
前言
从2011年开始,中国进入大数据风起云涌的时代,以Hadoop为代表的家族软件,占据了大数据处理的广阔地盘。开源界及厂商,所有数据软件,无一不向Hadoop靠拢。Hadoop也从小众的高富帅领域,变成了大数据开发的标准。在Hadoop原有技术基础之上,出现了Hadoop家族产品,通过“大数据”概念不断创新,推出科技进步。
目录
Hadoop 最早起源于Nutch 。Nutch 是一个开源的网络搜索引擎,由Doug Cutting 于2002 年创建。Nutch 的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题,即不能解决数十亿网页的存储和索引问题。
随之,谷歌发表的两篇论文为该问题提供了可行的解决方案。一篇是2003 年发表的关于谷歌分布式文件系统(GFS)的论文。该论文描述了谷歌搜索引擎网页相关数据的存储架构,该架构可解决Nutch 遇到的网页抓取和索引过程中产生的超大文件存储需求的问题。但由于谷歌仅开源了思想而未开源代码,Nutch 项目组便根据论文完成了一个开源实现,即Nutch 的分布式文件系统(NDFS)。
另一篇是2004 年发表的关于谷歌分布式计算框架MapReduce 的论文。该论文描述了谷歌内部最重要的分布式计算框架MapReduce 的设计艺术,该框架可用于处理海量网页的索引问题。同样,由于谷歌未开源代码,Nutch 的开发人员完成了一个开源实现。由于NDFS 和MapReduce 不仅适用于搜索领域,2006 年年初,开发人员便将其移出Nutch,成为Lucene 的一个子项目,称为Hadoop。
大约同一时间,Doug Cutting 加入雅虎公司,且公司同意组织一个专门的团队继续发展Hadoop。同年2 月,Apache Hadoop 项目正式启动以支持MapReduce 和HDFS 的独立发展。2008 年1 月,Hadoop 成为Apache 顶级项目,迎来了它的快速发展期。
目前Hadoop发行版非常多,有华为发行版、Intel发行版、Cloudera发行版(CDH)等,所有这些发行版均是基于Apache Hadoop衍生出来的,之所以有这么多的版本,完全是由Apache Hadoop的开源协议决定的:任何人可以对其进行修改,并作为开源或商业产品发布/销售(http://www.apache.org/licenses/LICENSE-2.0)。
目前而言,绝大多数公司发行版是收费的,比如Intel发行版、华为发行版等,尽管这些发行版增加了很多开源版本没有的新feature,但绝大多 数公司选择Hadoop版本时会将把是否收费作为重要指标。
目前而言,不收费的Hadoop版本主要有三个(均是国外厂商),分别是:Apache(最原 始的版本,所有发行版均基于这个版本进行改进)、Cloudera版本(Cloudera’s Distribution Including Apache Hadoop,简称“CDH”)、Hortonworks版本(Hortonworks Data Platform,简称“HDP”)。
当前Apache Hadoop 版本非常多,本小节将来梳理各个版本的特性以及它们之间的联系。在讲解Hadoop 各版本之前,先要了解Apache 软件发布方式。
对于任何一个Apache 开源项目,所有的基础特性均被添加到一个称为“trunk”的主代码线(maincodeline)。当需要开发某个重要的特性时,会专门从主代码线中延伸出一个分支(branch),这被称为一个候选发布版candidate release)。该分支将专注于开发该特性而不再添加其他新的特性,待基本bug 修复之后,经过相关人士投票便会对外公开成为发布版(releaseversion),并将该特性合并到主代码线中。需要注意的是,多个分支可能会同时进行研发,这样,版本高的分支可能先于版本低的分支发布。
由于Apache 以特性为准延伸新的分支,故在介绍Apache Hadoop 版本之前,先介绍几个独立产生的Apache Hadoop 新版本的重大特性:
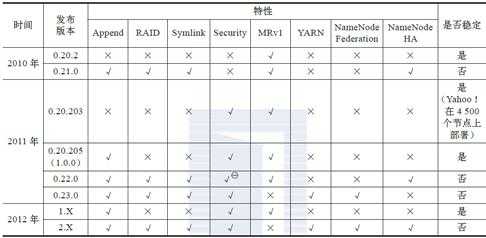
到2012 年5 月为止,Apache Hadoop 已经出现四个大的分支,如下图所示。Apache Hadoop 的四大分支构成了四个系列的Hadoop 版本。

0.20.2 版本发布后,几个重要的特性没有基于trunk 而是在0.20.2 基础上继续研发。值得一提的主要有两个特性:Append 与Security。其中,含Security 特性的分支以0.20.203版本发布,而后续的0.20.205 版本综合了这两个特性。需要注意的是,之后的1.0.0 版本仅是0.20.205 版本的重命名。0.20.X 系列版本是最令用户感到疑惑的,因为它们具有的一些特性,trunk 上没有;反之,trunk 上有的一些特性,0.20.X 系列版本却没有。
