这学期选了门模式识别的课。发现最常见的一种情况就是,书上写的老师ppt上写的都看不懂,然后绕了一大圈去自己查资料理解,回头看看发现,Ah-ha,原来本质的原理那么简单,自己一開始仅仅只是被那些看似formidable的细节吓到了。所以在这里把自己所学的一些点记录下来,供备忘,也供參考。
1. K-Nearest Neighbor
K-NN能够说是一种最直接的用来分类未知数据的方法。基本通过以下这张图跟文字说明就能够明确K-NN是干什么的
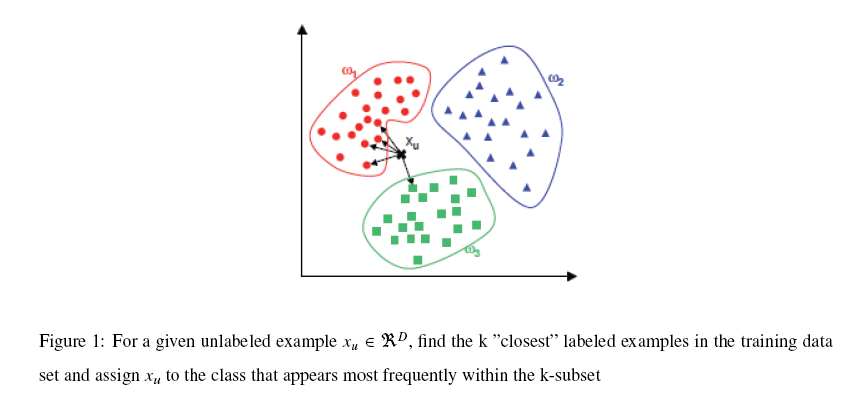
简单来说,K-NN能够看成:有那么一堆你已经知道分类的数据,然后当一个新数据进入的时候,就開始跟训练数据里的每一个点求距离,然后挑离这个训练数据近期的K个点看看这几个点属于什么类型,然后用少数服从多数的原则,给新数据归类。一个比較好的介绍k-NN的课件能够见以下链接,图文并茂,我当时一看就懂了
http://courses.cs.tamu.edu/rgutier/cs790_w02/l8.pdf
实际上K-NN本身的运算量是相当大的,由于数据的维数往往不止2维,并且训练数据库越大,所求的样本间距离就越多。就拿我们course project的人脸检測来说,输入向量的维数是1024维(32x32的图,当然我认为这样的方法比較silly),训练数据有上千个,所以每次求距离(这里用的是欧式距离,就是我们最经常使用的平方和开根号求距法) 这样每一个点的归类都要花上上百万次的计算。所以如今比較经常使用的一种方法就是kd-tree。也就是把整个输入空间划分成非常多非常多小子区域,然后依据临近的原则把它们组织为树形结构。然后搜索近期K个点的时候就不用全盘比較而仅仅要比較临近几个子区域的训练数据即可了。kd-tree的一个比較好的课件能够见以下链接:
http://www.inf.ed.ac.uk/teaching/courses/inf2b/learnnotes/inf2b-learn06-lec.pdf

http://www.math.ucsd.edu/~gptesler/283/pca_07-handout.pdf
4. Linear Discriminant Analysis
LDA,基本和PCA是一对双生子,它们之间的差别就是PCA是一种unsupervised的映射方法而LDA是一种supervised映射方法,这一点能够从下图中一个2D的样例简单看出

图的左边是PCA,它所作的仅仅是将整组数据总体映射到最方便表示这组数据的坐标轴上,映射时没有利用不论什么数据内部的分类信息。因此,尽管做了PCA后,整组数据在表示上更加方便(降低了维数并将信息损失降到最低),但在分类上或许会变得更加困难;图的右边是LDA,能够明显看出,在添加了分类信息之后,两组输入映射到了另外一个坐标轴上,有了这样一个映射,两组数据之间的就变得更易区分了(在低维上就能够区分,降低了非常大的运算量)。
在实际应用中,最经常使用的一种LDA方法叫作Fisher Linear Discriminant,其简要原理就是求取一个线性变换,是的样本数据中“between classes scatter matrix”(不同类数据间的协方差矩阵)和“within classes scatter matrix”(同一类数据内部的各个数据间协方差矩阵)之比的达到最大。关于Fisher LDA更详细的内容能够见以下课件,写的非常不错~
http://www.csd.uwo.ca/~olga/Courses//CS434a_541a//Lecture8.pdf
5. Non-negative Matrix Factorization
