一集合:是一个没有重复数据,无序的组合。
集合可以有任意数量的元素,它们可以是不同的类型(例如:数字、元组、字符串等)。但是,集合不能有可变元素(例如:列表、集合或字典)。如下图:
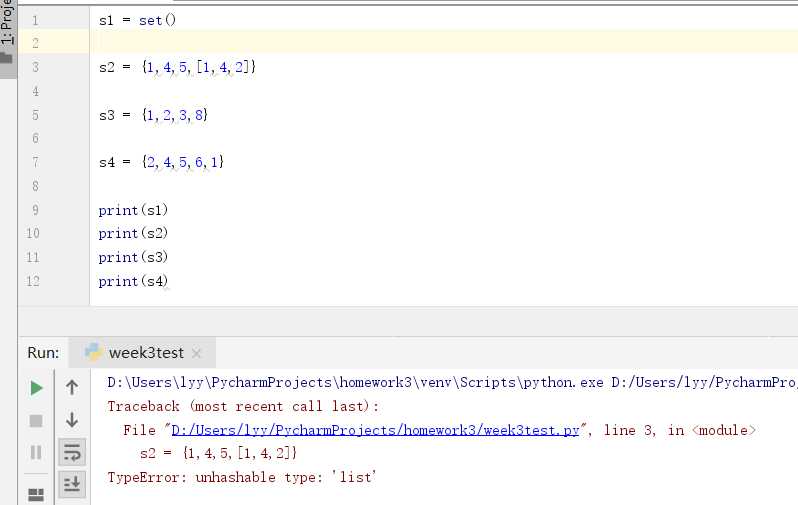
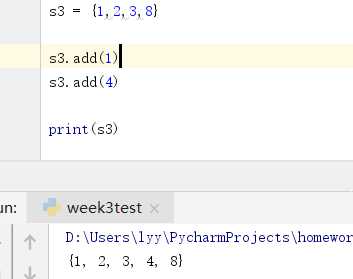
虽然集合不能有可变元素,但是集合本身是可变的。也就是说,可以添加或删除其中的元素。如下图:
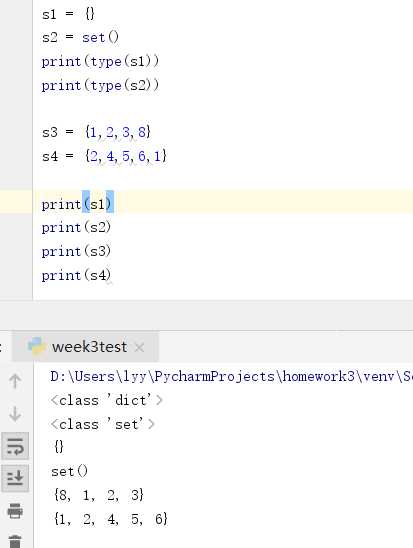
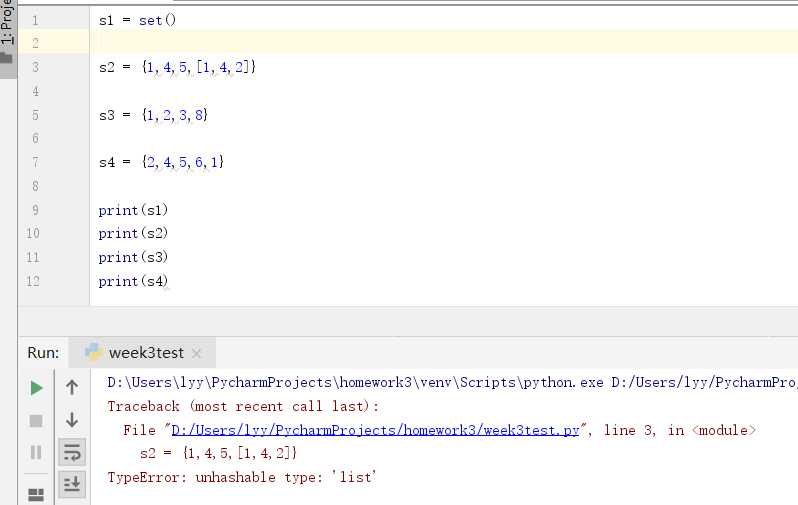
创建空集合比较特殊。在 Python 中,空花括号({})用于创建空字典。要创建一个没有任何元素的集合,使用 set() 函数(不要包含任何参数)。如下图:
由于集合是无序的,所以索引没有任何意义。也就是说,无法使用索引或切片访问或更改集合元素
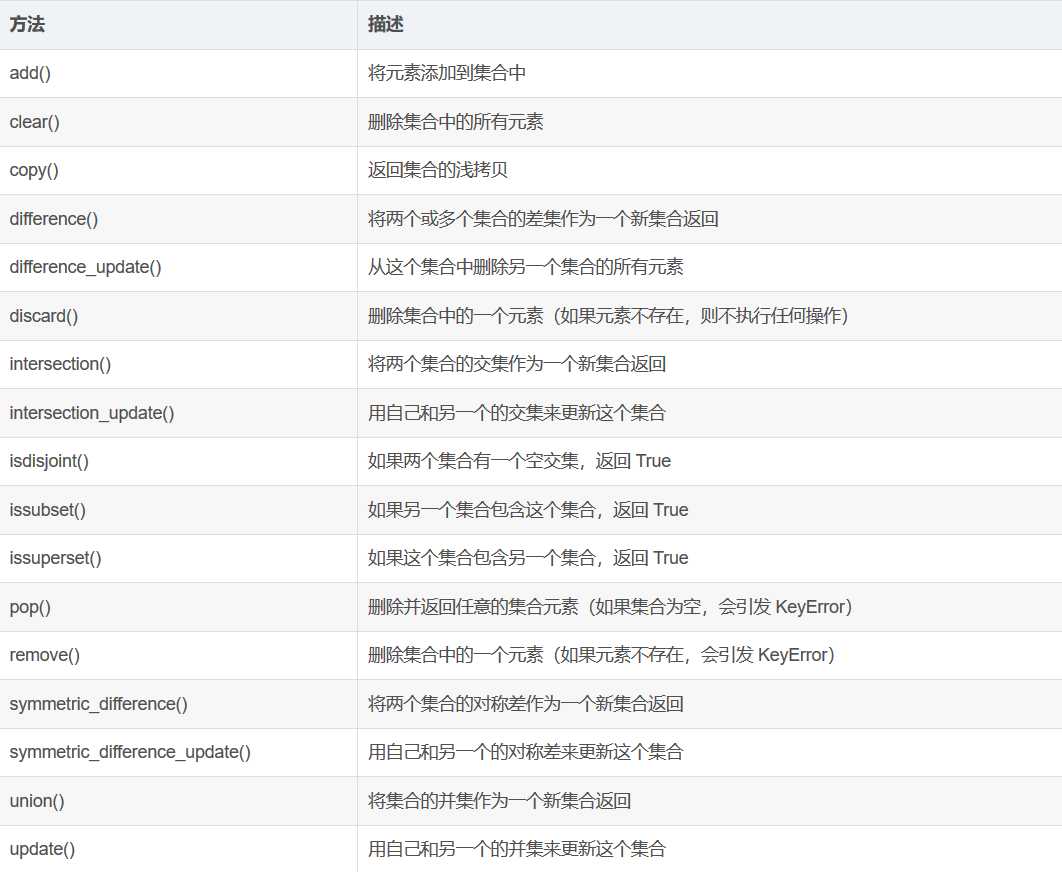
集合常用的方法,如下图。
验证集合间关系的方法调用 ,如下图:
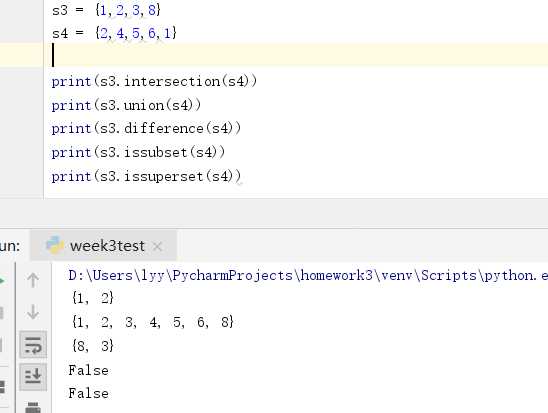
