Python爬虫教程-34-分布式爬虫介绍
安装 scrapy_redis
- 1.打开【cmd】
- 2.进入使用的 Anaconda 环境
- 3.使用 pip 安装
4.操作截图
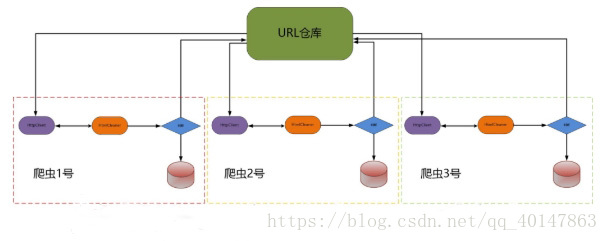
分布式爬虫的结构
主从分布式爬虫
- 所谓主从模式,就是由一台服务器充当 master,若干台服务器充当 slave,master 负责管理所有连接上来的 slave,包括管理 slave 连接、任务调度与分发、结果回收并汇总等;每个 slave 只需要从 master 那里领取任务并独自完成任务最后上传结果即可,期间不需要与其他 slave 进行交流。这种方式简单易于管理,但是很明显 master 需要与所有 slave 进行交流,那么 master 的性能就成了制约整个系统的瓶颈,特别是当连接上的slave数量庞大的时候,很容易导致整个爬虫系统性能下降
- 主从分布式爬虫结构图:
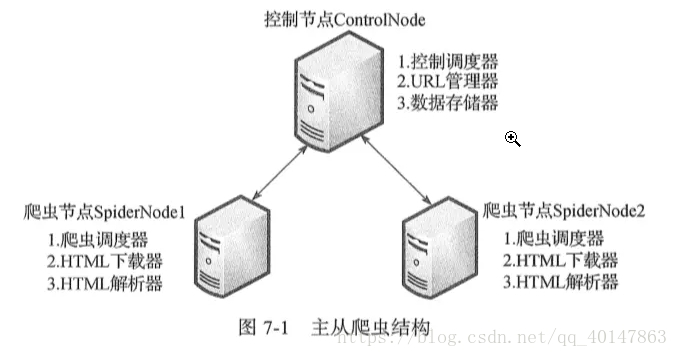
这是经典的主从分布式爬虫结构图,图中的控制节点ControlNode就是上面提到的master,爬虫节点SpiderNode就是上面提到的slave。下面这张图展示了爬虫节点slave的执行任务示意图
- 控制节点执行流程图:
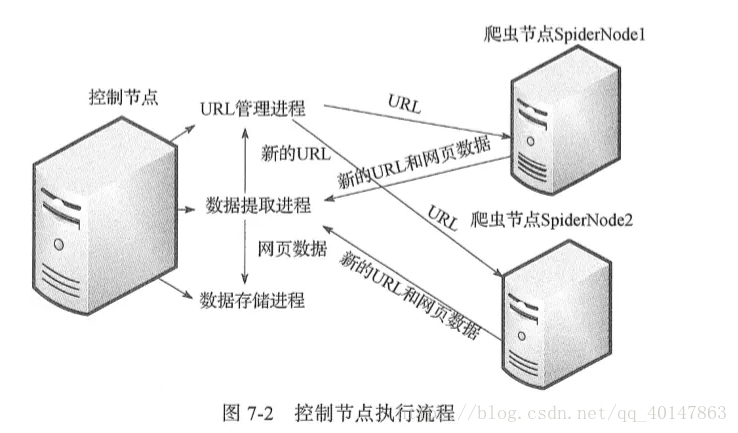
- 这两张图很明了地介绍了整个爬虫框架,我们在这里梳理一下:
- 1.整个分布式爬虫系统由两部分组成:master控制节点和slave爬虫节点
- 2.master控制节点负责:slave节点任务调度、url管理、结果处理
- 3.slave爬虫节点负责:本节点爬虫调度、HTML下载管理、HTML内容解析管理
- 4.系统工作流程:master将任务(未爬取的url)分发下去,slave通过master的URL管理器领取任务(url)并独自完成对应任务(url)的HTML内容下载、内容解析,解析出来的内容包含目标数据和新的url,这个工作完成后slave将结果(目标数据+新url)提交给master的数据提取进程(属于master的结果处理),该进程完成两个任务:提取出新的url交于url管理器、提取目标数据交于数据存储进程,master的url管理进程收到url后进行验证(是否已爬取过)并处理(未爬取的添加进待爬url集合,爬过的添加进已爬url集合),然后slave循环从url管理器获取任务、执行任务、提交结果......
- 本篇就介绍到这里了,拜拜
Python爬虫教程-34-分布式爬虫介绍
原文:https://www.cnblogs.com/xpwi/p/9601064.html