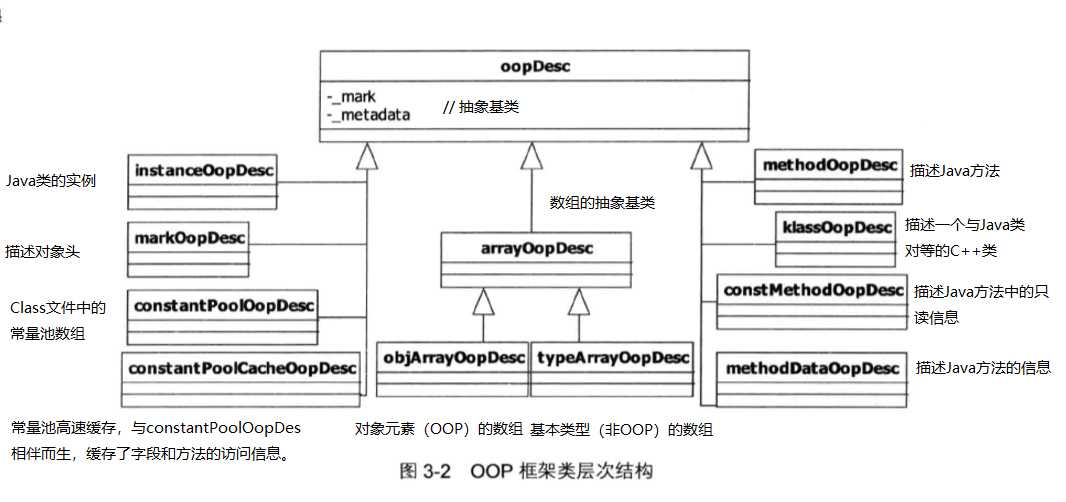
class oopDesc{
private:
volatile markOop _mark;
union _metadata{
wideKlassOop _klass; // 64位系统下,从32位增长位64位
narrowOop _compressed_klass; // 开启-XX:UseCompressedOops才选用,32位指针
} _metadata; //元数据指针
}

注:互斥量就是Monitor。
参考:《Java并发编程的艺术》 第二章节
普通函数调用原理:执行到函数调用指令时,程序将在函数调用后立即存储该指令的内存地址,并将函数参数复制到堆栈(为此保留的内存块),跳到标记函数起点的内存单元,执行函数代码(也许还需将返回值放入寄存器中),然后跳回到地址被保存的指令。
简言之,普通函数调用需要保护现场(main函数运行到第几行指令进栈)-> 调用函数(复制main函数中的参数副本) -> 恢复现场(出栈返回结果至main函数的第几行指令)。这是存在系统资源开销的,如何将调用函数的代码直接嵌入到主函数就没了这个开销。(参考:https://blog.csdn.net/buptzhengchaojie/article/details/50568789)
内联函数:短小精炼的代码,在编译阶段将函数体嵌入到每一个调用该函数的语句块中,最大程度降低调用开销。
OopDesc中的部分内联函数
// 初始化mark word
inline void oopDesc::init_mark()
// 是否是类实例
omit ...
// 是否是数组
omit ...
// 原子操作设置mark word
inline markOop oopDesc::cas_set_mark(markOop new_mark,markOop old_mard){
// cmpxchg加Lock前缀能够在多核下锁住总线,使得只有单个CPU操作共享内存中的变量.
