作业要求: https://edu.cnblogs.com/campus/nenu/2018fall/homework/2145
git地址:https://git.coding.net/zhangjy982/word_count.git
要求0
第一次运行:
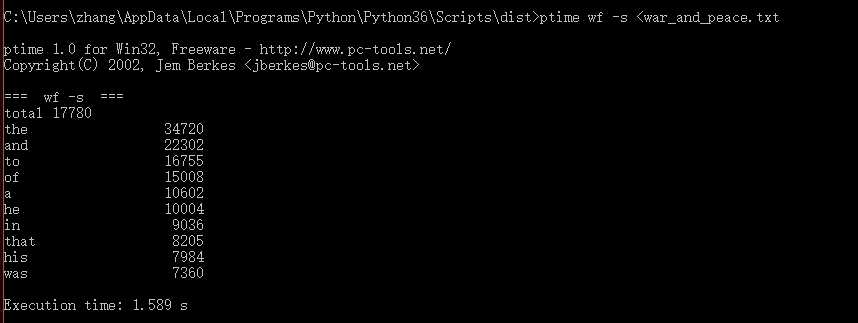
第二次运行:
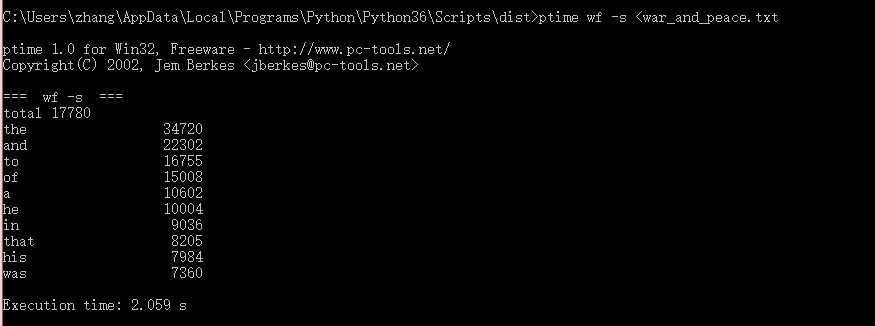
第三次运行:

| 次数 | 消耗时间(s) |
| 第一次 | 1.589 |
| 第二次 | 2.059 |
| 第三次 | 1.681 |
| 平均 | 1.776 |
要求1
我猜测程序的瓶颈是替换文章的标点对文章进行分词,也就是word_split(str)这一函数过程:
1 def words_split(str): 2 text = re.findall(r‘\w+‘,str) 8 count_dict = {} 9 for str in text: 10 if str in count_dict.keys(): 11 count_dict[str] = count_dict[str] + 1 12 else: 13 count_dict[str] = 1 14 count_list=sorted(count_dict.items(),key=lambda x:x[1],reverse=True) 15 return count_list
因为正则表达式的处理时间很慢,读取文章内容产生的字符串又非常长,所以我觉得这块应该是程序的瓶颈。根据老师课上三角函数的启发,我的优化方案是:将正则表达式更改为标点符号的替换,因为标点符号的数量有限,在文章篇幅非常长的情况下,替换的时间比正则匹配的时间要短很多。
要求2
因为我使用的编程语言是Python,所以需要使用Python的效能分析工具,我找到了关于Python效能分析的博客并学习了其中的内容,这篇博客的地址在:
http://www.cnblogs.com/xiadw/p/7455513.html
我使用了cProfile作为Python的效能分析工具,代码为:
1 python -m cProfile -s time wf.py -s < war_and_peace.txt
我得到的结果为:
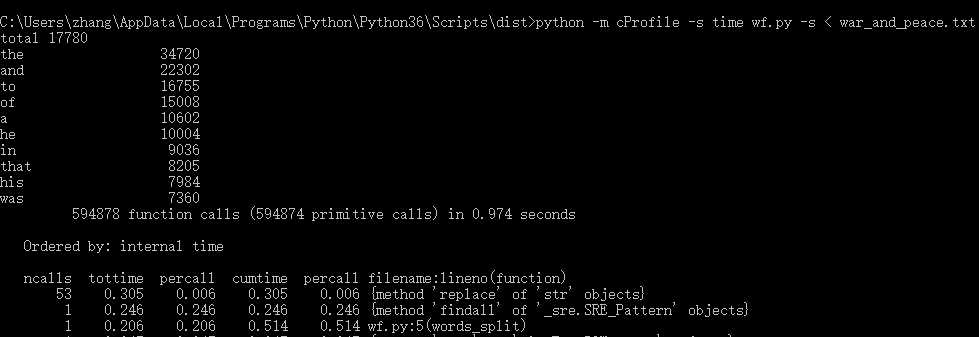
从效能分析结果上来看我的程序耗时最长的三个函数分别是:
1."replace" of "str" object,即字符串类型的替换操作;