Common 模块: 最大的新特性是在测试方面添加了Large-Scale Automated TestFramework 和Fault Injection Framework;
HDFS 模块 :主要增加的新特性包括支持追加操作与建立符号连接、SecondaryNameNode 改进(Secondary NameNode 被剔除,取而代之的是Checkpoint Node,同时添加一个Backup Node 的角色,作为NameNode 的冷备)、允许用户自定义block放置算法等;
MapReduce 模块 :在作业 API 方面,开始启动新 MapReduce API,但老的 API 仍然兼容。0.22.0 在0.21.0 的基础上修复了一些bug 并进行了部分优化。
0.23.X 是为了克服Hadoop 在扩展性和框架通用性方面的不足而提出来的。它实际上是一个全新的平台,包括分布式文件系统HDFS Federation 和资源管理框架YARN 两部分,可对接入的各种计算框架(如MapReduce、Spark 等)进行统一管理。它的发行版自带MapReduce 库,而该库集成了迄今为止所有的MapReduce 新特性。
同0.23.X 系列一样,2.X 系列也属于下一代Hadoop。与0.23.X 系列相比,2.X 系列增加了NameNode HA 和Wire-compatibility 等新特性。
Cloudera的开源Apache Hadoop发行版,亦即(Cloudera Distribution including Apache Hadoop,CDH),面向Hadoop企业级部署。Cloudera称,其一半以上的工程产出捐赠给了各个基于Apache许可与Hadoop紧密相连的开源项目(Apache Hive、Apache Avro、Apache HBase等等)。Cloudera还是Apache软件基金会的赞助商。
CDH3版本是基于apache hadoop 0.20.2改进的,并融入了最新的patch,目前看来,最新的cdh3u6基本可以对应到apache hadoop最新版本(Hadoop 1.x),而cdh3u1~cdh3u5与apache hadoop版本对应的关系不明确,因为cdh总是打入一些最新的patch进去,并比apache hadoop同功能版本提早发布。总体上说,apache和cdh版本功能上是一致的。
CDH4版本是基于Apache hadoop 2.X改进的,CDH总是并应用了最新Bug修复或者Feature的Patch,并比Apache hadoop同功能版本提早发布,更新速度比Apache官方快。
CDH5是在apache hadoop 2.2.0基础上开发的,将Hadoop生态系统的各个软件打包在一起,因此不存在软件间兼容问题(比如将pig和hive运行在hadoop 2.0上,应该怎么样选择版本等这样的问题),非常容易使用。
下载地址是:http://archive.cloudera.com/cdh5/cdh/5/, 文档:http://www.cloudera.com/content/support/en/documentation.html, 另外,值得关注的是,CDH5也将Spark纳入进来了,因此,CDH5是一个更加强大而全面的发行版。
2.3.4 下载路径
基于以上考虑,如果线上使用,推荐cdhX最新版本,(相当于apache hadoop稳定版),下载地址为:http://archive.cloudera.com/cdh5/cdh/5/。
HDP版本是比较新的版本,目前与apache基本同步,因为Hortonworks内部大部分员工都是apache代码贡献者,尤其是Hadoop 2.0的贡献者。
注释:
[1]Cloudera(英语:Cloudera, Inc.)是一家位于美国的软件公司,向企业客户提供基于Apache Hadoop的软件、支持、服务以及培训。2009年3月《纽约时报 》的一篇博客报道了Cloudera[1] 。三名来自谷歌、雅虎和脸书的工程师(Christophe Bisciglia、Amr Awadallah和Jeff Hammerbacher)与一位甲骨文前高管(迈克 · 奥尔森)加入该公司。奥尔森先前担任SleepycatSoftware首席执行官,他还是开源嵌入式的数据库引擎BerkeleyDB(2006年被甲骨文收购)的创始人。Hammerbacher过去在脸书使用Hadoop构建涉及海量用户数据的分析程序。
原文:http://www.cnblogs.com/joqk/p/3867404.html