看到犯罪份子详细的脸部图片,只需要全身轮廓图片(同时也忽略衣着、拍摄方位、光线、姿态等因素)就可以定位该目标。
本文没有源代码。有问题可以留言。
[AI开发]视频多目标跟踪高级版(离自动驾驶又‘近’了一点点)
原文:https://www.cnblogs.com/xiaozhi_5638/p/9519665.html