(1)读文件到缓冲区
def process_file(dst): # 读文件到缓冲区 try: # 打开文件 txt = open(dst, ‘r‘) except IOError as s: print(s) return None try: # 读文件到缓冲区 bvffer = txt.read() except: print("Read File Error!") return None txt.close() return bvffer
(2)处理缓冲区代码,统计每个单词的频率并存放在字典中
def process_buffer(bvffer): if bvffer: word_freq = {} #下面添加处理缓冲区 bvffer代码,统计每个单词的频率,存放在字典word_freq bvffer = bvffer.lower() #把文本中大写字母转换为小写 for ch in ‘!"#$%&()*+-,-./:;<=>?@“”[\\]^_{|}~‘: # 替换文本中特殊字符为空格 bvffer = bvffer.replace(ch, " ") words = bvffer.split() #分割字符串 for word in words: word_freq[word] = word_freq.get(word, 0) + 1 return word_freq
(3)将处理好的缓冲区代码按词频排序,输出词频Top10 的单词
def output_result(word_freq): if word_freq: sorted_word_freq = sorted(word_freq.items(), key=lambda v: v[1], reverse=True) #以第二列记录v[1]即词频排序 for item in sorted_word_freq[:10]: # 以单词+词频数格式输出Top 10 的单词 print("{0:<10}{1:>5}".format(item[0],item[1]))
(4)设立一个测试函数,运用之前所设的函数功能,导入文本测试
def main(): parser = argparse.ArgumentParser() parser.add_argument(‘dst‘) args = parser.parse_args() dst = args.dst bvffer = process_file(dst) word_freq = process_buffer(bvffer) output_result(word_freq)