NMF,中文译为非负矩阵分解。一篇比較不错的NMF中文介绍文能够见以下一篇博文的链接,《非负矩阵分解:数学的奇异力量》
http://chnfyn.blog.163.com/blog/static/26954632200751625243295/
这篇博文非常大概地介绍了一下NMF的来龙去脉(当然里面那幅图是错的。。。),当然假设你想更深入地了解NMF的话,能够參考Lee和Seung当年发表在Nature上面的NMF原文,"Learning the parts of objects by non-negative matrix factorization"
http://www.seas.upenn.edu/~ddlee/Papers/nmf.pdf
读了这篇论文,基本其它不论什么介绍NMF基本方法的材料都是浮云了。
NMF,简而言之,就是给定一个非负矩阵V,我们寻找另外两个非负矩阵W和H来分解它,使得后W和H的乘积是V。论文中所提到的最简单的方法,就是依据最小化||V-WH||的要求,通过Gradient Discent推导出一个update rule,然后再对当中的每一个元素进行迭代,最后得到最小值,详细的update rule见下图,注意当中Wia等带下标的符号表示的是矩阵里的元素,而非代表整个矩阵,当年在这个上面绕了好久。。
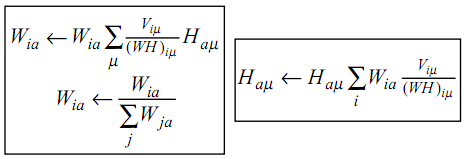
当然上面所提的方法仅仅是当中一种而已,在http://spinner.cofc.edu/~langvillea/NISS-NMF.pdf中有很多其它具体方法的介绍。
相比于PCA、LDA,NMF有个明显的优点就是它的非负,由于为在非常多情况下带有负号的运算算起来都不这么方便,可是它也有一个问题就是NMF分解出来的结果不像PCA和LDA一样是恒定的。
6. Gaussian Mixture Model
GMM高斯混合模型粗看上去跟上文所提的贝叶斯分类器有点相似,但两者的方法有非常大的不同。在贝叶斯分类器中,我们已经事先知道了训练数据(training set)的分类信息,因此仅仅要依据相应的均值和协方差矩阵拟合一个高斯分布就可以。而在GMM中,我们除了数据的信息,对数据的分类一无所知,因此,在运算时我们不仅须要估算每一个数据的分类,还要估算这些估算后数据分类的均值和协方差矩阵。。。也就是说假设有1000个训练数据10租分类的话,须要求的未知数是1000+10+10(用未知数表示未必确切,确切的说是1000个1x10标志向量,10个与训练数据同维的平均向量,10个与训练数据同维的方阵)。。。反正想想都是非常头大的事情。。。那么这个问题是怎么解决的呢?
这里用的是一种叫EM迭代的方法。
详细用法能够參考http://neural.cs.nthu.edu.tw/jang/books/dcpr/doc/08gmm.pdf 这份台湾清华大学的课件,写的真是相当的赞,实现代码的话能够參考:
1. 倩倩的博客http://www.cnblogs.com/jill_new/archive/2010/12/01/1893851.html 和
2. http://www.cs.ru.nl/~ali/EM.m
当然 Matlab里一般也会自带GMM工具箱,其使用方法能够參考以下链接:
http://www.mathworks.com/help/toolbox/stats/gmdistribution.fit.html
几种常见模式识别算法整理和总结,布布扣,bubuko.com
原文:http://www.cnblogs.com/mengfanrong/p/3871739.html