file = open(‘explore.txt‘, ‘a‘, encoding=‘utf-8‘) #a代表以追加的方式写入文本 file.write(‘\n‘.join([question, author, answer])) file.write(‘\n‘ + ‘=‘ * 50 + ‘\n‘) file.close()
· 一个Json对象
[{ "name": "Bob", "gender": "male", "birthday": "1992-10-18" }, { "name": "Selina", "gender": "female", "birthday": "1995-10-18" }]
data = json.loads(str) print(data) 读取json文件 with open(‘data.json‘, ‘r‘) as file: str = file.read() data = json.loads(str) print(data)
import csv with open(‘data.csv‘, ‘w‘) as csvfile: writer = csv.writer(csvfile) writer.writerow([‘id‘, ‘name‘, ‘age‘]) writer.writerows([[‘10001‘, ‘Mike‘, 20], [‘10002‘, ‘Bob‘, 22], [‘10003‘, ‘Jordan‘, 21]])
读取
import pymysql db = pymysql.connect(host=‘localhost‘,user=‘root‘, password=‘123456‘, port=3306) #connect()方法声明一个连接对象 cursor = db.cursor() sql = ‘‘ try: cursor.execute(sql, (id, user, age)) db.commit() except: db.rollback() #事务回滚,保证数据一致性 db.close()
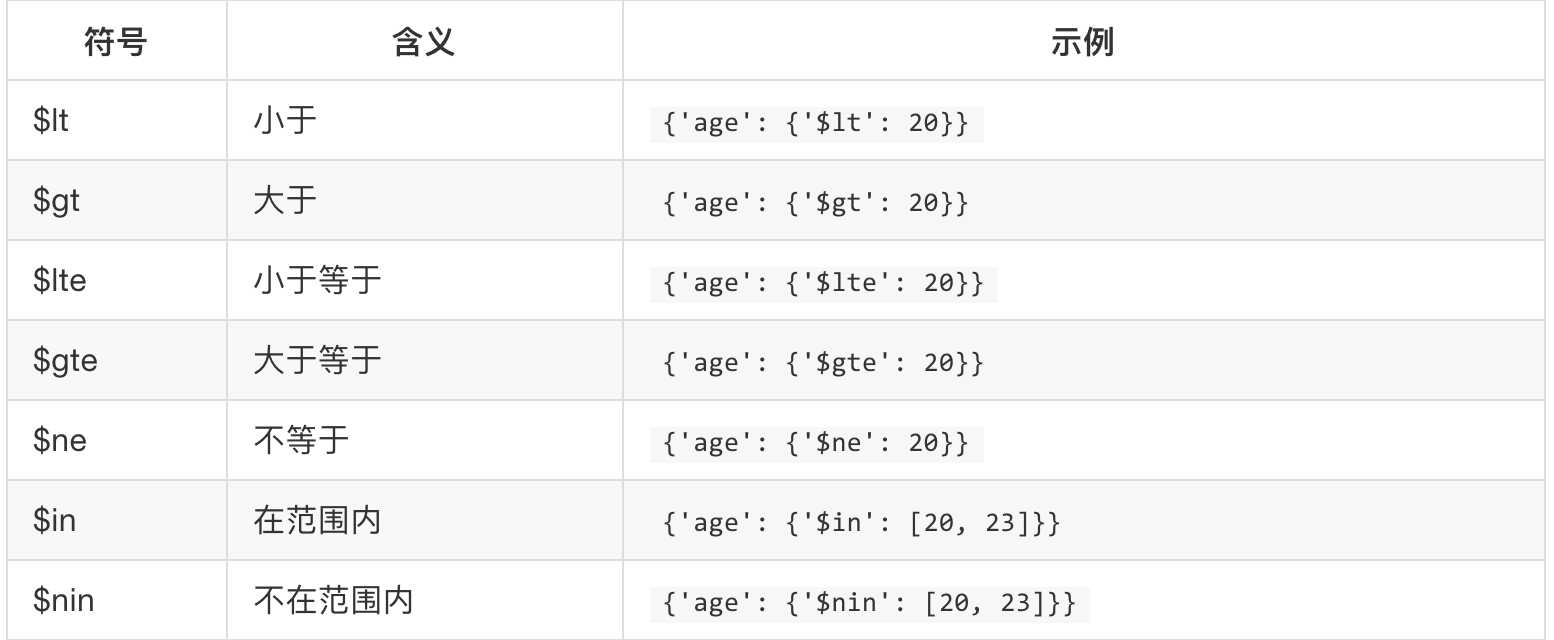
关系型数据库属性:



##本系列内容为《python3爬虫开发实战》学习笔记。本系列博客列表如下:
持续更新...
对应代码请见:..
原文:https://www.cnblogs.com/geo-will/p/9717311.html