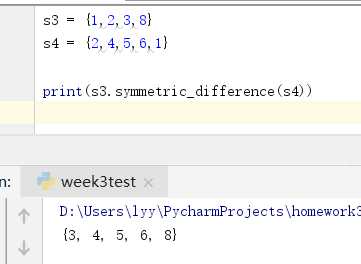
关于对称差集的使用:
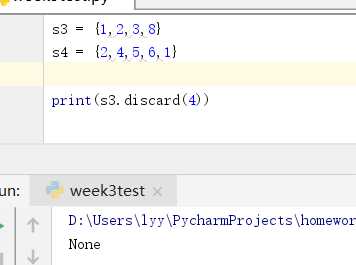
关于删除的三种方式的补充说明:
pop()方法为随机删除一个元素。并不常用。
discard()方法删除指定元素,若该元素不存在,返回none。
remove()方法删除指定元素,若该元素不存在,在报错。
二 文件操作:
关于文件句柄:

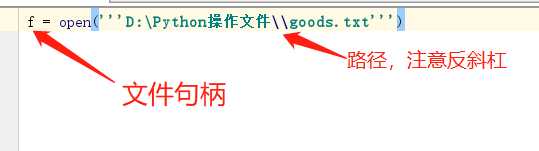
三种读文件的方式:
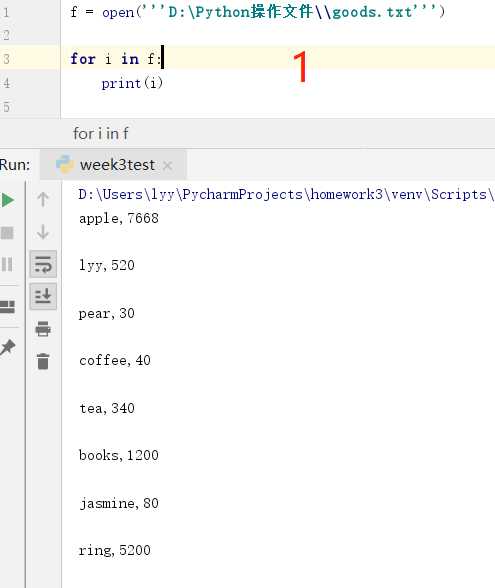
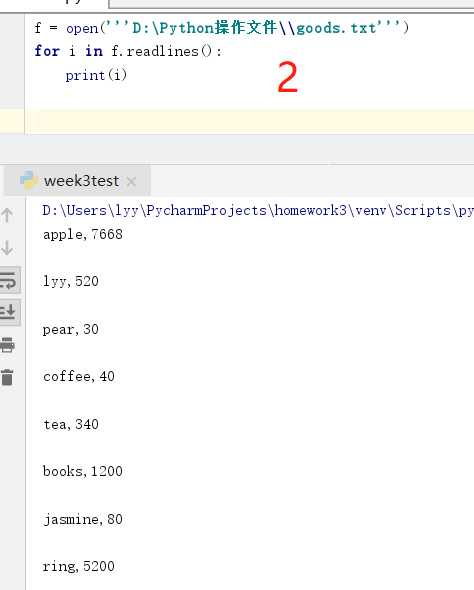
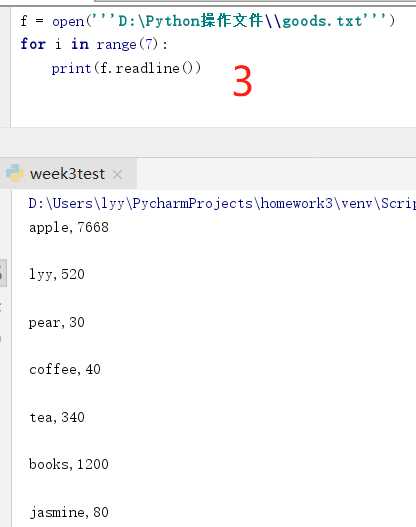
方法1 : 读一行,删一行,在内存中只放一行。
方法2 : 一次性把所有文件读入内存,容易造成内存不足,溢出。
方法3 :读一行,放入内存一行,循环的后期也容易造成内存不足,溢出。
建议使用第一种方法读取数据。
文件句柄的方法:

f.flush() #讲文件内容从内存刷到硬盘(python3.x)
f.closed #文件如果关闭则返回True
f.encoding #查看使用open打开文件的编码