(5)在主函数中增加简单功能分析,对该词频统计进行性能评估
if __name__ == "__main__": cProfile.run("main()", filename="result.out") # 把分析结果保存到文件中,增加排序方式 p = pstats.Stats(‘result.out‘) # 创建Stats对象 p.sort_stats(‘calls‘).print_stats(10) # 按照调用次数排序,打印前10函数的信息 p.strip_dirs().sort_stats("cumulative", "name").print_stats(10) # 按照运行时间和函数名排序,只打印前10行函数的信息 p.print_callers(0.5, "process_file") # 想知道有哪些函数调用了process_file() p.print_callers(0.5, "process_buffer") p.print_callers(0.5, "output_result") p.print_callees("process_buffer") # 查看process_buffer()函数中调用了哪些函数
使用4个空格进行缩进,不可使用Tab,也不要tab和空格混用
try: # 打开文件 txt = open(dst, ‘r‘)
(1)对Gone_with_the_wind.txt的词频测试
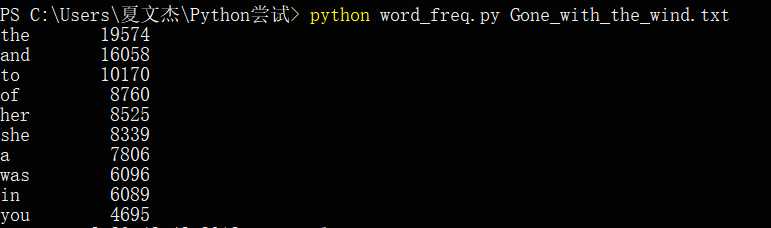
(2)对A_Tale_of_Two_Cities.txt的词频测试
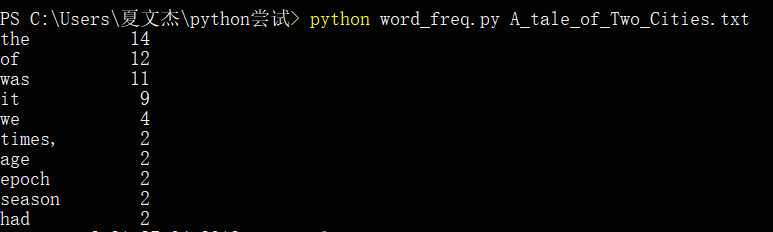
(仅对大文本Gone_with_the_wind.txt进行分析)
1.性能分析
(1)总运行时间

(2)调用次数最多的10个函数
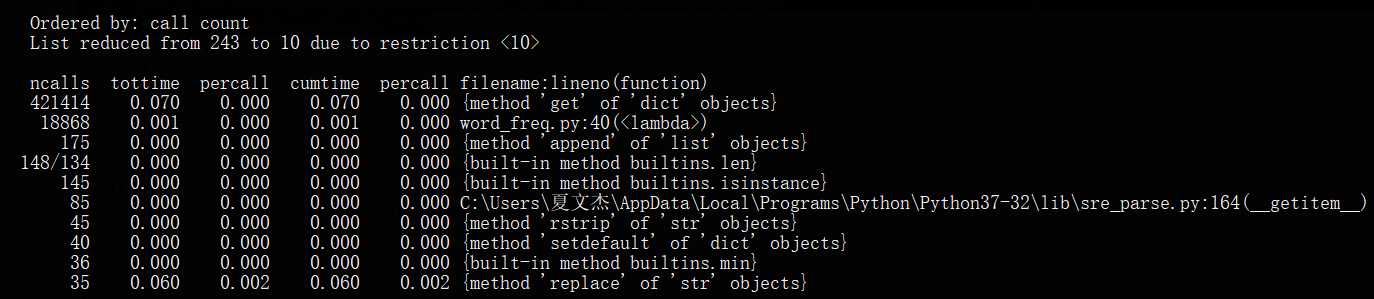
(3)执行时间最长的10个函数
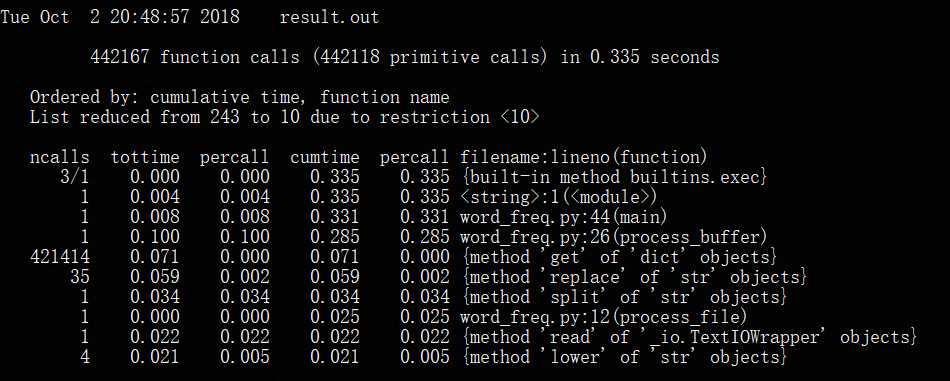
(4)分别查看三个函数耗时
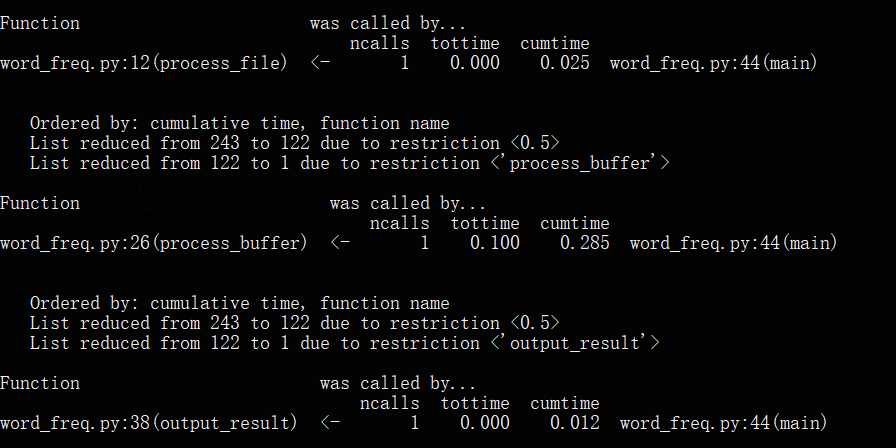
(5)根据分别查看的函数执行时间,找到耗时最长的函数,再继续查看其中调用最多的方法

2.代码改进
