要求0:
作业地址:【https://edu.cnblogs.com/campus/nenu/2016CS/homework/2110】
要求1:
git仓库地址:https://git.coding.net/hero_HR/wf.git
要求2:
|
功能模块 |
具体阶段 |
预计时间(min) |
实际时间(min) |
|
功能1 |
具体设计 具体编码 测试完善 |
30 240 30 |
40 300 35 |
|
功能2 |
具体设计 具体编码 测试完善 |
35 200 30 |
∞ ∞ ∞ |
|
功能3 |
具体设计 具体编码 测试完善 |
40 200 35
|
∞ ∞ ∞
|
|
PSP2.1 |
任务内容 |
预估耗时(min) |
实际耗时(min) |
|
Planning |
计划 |
30 |
50 |
|
Estimate |
估计这个任务需要多少时间,并规划大致工作步骤 |
30 |
50 |
|
Development |
开发 |
1000 |
1035 |
|
Analysis |
需求分析 (包括学习新技术) |
60 |
65 |
|
Design Spec |
生成设计文档 |
45 |
50 |
|
Design Review |
设计复审 (和同事审核设计文档) |
0 |
0 |
|
Coding Standard |
代码规范 (为目前的开发制定合适的规范) |
30 |
50 |
|
Design |
具体设计 |
90 |
103 |
|
Coding |
具体编码 |
360 |
380 |
|
Code Review |
代码复审 |
70 |
80 |
|
Test |
测试(自我测试,修改代码,提交修改) |
130 |
150 |
|
Reporting |
报告 |
210 |
240 |
|
Test Report |
测试报告 |
120 |
140 |
|
Size Measurement |
计算工作量 |
45 |
45 |
|
Postmortem & Process Improvement Plan |
事后总结, 提出过程改进计划 |
45 |
55 |
预估耗时和实际耗时的差距原因:
1.大一大二训练的太少,第一次接触这种作业导致花费了一定的时间才大体搞明白题目的意思
2.基础薄弱,查资料翻书花费了大量的时间
要求3:
1.解题思路
拿到题目后,反反复复看了几遍,大体有了一个思路,先用要求的种种方式将文本文件读入,然后统计其中不重复的单词的数量,最终输出结果。看起来感觉很简单,但是对于一个没有什么编程实战经验而且只会C语言的菜鸡来说具体实现起来还是存在很答问题的。三个功能难度依次增大,功能一是基础,然后功能二三在功能一的基础之上再做改进即可。刚开始着手解决功能一时就遇到了很大的问题,如何将文本文件中的内容读入。既然不会就去学,但是在网上找了很久发现基本都是用非c语言编写的,又双叒叕看不懂了.......唉,算了,想了想还是从基础开始吧,找了一个和c更为相近一些的c++语言开始学习。嗯,现在也就学了三四天,很多东西还是不会,只是能大概的看懂一些框架。以后我会继续学习的。至于下面的代码,大多都是从网上或者书上找来的,想通过它们学习更多c++的相关知识。如果老师时间有限的话,就不用在这些程序上浪费太多的时间了!
2.代码
功能1:统计文件中不重复的单词数量
重难点:功能一的实现上主要的就在于文件的读入以及统计不重复单词的数量。用fgets()将文本文件逐行读入,然后通过循环条件语句累计文件中不重复单词的数量以及每个单词出现的次数。
代码片段:
int main() { int i=0,n=0; char a[100],text[1024]; FILE *fp; map<string,int>lea; fp=fopen("d:\\input.txt","r"); while(fgets(text,1024,fp)!=NULL) //逐行读入文本文件的内容 { while(text[i]!=‘\0‘) { int j=0; char a[30]; while((text[i]>=‘a‘&&text[i]<=‘z‘)||(text[i]>=‘A‘&&text[i]<=‘Z‘)) { if(text[i]>=‘A‘&&text[i]<=‘Z‘) text[i]+=‘a‘-‘A‘; a[j++]=text[i++]; } a[j]=‘\0‘; if(lea[a]==0) n++; lea[a]++; if(text[i]==‘\0‘) break; else i++; } } fclose(fp);
样例测试:
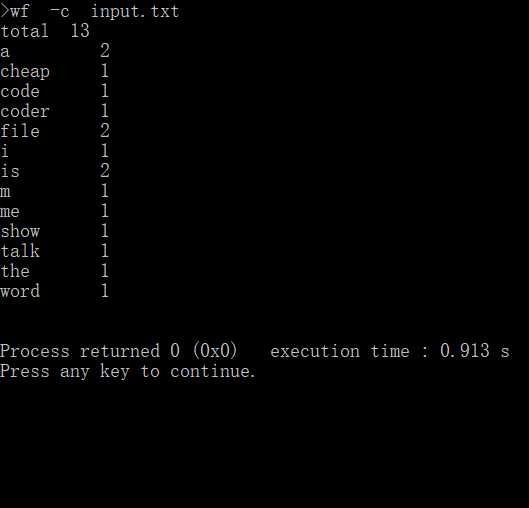
功能2:指定文件目录,统计文件名称按照字典序最靠前的文本文件中不重复的单词数量
重难点:得到某文件夹下的所有文件并且按要求找到指定文本文件
代码片段:
#include <stdio.h> #include <io.h> const char *to_search="E:\\code\\*.txt"; //欲查找的文件,支持通配符 int main() { long handle; struct _finddata_t fileinfo; //文件信息的结构体 handle=_findfirst(to_search,&fileinfo); //第一次查找 if(-1==handle)return -1; printf("%s\n",fileinfo.name); //打印出找到的文件的文件名 while(!_findnext(handle,&fileinfo)) //循环查找其他符合的文件,知道找不到其他的为止 { printf("%s\n",fileinfo.name); } _findclose(handle); system("pause"); return 0; }
样例测试:本来以为在网上了解了怎样获取某文件夹下的所有文件的方法,然后返回字典序最靠前的文本文件的内容,再使用功能一就可以实现功能二了,但是现实很骨感........
功能3:输出出现次数最多的前N个单词
重难点:对出现单词的次数进行排序
代码片段:样例测试:功能二没实现,所以这部分更遥不可及了
3.解决项目的心路历程与收获
心路历程就是由开始见到题目时的迷茫到慢慢乐观的想也许认真研究研究就能有所收获,结果研究到后来开始质疑自己这两年的大学时间究竟学到了什么甚至于怀疑自己当初不转专业是不是一个错误的决定。收获嘛,就是认清了现实,不是吃这碗饭的料,虽然很早之前就知道了这一点,所以也就只是很重理论,轻实践。不过在以后的学习中,我会尽自己最大的努力锻炼自己的实践能力。
原文:https://www.cnblogs.com/yuetj/p/9655714.html