return (markOop) Atomic::cmpxchg_ptr(new_mark,&_mark,old_mark)
}
// 获取对象对应的类型klass
inline klassOop oopDesc::klass() const{
if(UseCompressedOops){
return (klassOop)decode_heap_oop_not_null(metadata.compressed_klass);
}else{
return metadata.klass;
}
}参考1:https://www.jianshu.com/p/8c3c0426e4f7
参考2:http://www.lenky.info/archives/2012/11/2028
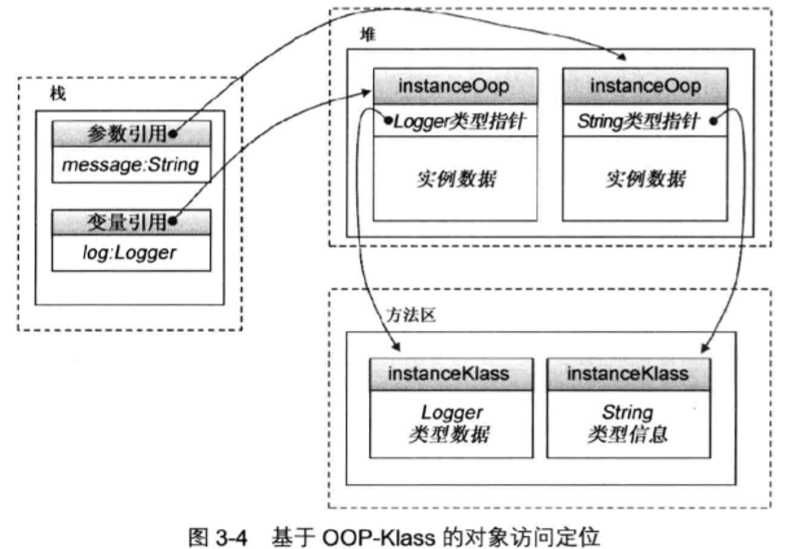

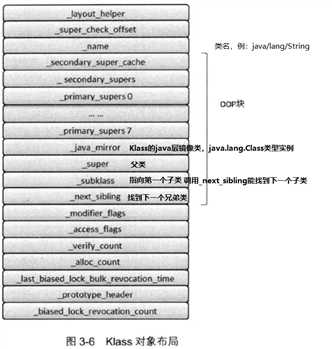
对于instance而言,_layout_helper值为正,代表instance的大小
对于数组Klass,_layout_helper值为负,如下图所示:

HotSpot 为每一个加载的Java类创建一个instanceKlass对象,用于在JVM层表示Java类。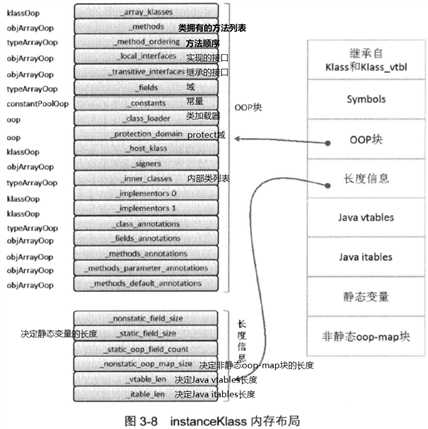
默认为longs/doubles、ints、shorts/chars、bytes/booleans、OOPS的顺序分配。
父类中定义的变量可能出现在子类之前
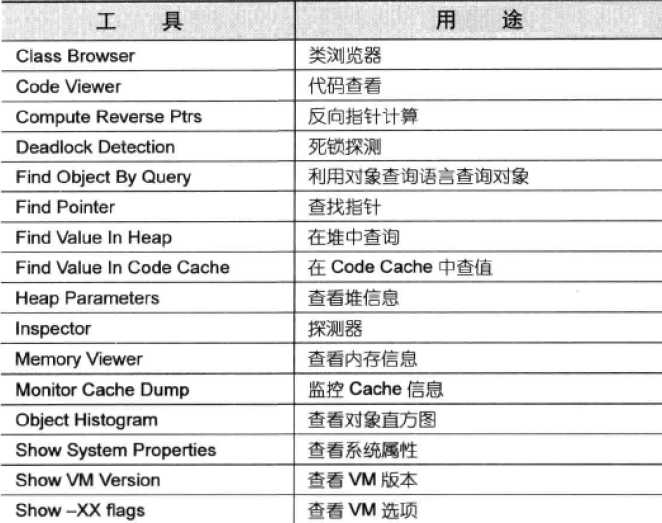
jdk目录下输入:java -cp ./lib/sa-jdi.jar sun.jvm.hotspot.HSDB注:如果遇到sawindbg.dll不存在,参考该地址解决:https://blog.csdn.net/fl_zxf/article/details/42689569
