在这里我们有一系列点,却没有标签。因此,我们的训练集可以写成只有x(1),x(2),x(3)...一直到x(m),而没有任何标签y.因此,图上画的这些点没有标签信息。也就是说,在非监督学习中,我们需要将一系列无标签的训练数据,输入到一个算法中,然后我们告诉这个算法,快去为我们找找这个数据的内在结构给定数据。 图上的数据看起来可以分成两个分开的点集(称为簇),一个能够找到我圈出的这些点集的算法,就被称为聚类算法。
了解银河系的构成
K-均值是最普及的聚类算法,算法接受一个未标记的数据集,然后将数据聚类成不同的组
重复步骤 2-4 直至中心点不再变化。
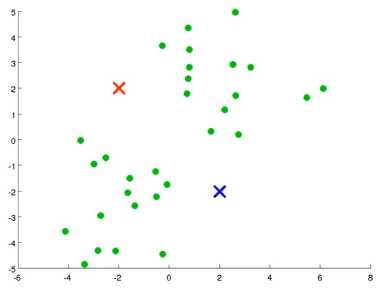
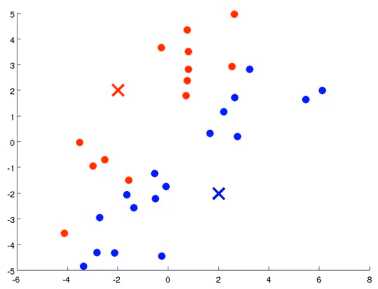
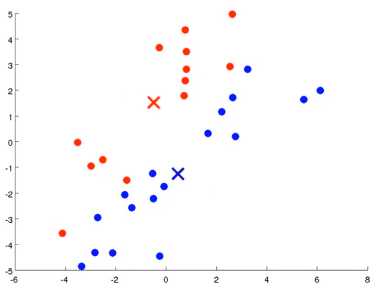
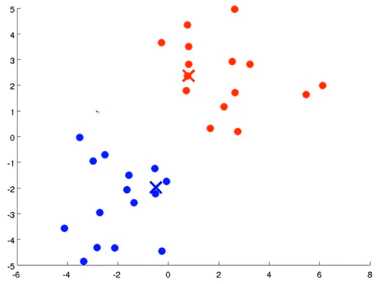
K-means算法接收两个输入,一个是 K值即聚类中簇的个数, 一个是 一系列无标签的数据,使用N维向量X表示


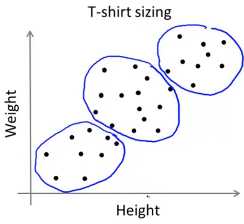
K-均值算法也可以很便利地用于将数据分为许多不同组,即使在没有非常明显区分的组群的情况下也可以。下图所示的数据集包含身高和体重两项特征构成的,利用 K-均值算法将数据分为三类,用于帮助确定将要生产的 T-恤衫的三种尺寸。
根据以上定义:则\(\mu_{c^{(i)}}\) 表示样本\(x^{(i)}\)所属簇的中心的 位置坐标
损失函数为 每个样本到其所属簇的中心的距离和的平均值 ,优化函数的输入参数为 每个样本所属的簇的编号\(c^{(i)}\)和每个簇中心的坐标\(\mu_{k}\) 这两个都是在聚类过程中不断变化的变量。此代价函数也被称为 畸变函数(Distortion function)
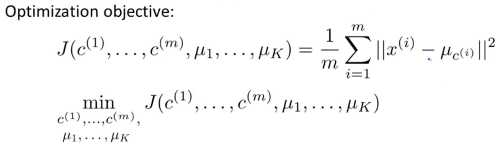
对于K-means算法中的 移动聚类中心(将聚类中心移动到分配样本簇的平均值处) ,即在\(c^{(1)},c^{(2)},c^{(3)},...c^{(m)}\)固定的条件下调整 \(\mu_1,\mu_2,\mu_3,\mu_4...\mu_K\)的值以使损失函数的值最小。


随机选择 K 个训练实例,然后令 K 个聚类中心分别与这 K 个训练实例相等
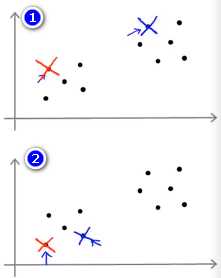
K-均值的一个问题在于,它有可能会停留在一个局部最小值处,而这取决于初始化的情况。
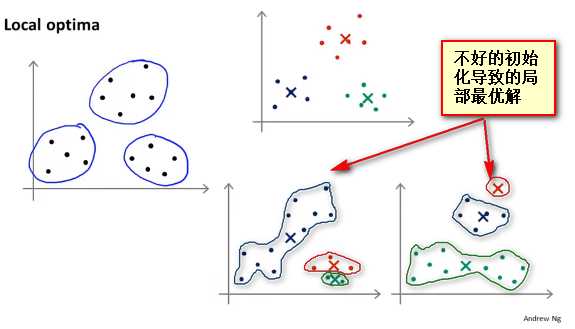
这种方法在 K 较小的时候(2--10)还是可行的,但是如果 K 较大,这么做也可能不会有明显地改善。(不同初始化方式得到的结果趋于一致)
没有所谓最好的选择聚类数的方法,通常是需要根据不同的问题,人工进行选择的。选择的时候思考我们运用 K-均值算法聚类的动机是什么,然后选择能最好服务于该目的标聚类数。
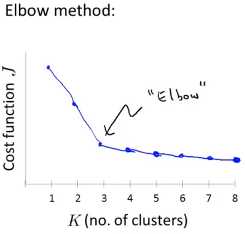
但是也有损失函数随着K的增大平缓下降的例子,此时通过肘部法则选择K的值就不是一个很有效的方法了(下图中的拐点不明显,k=3,4,5有类似的功能)
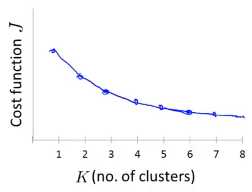
通常K均值聚类是为下一步操作做准备,例如:市场分割,社交网络分析,网络集群优化 ,下一步的操作都能给你一些评价指标,那么决定聚类的数量更好的方式是:看哪个聚类数量能更好的应用于后续目的
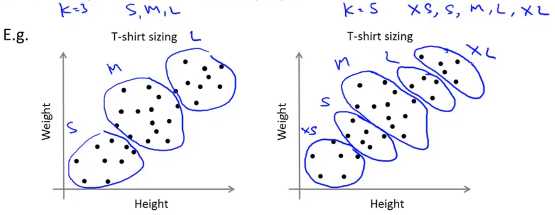
例如对于T恤衫的尺码进行聚类的方法,如左图将其聚为3类(S,M,L),右图将其聚为5类(XS,S,M,L,XL)进行表示,这两种聚类都是可行的,我们可以 根据聚类后用户的满意程度或者是市场的销售额来决定最终的聚类数量
原文:https://www.cnblogs.com/cloud-ken/p/9610614.html