一、加上封装之后的布局成本:
在C语言中,“数据”和“处理数据的操作”(函数)是分开来声明的,语言本身并不具备“数据和函数”的关联。过程性的语言(典型代表为C)过程性是由一组“分布在各个以功能为导向的函数中”的算法所驱动。它们处理的是共同的外部数据。举例:
typedef struct point3d {
float x;
float y;
float z; } Point3d;
欲打印一个point3d,就需要定义一个函数,若要高效,甚至可以将此函数定义为宏函数,或者是直接在程序中完成其操作。
void print3d_print(const Point3d* pd) { printf("(%g,%g,%g)",pd->x,pd->y,pd->z); }
同理,某个点的坐标值也可以直接存取:Point3d pt;pt.x = 0.0;pt.y = 0.0;pt.z=0.0;(此处为了;能明显一点显示,将其转换成全角格式)由此可以看到,过程性的语言之间数据和函数是互相独立,之间并不存在某种特定的关系;
在C++当中,Point3d可以采取独立的“抽象数据类型(“abstract data type,ADT”)来实现,即将数据和处理数据的操作(函数)封装在一个整体(类)中:
class Point3d { public: Point3d(float x = 0.0,float y = 0.0,float z = 0.0):_x(x),_y(y),_z(z) {} float x() {return _x;} float y() {return _y;} float z() {return _z;} void x(float xval) {_x = xval;} void y(float yval) {_y = yval;} void z(float zval) {_z = zval;} private: float _x,_y,_z; }; inline ostream& operator<<(ostream& os,const Point3d& pt) { os<<"("<<pt.x()<<","<<pt.y()<<","<<pt.z()<<")"; };
在上述C Struct中,定义一个Struct Object:Point3d d1与在C++ Class中,定义一个Class Object: Point3d d2,从C语言到C++,将处理数据的操作(函数)封装到Class中,布局成本是否增加,换句话说,在相同的环境下sizeof(d2)的值是否大于sizeof(d1)的值,答案是否定的。加上封装之后布局成本并没有增加,虽然成员函数在class的声明当中,但是它并没有出现在class object中,每一个非内联成员函数只会诞生一个函数实例。至于每一个“拥有零个或一个定义”的内联函数则在其每一个使用者身上产生一个函数示例。C++的这种封装性质,并不会对其空间和执行期带来不良后果;其实,C++的布局成本主要体现在:1、virtual function机制;2、虚继承时virtual base class;
二、C++对象模式:
在C++中,数据成员(class data members)有2种:静态(static)和非静态(nonstatic),成员函数(class member function)有3中:静态(static)、非静态(nonstatic)和虚拟(virtual),考虑抽象以下一个类类型:
class Point { public: Point(float xval); virtual ~Point(); float x() const; static int PointCount(); protected: virtual ostream& print(ostream& os) const; float _x; static int _point_count; };
在这个class Point中,如何模塑出各种数据成员和成员函数呢?
1)、简单对象模型
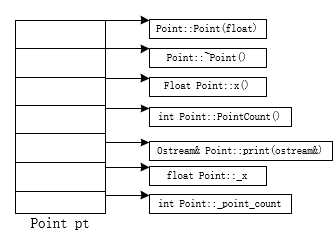
在此模型中,每一个class object都是一系列的槽(slot),而这个槽当中存放的是每一个member(包含数据和函数)的地址,很容易得到一个class object的大小为:指针的大小乘class中声明的成员个数;问题1:为什么要采用此模型?答:此模型的优点:简单,容易设计。但是此模型的缺点也异常明显:空间和时间效率都很低;问题2:为什么class object要存放成员的地址?答:这么做的原因是在class object都是指针类型,对象的大小很容易计算,如果保存的直接是成员,那么成员的类型不确定;
2)、表格驱动模型:
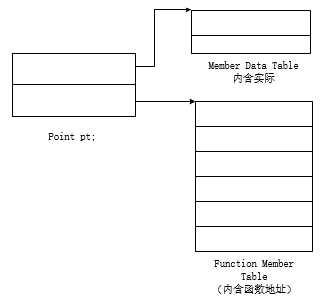
在此模型当中,为了对所有类的所有对象都有一致的表现形式,此模型吧所有与成员相关的信息都抽取出来,数据成员放在Member Data Table当中,成员函数放在Function Member Table当中,Function Member Table则是一列slot,每个slot指向一个成员函数,而Member Data Table中则直接存放数据成员。在此模型当中,每一个class实例出来的object在×86系统当中,都只占有8个字节的内存空间。但是这种表格驱动模型最终也没有实际应用于真正的C++编译器当中,但是Function Member table却成为后来支持Virtual function的一个有效的方案,在后来的编译器当中,virtual function都被保存在一系列的slot中。
3)、C++对象模型:
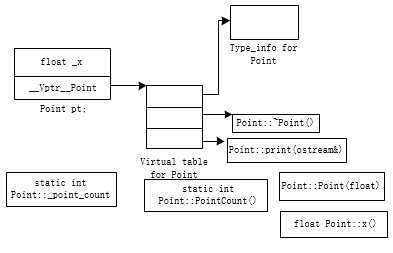
在后来的C++对象模型当中,可以看到non-static Data Member被直接保存在对象当中;如果class中有虚拟函数,则会为对象模型在增加一个Vptr指针,此指针指向一个包含用以支持RTTI的type_info object以及一系列的Virtual function地址的表格,值得一提的是,在virtual table中,地址由低到高分别为:type_info 以及在类中按申明顺序排列的一系列虚函数的地址;至于成员函数(包括静态与非静态)以及静态数据成员都被散列在对象内存之外;
总结:在三种对象模型当中:
1、第一种简单对象模型:优点:简单明了;缺点:赔上了空间及执行期的效率;
2、第二种表格驱动模型:优点:较简单模型来说,提供了较大的弹性,因为在类中如果成员有变动(可能是增加,溢出或是更改),那么此模型生成的对象大小依然恒定。从另一方面来说,此模型实例化之后的对象也在空间上比简单对象模型要轻量;缺点:不论是访问数据成员还是成员函数,都多了一层间接性,需要指针的指针才能对具体的成员进行访问,执行期效率降低;
3、第三种也就是后来普遍C++编译器所采用的对象模型:优点:较前两种模型来说,此模型最大的不同是将成员函数,静态数据成员都放在对象之外,当要用到这些成员时,通过一个this指针将对像和成员进行关联。此外,在对象中,通过一个vptr实现了RTTI以及后来的多态的特性。在执行效率以及空间上都做了一些改进。缺点:弹性限度较表格模型来说不够,因为如果类成员发生变动,那么随之而来的对象也要发生改变,要进行重新编译。
原文:https://www.cnblogs.com/xin-99/p/9515351.html