jvm规范(JavaSE 10):https://docs.oracle.com/javase/specs/jvms/se10/jvms10.pdf
ClassFile {
u4 magic; // value 常数: 0xCAFEBABE
u2 minor_version;
u2 major_version; // java8为例 45.0<=version<=52.0
u2 constant_pool_count;
cp_info constant_pool[constant_pool_count-1];
u2 access_flags; // 访问标识,如public final abstract super interface 等
u2 this_class; // 当前类:记录一个有效的常量池下标
u2 super_class; // 超类,同上
u2 interfaces_count;
u2 interfaces[interfaces_count];
u2 fields_count;
field_info fields[fields_count];
u2 methods_count;
method_info methods[methods_count];
u2 attributes_count;
attribute_info attributes[attributes_count];
}// 常量池项
cp_info{
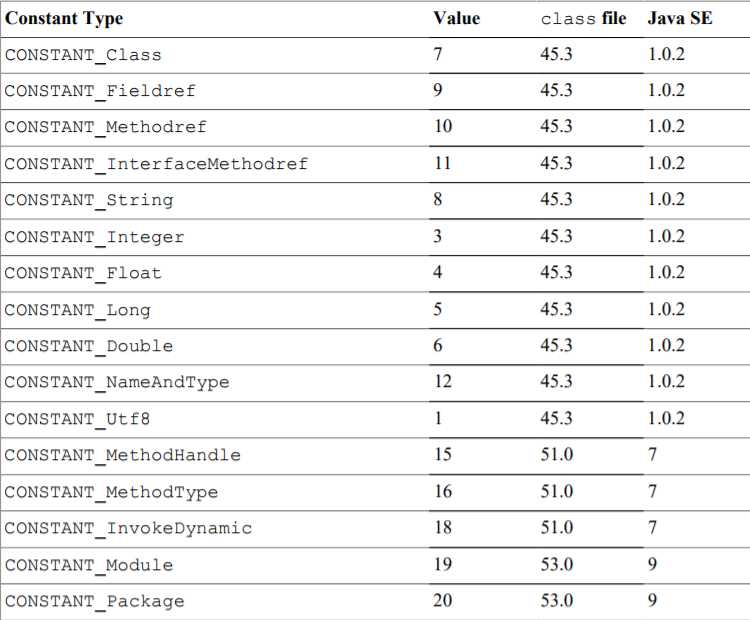
u1 tag; // 不同的值代表不同的类型,参照下图
u1 info[];
}
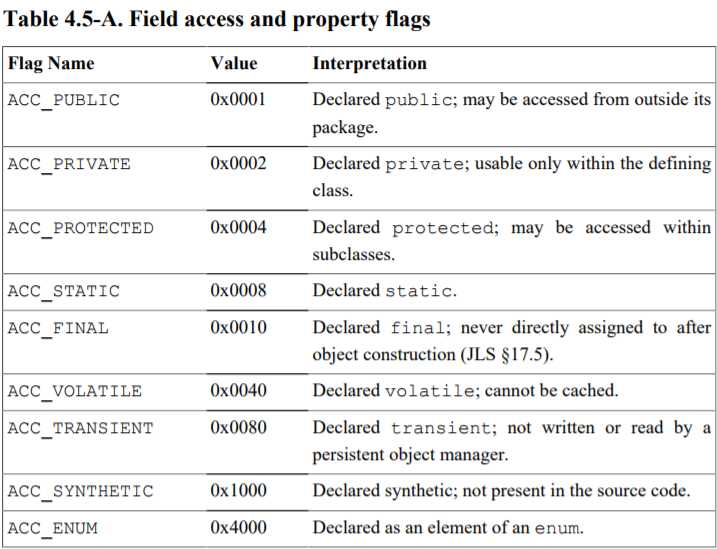
field_info{
u2 access_flags;
u2 name_index; // 常量池索引,该字段的全限定名
u2 descriptor_index; // 常量池索引,字段的描述符
u2 attributes_count; // 字段附加属性数量
attribute_info attributes[attributes_count];