2."findall" of "_sre.SRE_Pattern" object,即正则匹配的findall()方法;
3.words_split(),即我自己写的分词函数;
要求3
根据要求2解决中得到的结论,我发现排名第一的虽然是replace()函数,但是它执行了53次(替换文本中的乱码字符),单次的执行时间为0.305/53 = 0.005755s,而findall()函数的单次执行时间为0.246s,单次执行时间是replace的接近43倍,所以replace不是影响程序运行时间的主要因素,换句话说,也就是优化空间不大;但是正则方法就不一样了,正则方法可以转化,可以把正则方法转化为replace方法,将正则方法转化为replace函数,效果应该会有比较明显的改善;
修改后的代码:
1 def words_split(str): #正则表达式进行分词改为replace 2 text = str.replace(‘\n‘,‘ ‘).replace(‘.‘,‘ ‘).replace(‘,‘,‘ ‘). 3 replace(‘!‘,‘ ‘).replace(‘\\‘,‘ ‘).replace(‘#‘,‘ ‘). 4 replace(‘[‘,‘ ‘).replace(‘]‘,‘ ‘).replace(‘:‘,‘ ‘). 5 replace(‘?‘,‘ ‘).replace(‘-‘,‘ ‘).replace(‘\‘‘,‘ ‘). 6 replace(‘\"‘,‘ ‘).replace(‘(‘,‘ ‘).replace(‘)‘,‘ ‘). 7 replace(‘—‘,‘ ‘).replace(‘;‘,‘ ‘).lower().split() 8 count_dict = {} 9 for str in text: 10 if str in count_dict.keys(): 11 count_dict[str] = count_dict[str] + 1 12 else: 13 count_dict[str] = 1 14 count_list=sorted(count_dict.items(),key=lambda x:x[1],reverse=True) 15 return count_list
要求4
新的运行效能分析截图:

新的运行时间截图:
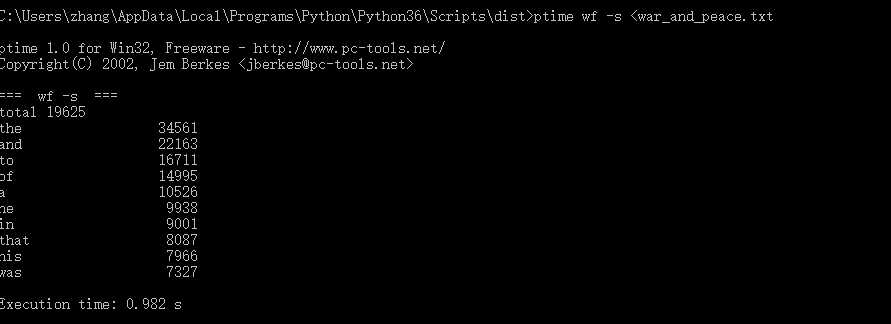
要求5
待老师测评;
原文:https://www.cnblogs.com/z1174299705/p/9745010.html