此作业的要求参见[https://edu.cnblogs.com/campus/nenu/2018fall/homework/2126
为完成本次作业首先尝试了java,但是因为不会解决绝对路径和相对路径问题,只能统计已经在代码中预设好的路径中的文件的单词出现的频率,所以放弃了java语言。尔后选择了C++语言,但是只能完成部分功能;最后选择使用了C语言来进行完成。
(一)功能一
1.功能
小文件输入。 为表明程序能跑,结果真实而不是迫害老五,请他亲自键盘在控制台下输入命令。
2.重点/难点
我认为首先是文件读取既是难点也是重点:难点:因为最开始选用的是Java语言,都是把路径在程序中预设好,不能做到随意访问,且文件读取直接关系到后面的功能可不可以实现,所以我认为文件读取既是难点也是重点。
其次我觉得难点是计算总的词数时,多次重复的单词的频度记为1,因为这段代码在解决的时候也是想了很久才想到解决办法,所以我认为计算总词是一个难点。
3.重要代码片断
(1)定义单词-频率结构体
typedef struct{ char name[100]//单词 int freq;//频率
}WordFreq;
(2)读取文件
char * readFile(char * path){ FILE * fp; long len; char *buf; fp = fopen(path, "r"); fseek(fp, 0, SEEK_END); len = ftell(fp); //文件长度,作为分配文件长度大小的内存空间 fseek(fp, 0, SEEK_SET); buf = (char *) malloc(sizeof (char)*(len + 1)); // 分配文件长度大小的内存空间 fread(buf, sizeof (char), len, fp); buf[len] = ‘\0‘; //以0作为字符串buf的结尾 fclose(fp); return buf;}
(3)统计单词频率
for (i = 0; i < wfIndex; i++) { // 如果该单词在wf中存在,则该单词的频率+1 if (strcmp(wf[i].name, result) == 0) { wf[i].freq++; break;}} // 如果该单词在wf中不存在,则在wf中添加该单词的记录 if (i == wfIndex) { strcpy(wf[wfIndex].name, result); wf[wfIndex].freq = 1; wfIndex++;}
(4)冒泡排序
for (i = 0; i < wfIndex; i++){ for (j = 0; j < wfIndex - i - 1; j++){ if (wf[j].freq < wf[j + 1].freq){ wf1 = wf[j]; wf[j] = wf[j + 1]; wf[j + 1] = wf1;}}}
(5)计算总数
total = 0; for (i = 0; i < wfLen; i++){ total += 1;}
4.执行效果截图:

5.得意、突破、困难的地方
(1)得意的地方:无,因为我认为这些都是比较基础的东西,而且由于最开始语言选择不太好,且对基础知识的掌握还不够好,所以不仅导致自己一直在读取文件的地方打转还导致自己在后面功能的实现上也存在很大困难。
(2)突破的地方:首先相对于最开始使用java语言解决不了相对路径的问题,在C语言这里可以完成了;而且可以成功使用冒泡排序我认为对于我自己来说也是有利一个很大的突破。
(3)困难的地方:计算总的词数我认为是困难的地方,就像上面重点/难点中提到的重复多次的词语的频度在总词数中记为1,也是经过了很多思考最后选择通过for()循环解决。
(二)功能二
1.功能
支持命令行输入英文作品的文件名,请老五亲自录入。
2.重点/难点
我认为功能二的重点和难点都是如何将进行命令行输入这个功能实现,因为在这之前因为自己联系不够,没有见到过这类要求,需要查一些资料并需要尝试实践,且这个功能关系到整个功能的实现,所以我认为进行命令输入是整个功能的难点和重点。