}
method_info{
u2 access_flags; // 与字段表类似,具体参考jvm规范手册
u2 name_index;
u2 descriptor_index;
u2 attributes_count;
attribute_info attributes[attributes_count];
}attribute_info{
u2 attribute_name_index;
u4 attribute_length;
u1 info[attribute_length]; // 属性
}
注:visualvm能进行性能统计:类加载时间等
调试参数:-XX:TraceClassLoading -XX:TraceClassLoadingPreorder
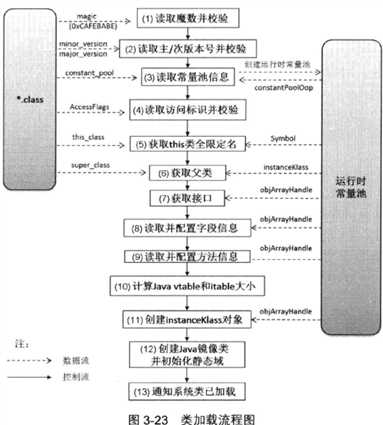
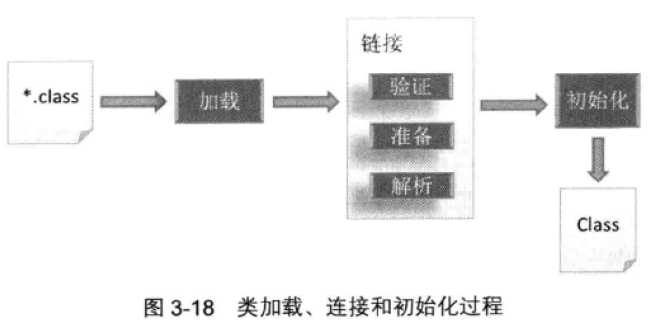
Class文件中有个静态常量池,加载成功后,静态常量池中的符号引用转化为直接引用并对接运行时常量池的过程称为解析。当符号引用首次被访问时才去解析(Hotspot,不同JVM有不同实现)。
下图是instanceKlass类中定义了链接过程link_class_impl(),主要步骤如下: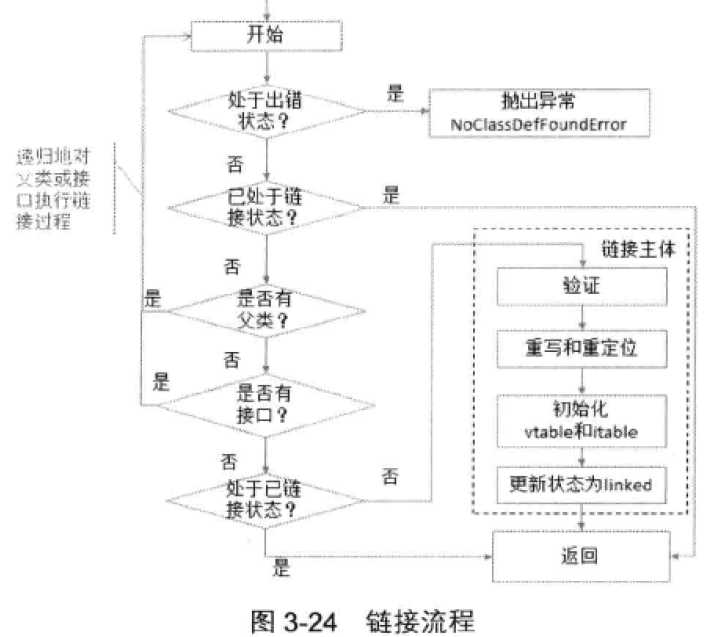
最重要的方法解析:
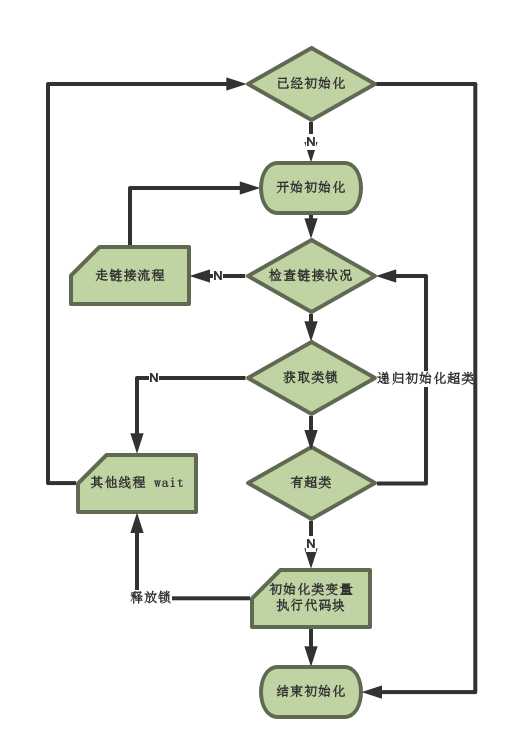
字节码new表示创建对象,JVM遇到这个指令,从栈顶取得目标对象在常量池中的索引,接着定位目标对象的类型,根据JVM中该类的状态,采取相应的内存分配技术(根据类是否已经初始化),在内存中分配实例空间,并完成实例数据和对象头的初始化。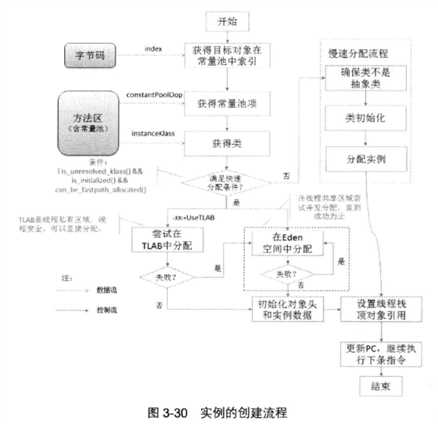
原文:https://www.cnblogs.com/linzhanfly/p/9552910.html