1、英文歌词词频统计:
读取文件、提取字符串、文件预处理
#读取文件 f=open(‘enwords.txt‘,‘r‘,encoding=‘utf-8‘) Str_some=f.read() f.close() print(Str_some) #对文件进行预处理 #把全部的字母变成小写 Str_some=Str_some.lower() print(Str_some) #标点符号以及特殊符号的处理 s1=‘‘‘. , = ? ‘ ‘‘‘ for i in s1: Str_some=Str_some.replace(i,‘ ‘) print(Str_some)

提取分词单词list
##提取单词变成list Str_list=Str_some.split() print(len(Str_list),Str_list)

单词计算字典set、dict
#把单词变成集合的形式 Str_set=set(Str_list) print(len(Str_set),Str_set) #变成字典形式 StrDict={} for word in Str_set: StrDict[word]=Str_list.count(word) print(len(StrDict),StrDict)

按词频排序
#按词频排序 S_list=list(StrDict.items()) print(S_list) S_list.sort(key=lambda x:x[1],reverse=True) print(S_list)

排除语法词汇,输出top20
##按词频排序 S_list=list(StrDict.items()) # print(S_list) S_list.sort(key=lambda x:x[1],reverse=True) # print(S_list) ###排除语法词汇的定冠词 Str_set=set(Str_list) exclude={‘a‘,‘the‘,‘and‘,‘i‘,‘you‘,‘it‘} print(Str_set-exclude) ##输出Top20 for i in range(20): print(S_list[i])
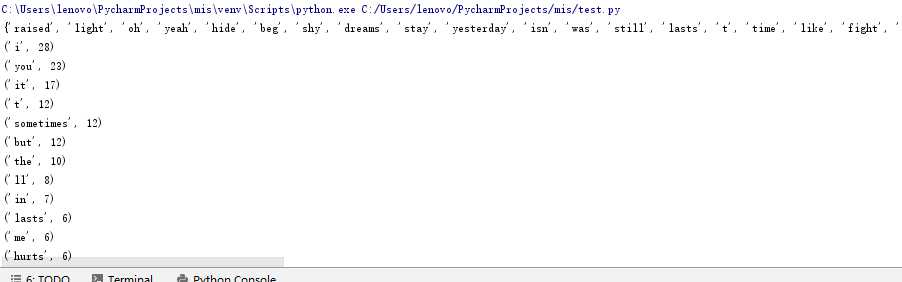
中文小说词频计数:
#读取文件 f1=open(‘zhongwen.txt‘,‘r‘,encoding=‘gbk‘) S1=f1.read() print(S1) f1.close()
原文:https://www.cnblogs.com/zxcv11/p/9715481.html