3.重要代码片断
(1)命令行输入
int main(int argc, char *argv[]){ char * path; char * buf; int i, total; WordFreq wf[1000]; int wfLen; path = argv[argc - 1]; //读取文件名字 buf = readFile(path); //读取文件 statics(buf, wf, &wfLen); //统计单词频率 total = 0; for (i = 0; i < wfLen; i++){ total += 1;} printf("total\t%d\n\n", total); //输出总单词个数 for (i = 0; i < wfLen; i++){ printf("%-20s\t%d\n", wf[i].name, wf[i].freq); } return 0;}
4.执行效果截图:

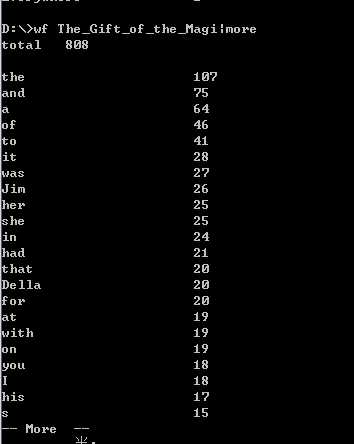
5.得意、突破、困难的地方
(1)得意的地方:同功能一的观点一致,我觉得我也是因为自己见到的东西太少,所以导致很多问题没见到过,或者知道某些问题但是没有实践过,所以我觉得没有我觉得我可以得意的地方
(2)突破的地方:之前没有见过用命令行提示进行输入的问题,所以我觉得自己在这个问题上有了0的突破,且通过功能二也学会了一些命令行的操作(如:使用|more命令只允许输出显示一屏幕)。
(3)困难的地方:我觉得遇到自己没见过的知识点并需要自己进行解决是困难的地方,因为最开始的时候都不知道应该Google什么,发现自己对专业知识的掌握不牢固且自学能力需要大大加强。
(三)功能三
1.功能
支持命令行输入存储有英文作品文件的目录名,批量统计。
2.重点/难点
我认为重点难点是根据目录名实现批量统计。
3.重要代码片断
for(i=0; i<10; i++) printf("%s出现次数为:%d\n",A[i].str,A[i].num);
4.执行效果截图:
5.得意、突破、困难的地方
(1)得意的地方:虽然进行了尝试,但是没有实现,所以没有可以得意的地方。
(2)突破的地方:虽然进行了尝试,但是没有实现,所以没有觉得有突破的地方。
(3)困难的地方:自己能力太差,虽尝试进行,但没有在规定时间内解决这个功能点,这就是我遇到的困难的地方。
(四)功能四
1.功能
从控制台读入英文单篇作品,这不是为了打脸老五,而是为了向你女朋友炫酷,表明你能提供更适合嵌入脚本中的作品(或者如她所说,不过是更灵活的接口)。如果读不懂需求,请教师兄师姐,或者 bing: linux 重定向,尽管这个功能在windows下也有,搜索关键词中加入linux有利于迅速找到。
2.重点/难点
我认为重点难点是提供更适合嵌入脚本中的程序,根据google,程序执行的时候,在命令行窗口下使用重定向来指定将输出重定向到一个文件,例:当文件名为test.exe时,执行test.ext > essayct.txt.
3.重要代码片断
freopen {"input.txt","r",stdin};
freopen {"output.txt","w",stdout};
4.执行效果截图:
5.得意、突破、困难的地方
(1)得意的地方:因为没有实现,所以没有可以得意的地方。
(2)突破的地方:因为没有实现,所以没有觉得有突破的地方。
(3)困难的地方:自己能力太差,没有在规定时间内解决这个功能点,这就是我遇到的困难的地方。
(五)PSP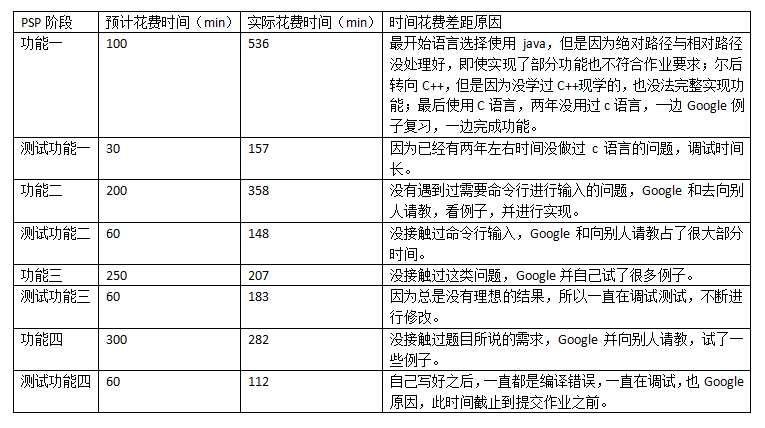
(六)代码及版本控制
https://coding.net/u/MiaYike/p/WordCount/git
原文:https://www.cnblogs.com/wangyike/p/9696411.html