小说词频统计:
代码:
1 # usr/bin/env/python 2 # -*- coding:utf-8 -*- 3 4 import jieba 5 import jieba.posseg as psg 6 7 with open("NotTrustAnyone.txt", ‘r‘) as f: 8 NotTrustAnyone = f.read() 9 10 # 去掉非汉字的字符 11 for ch in NotTrustAnyone: 12 if ch.isalpha() is False: 13 NotTrustAnyone = NotTrustAnyone.replace(ch, "") 14 15 16 # 分词并转成一个列表 17 NotTrustAnyOneList = [x.word for x in psg.cut(NotTrustAnyone) if x.flag.startswith(‘n‘)] 18 19 # 词频统计,用字典保存,并按出现次数降序排序 20 mySet = set(NotTrustAnyOneList) 21 22 keyList = [] 23 valueList = [] 24 25 for word in mySet: 26 keyList.append(word) 27 valueList.append(NotTrustAnyOneList.count(word)) 28 29 wordCount = dict(zip(keyList, valueList)) 30 31 # 字典排序函数(并取top20): 32 33 34 def sortDict(myDict): 35 tempList = list() 36 for i in myDict.items(): 37 tempList.append(i) 38 tempList.sort(key=lambda x: x[1], reverse=True) 39 myDict = dict(tempList[0:21]) 40 return myDict 41 42 43 wordCount = sortDict(wordCount) 44 45 # 输出 46 print(" 单词 出现次数".center(13)) 47 for word in wordCount.keys(): 48 print(word.center(13), wordCount[word])
截图(Top20):
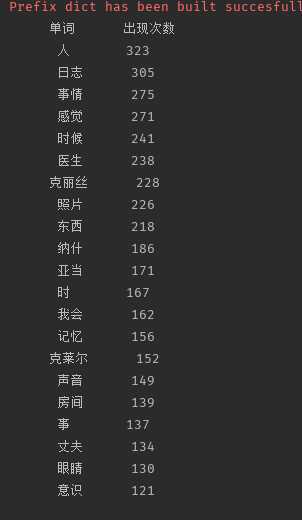
英文歌曲频次统计:
代码:
with open("HallOfFame.txt", ‘r‘) as f: HallOfFame = f.read().lower() # 去除标点符号,并按行分隔 sep = ",.!、!@#$%^‘" for ch in sep: HallOfFame = HallOfFame.replace(ch, "") HallOfFameList = HallOfFame.split("\n") # 对每行用空格分隔 temp = [] for i in HallOfFameList: temp.extend(i.split(" ")) HallOfFameList = list(x for x in temp if x != ‘‘) print(HallOfFameList) # 词频统计,用字典保存,并按出现次数降序排序 mySet = set(HallOfFameList) keyList = [] valueList = [] for word in mySet: keyList.append(word) valueList.append(HallOfFameList.count(word)) wordCount = dict(zip(keyList, valueList)) # 字典排序函数(并取top20): def sortDict(myDict): tempList = list() for i in myDict.items(): tempList.append(i) tempList.sort(key=lambda x:x[1], reverse=True) myDict = dict(tempList[0:21]) return myDict wordCount = sortDict(wordCount) # 输出 print(" 单词 出现次数".center(13)) for word in wordCount.keys(): print(word.center(13),wordCount[word])
截图(Top20):
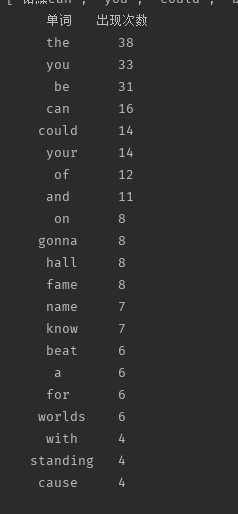
歌曲和小说文件见附件1
原文:https://www.cnblogs.com/traces2018/p/9712527.html