由上述性能分析可知,词频统计中调用次数最多也是耗时最长的是对字典类型的get方法,其次就是对特殊字符的替换replace和字符串的分割split以及字母大小写转换,于是便考虑将process_buffer()中有关特殊字符的替换和字母大小写转换的代码注释掉。
def process_buffer(bvffer): if bvffer: word_freq = {} #下面添加处理缓冲区 bvffer代码,统计每个单词的频率,存放在字典word_freq # bvffer = bvffer.lower() #把文本中大写字母转换为小写 # for ch in ‘!"#$%&()*+-,-./:;<=>?@“”[\\]^_{|}~‘: # 替换文本中特殊字符为空格 # bvffer = bvffer.replace(ch, " ") words = bvffer.split() #分割字符串 for word in words: word_freq[word] = word_freq.get(word, 0) + 1 return word_freq
发现重新运行后,总运行时间由0.335减少到了0.264,但对词频统计的结果也产生了影响。

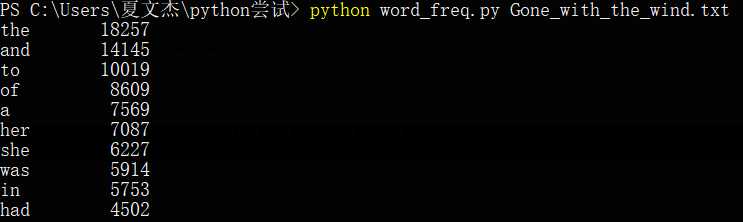
发现统计出的词频整体下降,‘a‘的出现频率超过了‘her‘、‘she‘,‘had‘取代了‘you‘成为词频Top10;其原因应该是特殊字符的替换影响到了原本的文本中的字符组成。
3.可视化操作
安装graphviz ,并把gprof2dot.py 复制到当前分析文件的路径,
执行下述步骤:
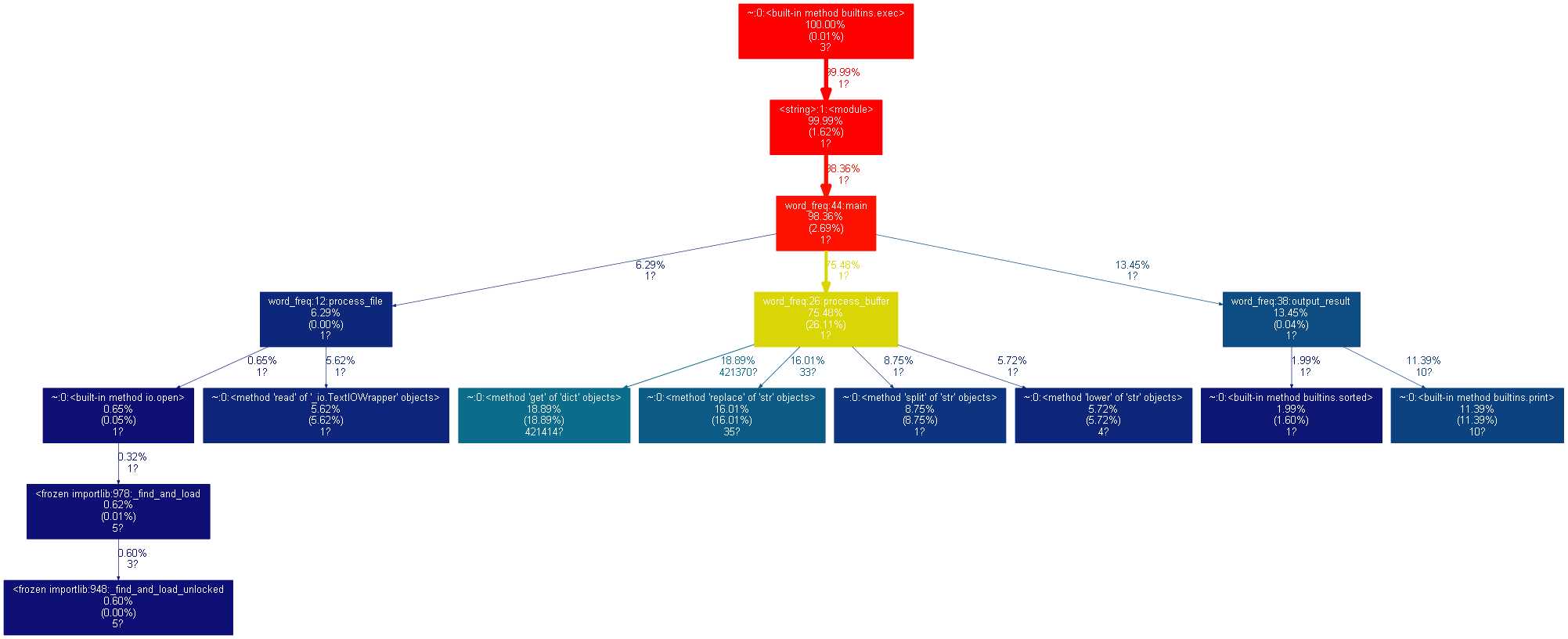
1. 性能分析:python -m cProfile -o result.out -s cumulative word_freq.py Gone_with_the_wind.txt;分析结果保存到 result.out 文件; 2. 转换为图形;gprof2dot 将 result.out 转换为 dot 格式;再由 graphvix 转换为 png 图形格式。
命令:python gprof2dot.py -f pstats result.out | dot -Tpng -o result.png
转换得到如下图:
原文:https://www.cnblogs.com/AXAXA/p/9738709.html