f.tell() #查看文件处理当前的光标位置
f.seek(3) #从开头开始算,将光标移动到第三个字节
关于文件的关闭:
在文件打开使用的状态出错,是不会执行后面的close()操作的。这样会导致资源浪费。所以建议使用with。with结束之后,自动关闭。如下图:
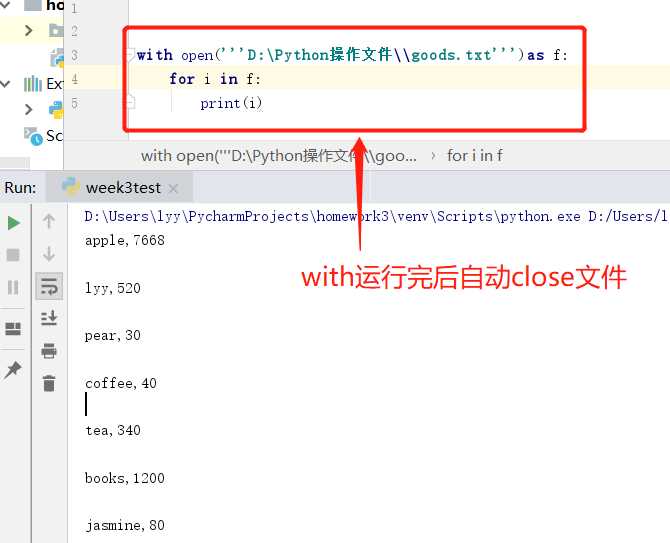
关于r,w,a的区别:

需要注意的是,open中默认为r模式。w模式,若文件没有,则创建新文件,若文件存在,则覆盖源文件。a模式,表示在原文件中追加。
r+ 模式常用。
三编码:
unicode:简单粗暴,所有字符都是2Bytes,优点是字符->数字的转换速度快,缺点是占用空间大
utf-8:精准,对不同的字符用不同的长度表示,优点是节省空间,缺点是:字符->数字的转换速度慢,因为每次都需要计算出字符需要多长的Bytes才能够准确表示

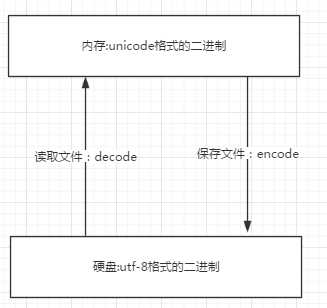
需要注意:
utf-8是unicode 的一个可变长度的扩展集。
Python中默认所有的字符格式为Unicode,
原文:https://www.cnblogs.com/lyy9902/p/9580056.html