本篇是关于验证码识别问题,也是Python爬虫笔记的一个结尾,使用 Tesseract
Python爬虫教程-29-验证码识别-Tesseract-OCR
- 常见反爬虫手段:
- 验证码
- 1.简单图片,扭曲数字验证码
- 2.中文顺序点击
- 3.动态验证码
- 4.滑动验证:滑动小方块到缺口
- 5.语音验证
- 6.极验验证:官网:http://www.geetest.com/
根据鼠标轨迹,判定是机器人还是用户,很强大的验证机制
- 对于极验是很厉害的拦截机器人手段,好像是使用人工智能机器学习,当然自己想做验证的话建议使用。对于验证有反爬虫,就有可能有反反爬虫
爬虫-验证码识别
通用方法案例
- 能力有限,这里就介绍通用方法,先下载得到验证图片,然后手动输入
- Tesseract
- 机器视觉领域的基础软件
- OCR:OpticalChracterRecognition,光学文字识别
- Tesseract:是一个 OCR 库,由 Google 赞助
Tesseract-Windows的安装
Tesseract-macOS的安装
- 我也没有 MacBook,老师顺口一说,记下了
- brew install tesseract
Tesseract-Linux的安装
- 我这里是 Ubuntu 18 其他 Linux 版本不确定,进入管理员用户
- apt-get install tesseract-ocr
python使用tesseract的工具 pytesseract 的安装
- 如果使用的是 Anaconda 环境:
- 操作截图
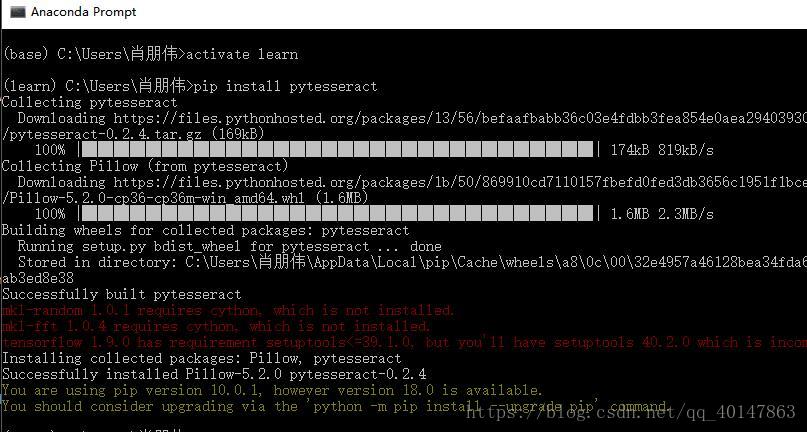
- 首先说一下,conda 是没有这个包的,也就不能使用 conda install,也不能直接在 Pycharm 里找到,只有使用 pip 安装,然后需要注意的就是,要使用你在 Pycharm 使用的那个环境进行安装
识别验证码案例
- 注意:此代码路径是,在图片和代码在同一目录
- 图片截图:

- 代码 py30pytess.py 文件:
import pytesseract as pt
from PIL import Image
# 生成图片实例
image = Image.open(‘timg.jpg‘)
# 调用 pytesseract 识别图片文字
text = pt.image_to_string(image)
print(text)
运行结果
Python爬虫教程-29-验证码识别-Tesseract-OCR
原文:https://www.cnblogs.com/xpwi/p/9601027.html
